机器学习之求解无约束最优化问题方法(手推公式版)
文章目录
-
- 前言
- 1. 基础知识
-
- 1.1 方向导数
- 1.2 梯度
- 1.3 方向导数与梯度的关系
- 1.4 泰勒展开公式
- 1.5 Jacobian矩阵与Hessian矩阵
- 1.6 正定矩阵
- 2. 梯度下降法
- 3. 牛顿法
- 4. 拟牛顿法
- 5. 代码实现
- 结束语
前言
本篇博文主要介绍了机器学习里面的常见的求解无约束最优化问题的方法,包括梯度下降法、牛顿法和拟牛顿法,并给出了相关的推导过程及代码实现。
本篇博文内容主要来自李航老师的《统计学习方法》(附录A和B)。
1. 基础知识
1.1 方向导数
在许多问题中,我们不仅要知道函数再坐标轴上的变化率(即偏导数),而且还要设法求得函数在某点沿着其他特定方向上的变化率,这就是方向导数。
方向导数的计算公式如下:设三元函数 u = u ( x , y , z ) u=u(x,y,z) u=u(x,y,z)在点 P 0 ( x 0 , y 0 , z 0 ) P_0(x_0,y_0,z_0) P0(x0,y0,z0)处可微分,则 u = u ( x , y , z ) u=u(x,y,z) u=u(x,y,z)在点 P 0 P_0 P0处沿任一方向 l \bm l l 的方向导数都存在,则

1.2 梯度
在一个数量场中,函数在给定点处沿不同的方向,其方向导数一般都是不相同的,现在我们关心的是沿哪一个方向其方向导数最大?最大值是多少?函数在点 P P P沿哪一个方向增加的速度最快?由此引入了梯度这一概念。
设三元函数 u = u ( x , y , z ) u=u(x,y,z) u=u(x,y,z)在点 P 0 ( x 0 , y 0 , z 0 ) P_0(x_0,y_0,z_0) P0(x0,y0,z0)处具有一阶偏导数,则定义 g r a d u ∣ P 0 = ( u x ′ ( P 0 ) , u y ′ ( P 0 ) , u z ′ ( P 0 ) ) \bm {grad} u\bigg|_{P_0}=(u^{\prime}_x(P_0),u^{\prime}_y(P_0),u^{\prime}_z(P_0)) gradu P0=(ux′(P0),uy′(P0),uz′(P0)) 为函数 u = u ( x , y , z ) u=u(x,y,z) u=u(x,y,z)在点 P 0 ( x 0 , y 0 , z 0 ) P_0(x_0,y_0,z_0) P0(x0,y0,z0)处的梯度。
1.3 方向导数与梯度的关系
由方向导数的计算公式和梯度的定义可以得到
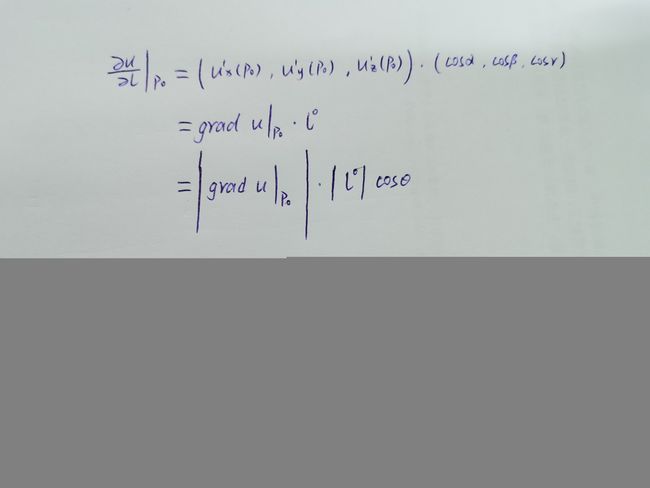
由上可以得到如下结论:函数在某点的梯度是一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值,再通俗点说,梯度的方向就是变化率最快的方向,也就是函数值增加最快的方向。
1.4 泰勒展开公式
设 f ( x ) f(x) f(x)在点 x 0 x_0 x0的某个邻域内n+1阶导数存在,则对该邻域内的任意点有 f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 + ⋯ + 1 n ! f ( n ) ( x 0 ) ( x − x 0 ) n + 1 ( n + 1 ) ! f ( n + 1 ) ( ξ ) ( x − x 0 ) ( n + 1 ) f(x)=f(x_0)+f^{\prime}(x_0)(x-x_0)+\frac {1} {2} f^{\prime\prime}(x_0)(x-x_0)^2+\dots+\frac {1} {n!} f^{(n)}(x_0)(x-x_0)^n+\frac {1} {(n+1)!} f^{(n+1)}(\xi)(x-x_0)^{(n+1)} f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2+⋯+n!1f(n)(x0)(x−x0)n+(n+1)!1f(n+1)(ξ)(x−x0)(n+1) 其中 ξ \xi ξ介于 x x x和 x 0 x_0 x0之间。
上述公式是带拉格朗日余项的n阶泰勒公式,当 x 0 = 0 x_0=0 x0=0时,上述泰勒公式又称为麦克劳林公式。
1.5 Jacobian矩阵与Hessian矩阵
简单来说,由一阶偏导数组成的矩阵叫做Jacobian矩阵(雅可比矩阵),由二阶偏导数组成的矩阵叫做Hessian矩阵(黑塞矩阵)。
称矩阵 J = [ ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 … ∂ f 1 ∂ x n ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 … ∂ f 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ f n ∂ x 1 ∂ f n ∂ x 2 … ∂ f n ∂ x n ] J=\begin{bmatrix} \frac {\partial f_1} {\partial {x_1}} & \frac {\partial f_1} {\partial {x_2}} & \dots & \frac {\partial f_1} {\partial {x_n}} \\[5pt] \frac {\partial f_2} {\partial {x_1}} & \frac {\partial f_2} {\partial {x_2}} & \dots &\frac {\partial f_2} {\partial {x_n}} \\ \vdots & \vdots & \ddots & \vdots \\[3pt] \frac {\partial f_n} {\partial {x_1}} & \frac {\partial f_n} {\partial {x_2}} & \dots & \frac {\partial f_n} {\partial {x_n}} \end{bmatrix} J= ∂x1∂f1∂x1∂f2⋮∂x1∂fn∂x2∂f1∂x2∂f2⋮∂x2∂fn……⋱…∂xn∂f1∂xn∂f2⋮∂xn∂fn 为雅可比矩阵(Jacobian Matrix),也可记作 ∇ f \nabla f ∇f
若 n n n元函数 f ( x ) f(x) f(x)在点 x x x处对于自变量的各分量的二阶偏导数连续,则称矩阵 H ( x ) = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 x 2 … ∂ 2 f ∂ x 1 x n ∂ 2 f ∂ x 2 x 1 ∂ 2 f ∂ x 2 2 … ∂ 2 f ∂ x 2 x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n x 1 ∂ 2 f ∂ x n x 2 … ∂ 2 f ∂ x n 2 ] H(x)=\begin{bmatrix} \frac {\partial ^2f} {\partial {x_1}^2} & \frac {\partial ^2f} {\partial {x_1}{x_2}} & \dots & \frac {\partial ^2f} {\partial {x_1}{x_n}} \\[5pt] \frac {\partial ^2f} {\partial {x_2}{x_1}} & \frac {\partial ^2f} {\partial {x_2}^2} & \dots &\frac {\partial ^2f} {\partial {x_2}{x_n}} \\[3pt] \vdots & \vdots & \ddots & \vdots \\[3pt] \frac {\partial ^2f} {\partial {x_n}{x_1}} & \frac {\partial ^2f} {\partial {x_n}{x_2}} & \dots & \frac {\partial ^2f} {\partial {x_n}^2} \end{bmatrix} H(x)= ∂x12∂2f∂x2x1∂2f⋮∂xnx1∂2f∂x1x2∂2f∂x22∂2f⋮∂xnx2∂2f……⋱…∂x1xn∂2f∂x2xn∂2f⋮∂xn2∂2f 为 f ( x ) f(x) f(x)在点 x x x处的二阶导数或黑塞矩阵(Hessian Matrix),也可记作 ∇ 2 f ( x ) \nabla ^2f(x) ∇2f(x) 由此可以知道,Hessian矩阵是一个对称矩阵。
1.6 正定矩阵
n n n元二次型 f ( x 1 , x 2 , … , x n ) = x T A x f(x_1, x_2, \dots, x_n)=x^TAx f(x1,x2,…,xn)=xTAx,若对任意的 x = [ x 1 , x 2 , … , x n ] T ≠ 0 x=[x_1,x_2,\dots,x_n]^T \neq 0 x=[x1,x2,…,xn]T=0,均有 x T A x > 0 x^TAx > 0 xTAx>0,则成 f f f为正定二次型,二次型对应的矩阵 A A A为正定矩阵。
二次型正定的充分条件:
n n n元二次型 f = x T A x f=x^TAx f=xTAx正定 ⟺ \Longleftrightarrow ⟺ 对于任意 x ≠ 0 x \neq 0 x=0,有 x T A x > 0 x^TAx > 0 xTAx>0
⟺ \Longleftrightarrow ⟺ f f f的正惯性指数 p = n p=n p=n
⟺ \Longleftrightarrow ⟺ 存在可逆矩阵 D D D,使 A = D T D A=D^TD A=DTD
⟺ \Longleftrightarrow ⟺ A A A与 E E E合同,即存在矩阵 C C C,是 C T A C = E C^TAC=E CTAC=E
⟺ \Longleftrightarrow ⟺ A A A的特征值 λ i > 0 ( i = 1 , 2 , … , n ) \lambda _i > 0 (i=1,2,\dots,n) λi>0(i=1,2,…,n)
⟺ \Longleftrightarrow ⟺ A A A的全部顺序主子式均大于0
二次型正定的必要条件:
(1) a i i > 0 ( i = 0 , 1 , … , n ) a_{ii} > 0 (i=0,1,\dots,n) aii>0(i=0,1,…,n)
(2) ∣ A ∣ > 0 |A| > 0 ∣A∣>0
2. 梯度下降法
梯度下降法 ( g r a d i e n t d e s c e n t , G D ) (gradient\ descent,\ GD) (gradient descent, GD)是求解无约束最优化问题的一种常用的方法,具有简单的优点。梯度下降算法是迭代算法,每一步需要求解目标函数的梯度向量。
在《统计学习方法》中对梯度下降法的介绍如下:
设 f ( x ) f(x) f(x)是 R n R^n Rn上具有一阶连续偏导数的函数。要求解的无约束最优化问题是 m i n x ∈ R n f ( x ) \underset {x \in \bm R^n} {min} f(x) x∈Rnminf(x) x ∗ x^∗ x∗表示目标函数 f ( x ) f(x) f(x)的极小点。选取适当的初值 x 0 x_0 x0,不断迭代,更新 x x x的值,进行目标函数的极小化,直到收敛。由于负梯度方向是使函数值下降最快的方向,在迭代的每一步,以负梯度方向更新 x x x的值,从而达到减少函数值的目的。
由于 f ( x ) f(x) f(x)具有一阶连续偏导数,若第 k k k次迭代值为 x k x_k xk,则可将 f ( x ) f(x) f(x)在 x k x_k xk附近进行一阶泰勒展开: f ( x ) = f ( x k ) + g k ( x − x k ) f(x)=f(x_k)+g_k(x-x_k) f(x)=f(xk)+gk(x−xk) 其中 g k = g ( x k ) = ∇ f ( x k ) g_k=g(x_k) = \nabla f(x_k) gk=g(xk)=∇f(xk)为 f ( x ) f(x) f(x)在 x k x_k xk的梯度。
求出第 k + 1 k+1 k+1次迭代值 x k + 1 x_{k+1} xk+1: x k + 1 ← x k + λ k p k x_{k+1} \leftarrow x_k + \lambda _k p_k xk+1←xk+λkpk 其中, p k p_k pk是搜索方向,取负梯度方向 p k = − ∇ f ( x k ) = − g k p_k=−\nabla f(x_k) = -g_k pk=−∇f(xk)=−gk, λ k \lambda _k λk是步长(也就是学习率),由一维搜索确定,即 λ k \lambda _k λk使得 f ( x k + λ k p k ) = m i n λ ≥ 0 f ( x k + λ p k ) f(x_k + \lambda _k p_k) = \underset {\lambda \geq 0} {min} f(x_k + \lambda p_k) f(xk+λkpk)=λ≥0minf(xk+λpk)
为方便计算,这里将学习率固定:

当目标函数是凸函数时,梯度下降法的解是全局最优解。一般情况下,其解不保证是全局最优解。梯度下降法的收敛速度也未必是很快的。
3. 牛顿法
相比梯度下降算法,牛顿法使用的是二阶泰勒展开式。
设 f ( x ) f(x) f(x)具有二阶连续偏导数,若第 k k k次迭代值为 x k x_k xk,则可将 f ( x ) f(x) f(x)在 x k x_k xk附近进行二阶泰勒展开: f ( x ) = f ( x k ) + g k ( x − x k ) + 1 2 H ( x k ) ( x − x k ) 2 f(x)=f(x_k)+g_k(x-x_k)+\frac {1} {2}H(x_k)(x-x_k)^2 f(x)=f(xk)+gk(x−xk)+21H(xk)(x−xk)2 其中, g k = g ( x k ) = ∇ f ( x k ) g_k=g(x_k) = \nabla f(x_k) gk=g(xk)=∇f(xk)为 f ( x ) f(x) f(x)的梯度向量在 x k x_k xk处的值, H ( x k ) = ∇ 2 f ( x k ) H(x_k)=\nabla ^2f(x_k) H(xk)=∇2f(xk)为 f ( x ) f(x) f(x)的黑塞矩阵 H ( x ) = [ ∂ 2 f ∂ x i ∂ x j ] H(x)=\bigg[\frac {\partial ^2f} {\partial x_i \partial x_j}\bigg] H(x)=[∂xi∂xj∂2f]在 x k x_k xk处的值。
函数 f ( x ) f(x) f(x)有极值的必要条件是在极值点处一阶导数为0,即梯度向量为0。特别是当 H ( x k ) H(x_k) H(xk)是正定矩阵时,函数 f ( x ) f(x) f(x)的极值为极小值。
(1)类比一元函数判别极值的第二充分条件,即 f ( x ) f(x) f(x)在 x = x 0 x=x_0 x=x0处二阶可导,且 f ′ ( x 0 ) = 0 f^{\prime}(x_0)=0 f′(x0)=0, f ′ ′ ( x 0 ) ≠ 0 f^{\prime \prime}(x_0) \neq 0 f′′(x0)=0,若 f ′ ′ ( x 0 ) > 0 f^{\prime \prime}(x_0) > 0 f′′(x0)>0,则 f ( x ) f(x) f(x)在 x 0 x_0 x0处取极小值。
(2)类比二元函数取极值的充分条件,若 H = [ A B B C ] H=\begin{bmatrix} A & B \\[3pt] B & C \end{bmatrix} H=[ABBC]为正定矩阵,根据正定矩阵的全部顺序主子式均大于0可知, A > 0 A>0 A>0, Δ = A C − B 2 > 0 \Delta = AC-B^2>0 Δ=AC−B2>0,所以 f f f有极小值。
牛顿法利用极小点的必要条件: ∇ f ( x ) = 0 \nabla f(x) = 0 ∇f(x)=0 根据这一条件,对 f ( x ) f(x) f(x)的二阶泰勒展开式求导可得: ∇ f ( x ) = g k + H ( x k ) ( x − x k ) \nabla f(x)=g_k+H(x_k)(x-x_k) ∇f(x)=gk+H(xk)(x−xk)
假设在 x k + 1 x_{k+1} xk+1处也满足 ∇ f ( x k + 1 ) = 0 \nabla f(x_{k+1}) = 0 ∇f(xk+1)=0,则可以得到 ∇ f ( x k + 1 ) = g k + H ( x k ) ( x k + 1 − x k ) \nabla f(x_{k+1})=g_k+H(x_k)(x_{k+1}-x_k) ∇f(xk+1)=gk+H(xk)(xk+1−xk) 假进一步可以得到 x k + 1 = x k − H k − 1 g k x_{k+1} = x_k-H_k^{-1}g_k xk+1=xk−Hk−1gk 具体算法如下:

可见,相比梯度下降法,牛顿法的步长是自动计算出来的,且收敛速度较快。
4. 拟牛顿法
在牛顿法的迭代中,需要计算黑塞矩阵的逆矩阵 H − 1 H^{-1} H−1,这一计算比较复杂,考虑用一个 n n n阶矩阵 G k = G ( x k ) G_k=G(x_k) Gk=G(xk)来近似代替 H k − 1 = H − 1 ( x k ) H_k^{-1} = H^{-1}(x_k) Hk−1=H−1(xk),这就是拟牛顿法的基本想法。
5. 代码实现
代码实现如下:
# -*- coding:utf-8 -*-
# Author: liyanpeng
# Email: [email protected]
# Datetime: 2023/1/31 15:30
# Filename: grad.py
import numpy as np
from matplotlib import pyplot as plt
def f(x):
return x ** 2 + 1
def g(x): # f(x)的导数
return 2 * x
if __name__ == '__main__':
max_count = 50000
lr = 0.05
x_k = np.random.uniform(-1, 1)
err = 0.00001
print('Init x_0 is : ', x_k)
# fig = plt.figure()
# plt.ion()
# x_ = np.linspace(-1, 1, num=200)
# plt.plot(x_, f(x_))
for i in range(max_count):
# if 'sca' in globals():
# sca.remove()
# sca = plt.scatter(x_k, f(x_k), s=100, lw=0, c='red', alpha=0.5)
# plt.pause(0.1)
grad = g(x_k) # 计算梯度
if abs(grad) < err: # 梯度收敛到控制误差内
break
x_k = x_k + (-grad) * lr # 更新x(迭代公式: 梯度下降法)
# x_k = x_k - grad / 2 # 更新x(迭代公式: 牛顿法,由于是一元二次函数,所以其二阶导数为常数2)
print('The optimal solution x* is: {:.6f} ==> f(x*)={:.6f}'.format(x_k, f(x_k)))
# plt.scatter(x_k, f(x_k), s=100, lw=0, c='green')
# plt.ioff()
# plt.show()
可视化效果如下:
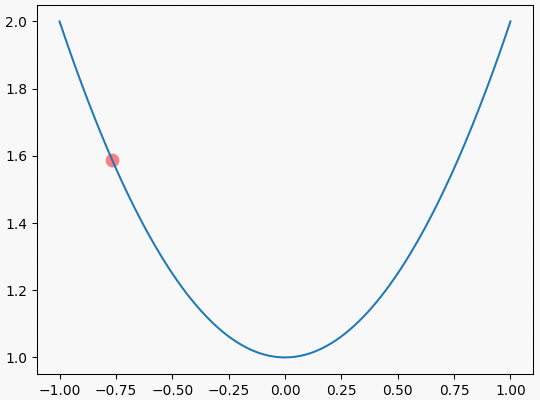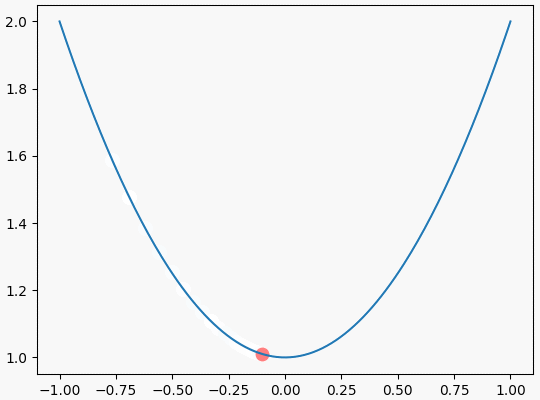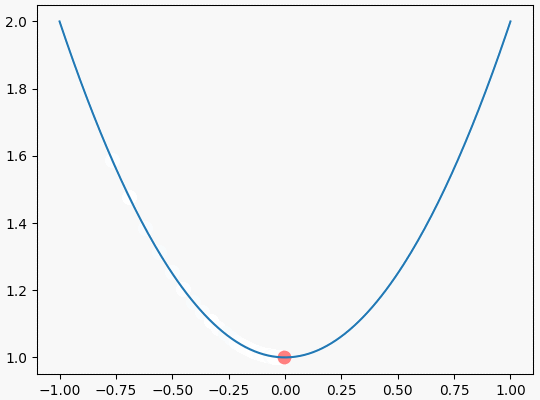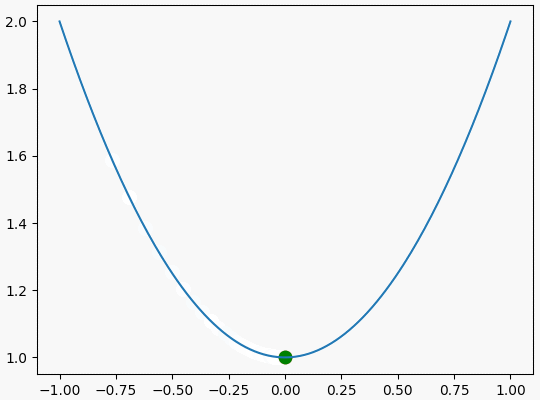
结束语
持续充电中,博客内容也在不断更新补充中,如有错误,欢迎来私戳小编哦!共同进步,感谢Thanks♪(・ω・)ノ
