前言
- 读完代码解析篇,我们针对开源项目中的模型预测方法做一下介绍。Github源码下载地址
- 下载数据集
ETTh、PEMS、Traffic、Splar-Energy、Electricity、Exchange-Rate,这几类公共数据集的任意一类就行。这里以ETTh数据集为例,先在项目文件夹下新建datasets文件夹,然后将数据集移至其中
- 打开项目文件夹下
run_ETTh.py文件,只需要检查一下数据路径、名称和csv文件就行
parser.add_argument('--data', type=str, required=False, default='ETTh1', choices=['ETTh1', 'ETTh2', 'ETTm1'], help='name of dataset')
parser.add_argument('--root_path', type=str, default='./datasets/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='location of the data file')
- 然后跑一下,看看跑不跑的通,注意一定要是在GPU环境下,否则报错,后面的自定义项目是建立在原代码能跑通的情况下。
自定义项目
参数设定修改
- 首先将需要预测的数据集放入
datasets文件夹中,时间列列名必须为date。
- 然后我们复制
run_ETTh.py文件,并粘贴在项目文件夹下,重命名为run_power.py这个名字随便取,别和已有文件重复就行。
- 打开
run_power.py文件,修改开头库导入部分,主要是最后一句,要导入Exp_power
import argparse
import os
import torch
import numpy as np
from torch.utils.tensorboard import SummaryWriter
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
from experiments.exp_power import Exp_power
- 修改数据载入部分,包括数据名称、路径、文件、目标预测列、采样间隔(我用的数据集是每1分钟收集一次数据,所以参数设为
t)
parser.add_argument('--data', type=str, required=False, default='power data', choices=['ETTh1', 'ETTh2', 'ETTm1'], help='name of dataset')
parser.add_argument('--root_path', type=str, default='./datasets/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='power data.csv', help='location of the data file')
parser.add_argument('--features', type=str, default='M', choices=['S', 'M'], help='features S is univariate, M is multivariate')
parser.add_argument('--target', type=str, default='总有功功率(kw)', help='target feature')
parser.add_argument('--freq', type=str, default='t', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
parser.add_argument('--checkpoints', type=str, default='exp/ETT_checkpoints/', help='location of model checkpoints')
parser.add_argument('--inverse', type=bool, default =False, help='denorm the output data')
parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--seq_len', type=int, default = 480, help='input sequence length of SCINet encoder, look back window')
parser.add_argument('--label_len', type=int, default = 288, help='start token length of Informer decoder')
parser.add_argument('--pred_len', type=int, default = 960, help='prediction sequence length, horizon')
- 再修改特征数量设置,data_parser变量,在
run_power.py文件中只需要更改这些。
data_parser = {'power data': {'data': 'power data.csv', 'T': '总有功功率(kw)', 'M': [5, 5, 5], 'S': [1, 1, 1], 'MS': [5, 5, 1]},}
- 注意,如果需要模型输出中间结果,即预测值、真实值,测试值等,请将
--save参数置为True
parser.add_argument('--save', type=bool, default = True, help='save the output results')
- 同样的,打开
experiments文件夹,复制exp_ETTh.py文件,并粘贴在同目录中,重命名为exp_power.py,并将其中Exp_ETTh类修改为Exp_power。
class Exp_power(Exp_Basic):
数据处理
- 打开
experiments文件夹下exp_power.py文件,修改Exp_power类下_build_model函数,in_dim函数修改为数据特征数,我这里是5,所以in_dim = 5
def _build_model(self):
if self.args.features == 'S':
in_dim = 1
elif self.args.features == 'M':
in_dim = 5
else:
print('Error!')
- 再跳转到
_get_data函数,修改data_dict
data_dict = {'power data': Dataset_Custom}
- 在
exp_power.py文件中只需要更改这些。到此为止,项目修改工作结束,这时跑一下run_power.py函数看看能否跑的通。
在kaggle上使用
- 因为该源码只支持在
GPU上运行,若使用的设备没有GPU,我们可以将项目文件搬到kaggle上进行,首先还是要根据上述说明修改好项目文件,然后打包成zip文件上传至kaggle数据集中。
- 新建
notebook文件,并将其设置为P100GPU模式下

导入包
import sys
if not '/kaggle/input/scinet-model-data' in sys.path:
sys.path += ['/kaggle/input/scinet-model-data']
import argparse
import os
import torch
import numpy as np
import optuna
from torch.utils.tensorboard import SummaryWriter
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
from experiments.exp_power import Exp_power
参数传导
args = argparse.ArgumentParser(description='SCINet on ETT dataset')
args.model = 'SCINet'
args.data = 'power data'
args.root_path = '/kaggle/input/scinet-model-data/datasets/'
args.data_path = 'power data.csv'
args.features ='M'
args.target = '总有功功率(kw)'
args.freq = 't'
args.checkpoints = 'exp/power_checkpoints/'
args.inverse = False
args.embed ='timeF'
args.use_gpu = True
args.gpu = 0
args.use_multi_gpu = False
args.devices = '0'
args.seq_len = 480
args.label_len = 288
args.pred_len = 960
args.concat_len = 0
args.single_step = 0
args.single_step_output_One = 0
args.lastWeight = 1.0
args.cols = False
args.num_workers = 0
args.itr = 0
args.train_epochs = 100
args.batch_size = 128
args.patience = 5
args.lr = 1e-4
args.loss = 'SmoothL1Loss'
args.optim = 'AdamW'
args.lradj = 1
args.use_amp = False
args.save = True
args.model_name = 'SCINet'
args.resume = False
args.evaluate = False
args.hidden_size = 1.995
args.INN = 1
args.kernel = 7
args.dilation = 1
args.window_size = 480
args.dropout = 0.5
args.positionalEcoding = False
args.groups = 1
args.levels = 3
args.stacks = 2
args.num_decoder_layer = 1
args.RIN = False
args.decompose = False
检查GPU
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ', '')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
定义数据加载
data_parser = {'power data': {'data': 'power data.csv', 'T': '总有功功率(kw)', 'M': [5, 5, 5], 'S': [1, 1, 1], 'MS': [5, 5, 1]},}
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
args.detail_freq = args.freq
args.freq = args.freq[-1:]
复现设置
torch.manual_seed(2023)
torch.cuda.manual_seed_all(2023)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.enabled = True
训练模型
Exp = Exp_power
mae_ = []
maes_ = []
mse_ = []
mses_ = []
setting = '{}_levels {}_kernel {}_hidden {}'.format(args.model,args.levels,args.kernel,args.hidden_size)
exp = Exp(args)
exp.train(setting)
mae, maes, mse, mses = exp.test(setting)
print('{:s}:{:.4f},mae:{:.4f}'.format(setting, mse, mae))
模型参数调节
- 根据论文,较为重要的几个参数分别为
--kernel、--levels、--stacks、--hidden_size其次是--lr、--dropout,我的建议是先调节联合调节--kernel、--levels、--stacks参数,然后再调节--lr、--dropout
- 参数调节范围建议:
--kernel整型[1,7]--levels整型[1,5]--stacks整型[1,2]--hidden_size浮点型[0.1,2]
- 调参时可以选择
ray、optuna等智能调参框架,也可以选择写脚本进行网格搜索等等。但该模型时空复杂度并不低,这里还是建议选用智能优化调参框架,在时间尽可能短的情况下锁定局部最优解。
后记
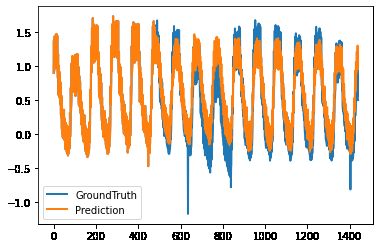
- 这里放一张模型训练完成后绘制的真实值与预测值间对比图