prometheus 持久化存储方案
prometheus 持久化存储方案
1. prometheus存储介绍
prometheus根目录下存在一个data目录,此目录就是prometheus的tsdb时序数据
库存放物理位置。由于prometheus集中存储到了data目录下,所以如果发生了宕机
或者物理故障,就会丢失采集的数据。鉴于此问题,prometheus并没有提供持久化
存储方案,但是给了一个API用于将数据存储到第三方存储介质中。
2.prometheus服务器中的data目录如下:
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── chunks_head
│ └── 000001
└── wal
├── 000000002
└── checkpoint.00000001
└── 00000000
prometheus 官网给出 : 对于存储可用性,建议使用RAID,对于备份,建议使用快照;使用适当的架构,可以在本地存储中保留多年的数据。
3.prometheus的配置
配置本地存储:
--storage.tsdb.path: prometheus在哪里写数据库文件,默认写到data/.--storage.tsdb.retention.time: 默认移除旧的数据,默认是15d--storage.tsdb.retention.size: 要保留的存储块的最大字节数,支持的单位 : B, KB, MB, GB, TB, PB, EB. Ex: “512MB”.--storage.tsdb.retention: 已废弃,使用--storage.tsdb.retention.time--storage.tsdb.wal-compression: 启用预写日志的压缩
4.prometheus集成Influxdb OSS版或集群版
简介: Influxdb 是一个开源的 时间序列数据库,没有外部依赖。它对于记录指标、事件和执行分析很有用。OSS版本Influxdb就是单机版,官方Influxdb Enterprise 是集群版本,官方走收费路线。庆幸的是,国内开发了OSS版本的代理版本【Influxdb cluster】,处于生产就绪状态。
4.1 Influxdb cluster的特性:
- InfluxDB Cluster 启发于 InfluxDB Enterprise、InfluxDB v1.8.10 和 InfluxDB v0.11.1,旨在替代 InfluxDB Enterprise。
- InfluxDB Cluster 易于维护,可以与上游 InfluxDB 1.x 保持实时更新。
- 内置 HTTP API,无需编写任何服务器端代码即可启动和运行。
- 数据可以被标记 tag,允许非常灵活的查询
- 类似 SQL 的查询语言。
- 集群支持开箱即用,因此处理数据可以水平扩展。集群目前处于生产就绪状态。
- 易于安装和管理,数据写入查询速度快。
- 旨在实时应答查询。这意味着每个数据点在到来时都会被计算索引,并且在 < 100 毫秒内返回的查询中立即可用。
4.2 Influxdb cluster的架构:
架构介绍:InfluxDB Cluster 安装由两组独立的进程组成:Data 节点和 Meta 节点。集群内的通信如下所示:

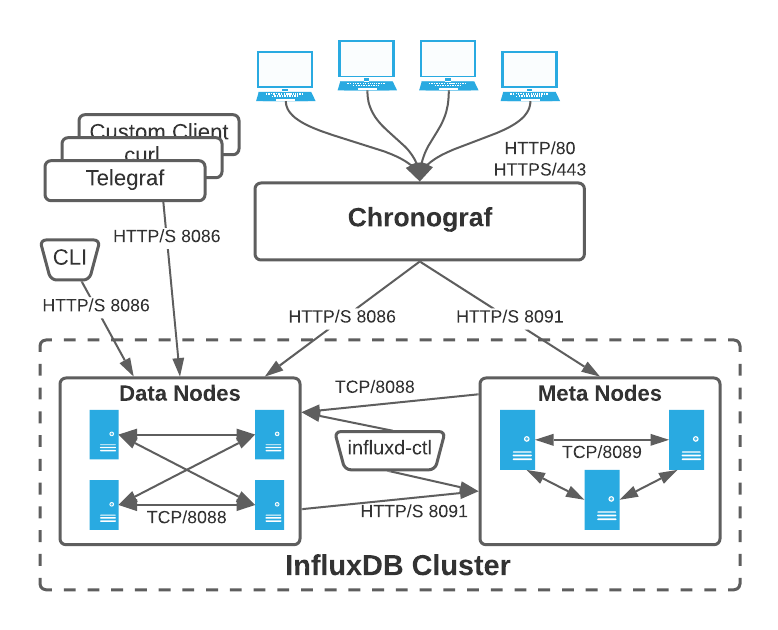
Meta 节点通过 TCP 协议和 Raft 共识协议相互通信,默认都使用端口 8089,此端口必须在 Meta 节点之间是可访问的。默认 Meta 节点还将公开绑定到端口 8091 的 HTTP API,influxd-ctl 命令使用该 API。
Data 节点通过绑定到端口 8088 的 TCP 协议相互通信。Data 节点通过绑定到 8091 的 HTTP API 与 Meta 节点通信。这些端口必须在 Meta 节点和 Data 节点之间是可访问的。
在集群内,所有 Meta 节点都必须与所有其它 Meta 节点通信。所有 Data 节点必须与所有其它 Data 节点和所有 Meta 节点通信。
5. 集群版解压目录说明:
etc
* influxdb
- influxdb.conf #配置data节点
- influxdb-meta.conf # 配置meta节点
usr
* bin
- influxd-ctl #节点管理命令
- influxd-meta # meta服务命令
- influxd #influxd数据库命令
var
6. 云原生安装使用Influxdb cluster
安装过程包含:
- meta节点安装,并将所有的meta节点添加到集群管理中
- data节点安装,并将所有的data节点添加到集群管理中
6.1 Meta 节点设置
6.1.1 设置要求:
生产环境安装过程设置三个 Meta 节点,每个 Meta 节点在自己的服务器上运行。
InfluxDB Cluster 需要 至少三个 Meta 节点 和 奇数个 Meta 节点以实现高可
用和冗余。
注 1:InfluxDB Cluster 不建议超过三个 Meta 节点,除非您的服务器之间的通信存在长期可靠性问题。
注 2:强烈建议不要在同一服务器上部署多个 Meta 节点,因为如果该特定服务器无响应,它会产生更大的潜在故障。InfluxDB Cluster 建议在占用空间相对较小的服务器上部署 Meta 节点。
注 3:要使用单个 Meta 节点启动集群,请在启动单个 Meta 节点时传递-single-server标志。
假设有三台服务器:
influxdb-meta-01,influxdb-meta-02和influxdb-meta-03。
端口: Meta 节点通过端口 8088、8089 和 8091 进行通信。
6.1.2 为每个服务器添加适当的 DNS 条目
注: 如果您只想使用 IP 地址而不是主机名,请跳过当前步骤并转到步骤
确保将服务器的主机名和 IP 地址添加到网络的 DNS 环境中。
验证步骤:
在继续安装之前,请在每台服务器上验证其他服务器是否可解析。下面是一组使用 ping 的 shell 命令示例:
ping -qc 1 influxdb-meta-01
ping -qc 1 influxdb-meta-02
ping -qc 1 influxdb-meta-03
6.1.3 编辑配置文件
在 /etc/influxdb/influxdb-meta.conf:
- 取消注释
hostname并设置为 Meta 节点的完整主机名。
hostname="influxdb-meta-0x"
注意: 如果您只想使用 IP 地址而不是主机名,必须将
hostname设置为 IP 地址。
6.1.4 启动meta服务
分别在服务器 influxdb-meta-01、influxdb-meta-02 和 influxdb-meta-03 上启动 Meta 服务
command: nohup ./usr/bin/influxd-meta -config ./etc/influxdb/influxdb-meta.conf &
6.1.5 将meta节点添加到集群管理中
在一个且仅一个 Meta 节点上,加入所有 Meta 节点,包括它自己。在我们的示例中,从
influxdb-meta-01运行:
influxd-ctl add-meta influxdb-meta-01:8091
influxd-ctl add-meta influxdb-meta-02:8091
influxd-ctl add-meta influxdb-meta-03:8091
预期输出:Added meta node x at influxdb-meta-0x:8091
验证是否添加成功:influxd-ctl show(在任何 Meta 节点上执行此命令)
预期输出:
data Nodes
==========
ID TCP Address Version
Meta Nodes
==========
ID TCP Address Version
1 influxdb-meta-01:8091 1.8.10-c1.1.2
2 influxdb-meta-02:8091 1.8.10-c1.1.2
3 influxdb-meta-03:8091 1.8.10-c1.1.2
6.2 Data 节点设置
6.2.1 设置要求
生产环境安装过程设置两个 Data 节点,每个 Data 节点在自己的服务器上运行。InfluxDB Cluster 需要 至少两个 Data 节点 才能实现高可用性和冗余。
注 1:没有要求每个 Data 节点都运行在自己的服务器上。但是,最佳实践是将每个 Data 节点部署在专用服务器上。
注 2:InfluxDB Cluster 不能用作负载均衡器。您需要配置自己的负载均衡器以将客户端流量发送到端口 8086(HTTP API 的默认端口)。
假设有两台服务器:influxdb-data-01 和 influxdb-data-02。
端口: Data 节点通过端口 8088、8089 和 8091 进行通信。
6.2.2 为每个服务器添加适当的 DNS 条目
注: 如果您只想使用 IP 地址而不是主机名,请跳过当前步骤并转到步骤 3。
确保将服务器的主机名和 IP 地址添加到网络的 DNS 环境中。
验证步骤:
```在继续安装之前,请在每台服务器上验证其他服务器是否可解析。下面是一组使用 ping 的 shell 命令示例:
ping -qc 1 influxdb-data-01
ping -qc 1 influxdb-data-02
6.2.3 编辑配置文件
在 /etc/influxdb/influxdb.conf:
- 取消注释
hostname并设置为 Data 节点的完整主机名。
hostname="influxdb-data-0x"
注意: 如果您只想使用 IP 地址而不是主机名,必须将 hostname 设置为 IP 地址。
6.2.4 启动 Data 服务
分别在服务器 influxdb-data-01 和 influxdb-data-02 上启动 Data 服务
command: nohup ./usr/bin/influxd -config ./etc/influxdb/influxdb.conf &
注: Data 节点在未被加入集群之前,出现
Failed to create storage,failed to store statistics或meta service unavailable日志是正常情况。
6.2.5 将 Data 节点加入集群
只有在添加全新节点时才应将 Data 节点加入集群,无论是在集群的初始创建期间还是在增加 Data 节点数量时。 如果您要使用
influxd-ctl update-data替换现有 Data 节点,请跳过本步骤的其余部分。
对要加入集群的每个 Data 节点运行一次且仅一次的 add-data 命令:
influxd-ctl add-data influxdb-data-01:8088
influxd-ctl add-data influxdb-data-02:8088
预期的输出是:
Added data node y at influxdb-data-0x:8088
验证步骤:
在任何 Meta 节点上发出以下命令:influxd-ctl show
预期的输出是:
Data Nodes
==========
ID TCP Address Version
4 influxdb-data-01:8088 1.8.10-c1.1.2
5 influxdb-data-02:8088 1.8.10-c1.1.2
Meta Nodes
==========
ID TCP Address Version
1 influxdb-meta-01:8091 1.8.10-c1.1.2
2 influxdb-meta-02:8091 1.8.10-c1.1.2
3 influxdb-meta-03:8091 1.8.10-c1.1.2
7.Prometheus API接口对接Influxdb
7.1 HTTP 接口
7.2 Data 节点 HTTP 接口
7.3 /query HTTP 接口
请参考: /query HTTP endpoint
7.4 /write HTTP 接口
请参考: /write HTTP endpoint
7.5 /api/v2/query HTTP 接口
请参考: /api/v2/query HTTP endpoint
7.6 /api/v2/write HTTP 接口
请参考: /api/v2/write HTTP endpoint