人脸匹配对齐算法pytorch_PyTorch 实现孪生网络识别面部相似度
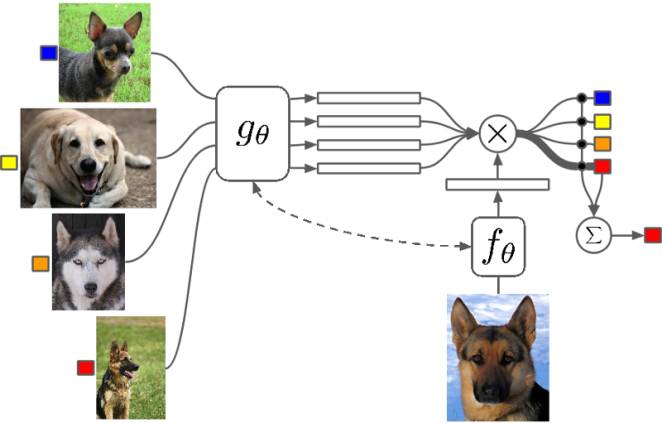
深度神经网络是涉及图像分类问题的重要算法。这其中的部分原因是,它们具有大量的可训练的参数。然而,这是以需要大量的数据为代价的,而这有时是不可获得的。那么接下来,我就将讨论小样本学习(One Shot Learning),其旨在缓解诸如此类的问题,以及如何在PyTorch中实现一个使用它的神经网络。
本文假设你对神经网络知识有所了解。本文相关材料线索来自于此篇论文
标准分类vs小样本分类
几乎所有分类模型使用的都是标准分类。输入被馈送到一系列层,最后输出类概率。如果你想通过猫来预测出狗,你可以在你所期望的预测时间内训练相似的(但不相同的)狗/猫图片模型。当然,这要求你有一个数据集,与你使用模型进行预测时所期望的数据集类似。
另一方面,小样本分类模型的要求就是,你只要有一个你想要预测的每个类的训练样本就可以。该模型仍然在几个实例上进行训练,但是它们只需要与你的训练样本相类似。
可以说明此问题的一个很好的例子就是面部识别。你可以在一个包含少数人的各种角度、拍摄光线等数据的数据集上训练此小样本分类模型。然后,如果你想要判别某人X是否在图像中,那么就可以拍摄该人的一张照片,然后询问模型该人物是否在该图像中(请注意,该模型没有使用某人X的任何照片进行训练)。
作为人类,我们往往只需要一次会面就可以通过面部识别出一个人,而且对于计算机来说,这是很可取的,因为大多数情况下数据处于最小值。
孪生网络
孪生网络是一种特殊类型的神经网络架构。与一个学习对其输入进行分类的模型不同,该神经网络是学习在两个输入中进行区分。它学习了两个输入之间的相似之处。
架构
孪生网络由两个完全相同的神经网络组成,每个都采用两个输入图像中的一个。然后将两个网络的最后一层馈送到对比损失函数,用来计算两个图像之间的相似度。我已经做了一个图解用来帮助解释这个架构。
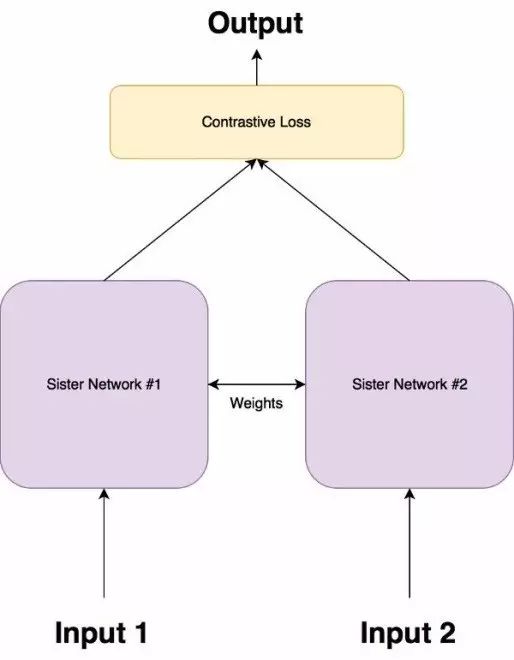
它具有两个姐妹网络,它们是具有完全相同权重的相同神经网络。图像对中的每个图像将被馈送到这些网络中的一个。使用对比损失函数优化网络(我们将获得确切的函数)。
对比损失函数(Contrastive Loss function)
孪生架构的目的不是对输入图像进行分类,而是区分它们。因此,分类损失函数(如交叉熵)不是最合适的选择。相反,这种架构更适合使用对比函数。根据直觉而言,这个函数只是评估网络区分一对给定的图像的效果如何。
点击此处链接获取更多详情
对比损失函数如下:
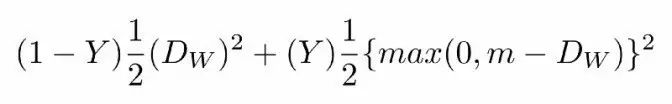
等式1.0
其中Dw被定义为姐妹孪生网络的输出之间的欧氏距离(euclidean distance)。数学上欧氏距离是:
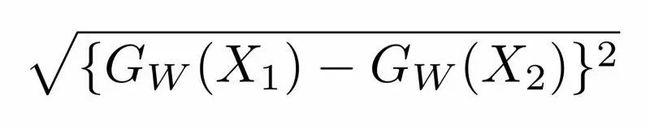
等式1.1
其中Gw是其中一个姐妹网络的输出。X1和X2是输入数据对。
等式1.0说明
Y值为1或0。如果模型预测输入是相似的,那么Y的值为0,否则Y为1。
max()是表示0和m-Dw之间较大值的函数。
m是大于0的边际价值(margin value)。有一个边际价值表示超出该边际价值的不同对不会造成损失。这是有道理的,因为你只希望基于实际不相似对来优化网络,但网络认为是相当相似的。
数据集
我们将使用两个数据集,经典的MNIST和OmniGlot。 MNIST将用于训练模型以了解如何区分字符,然后我们将在OmniGlot上测试该模型。
OmniGlot数据集由包含50种国际语言的样本组成。每种语言中的每个字母只有20个样本。 这被认为是MNIST的“转置”,其中类的数量较少(10个),训练样本数量较多。在OmniGlot中类的数量是非常多的,而每个类的样本数是很少的。

图2.0来自OmniGlot数据集的一些样本
OmniGlot将用作我们的小样本分类数据集,以便能够从少数样本中识别出许多不同的类。
结论
我们是在小样本学习下进行研究,并尝试使用一种称为孪生网络的神经网络架构来解决这一问题。与此同时,我们还讨论了区分输入对的损失函数。
同时,我们还实施了这样的架构,并对MNIST进行训练,然后在OmniGlot上进行了预测。https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
架构
我们将使用的是标准卷积神经网络(CNN)架构,在每个卷积层之后使用批量归一化,然后dropout。
代码片段:孪生网络架构:
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.cnn1 = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(1, 4, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(4),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(4, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(8, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.Dropout2d(p=.2),
)
self.fc1 = nn.Sequential(
nn.Linear(8*100*100, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 5)
)
def forward_once(self, x):
output = self.cnn1(x)
output = output.view(output.size()[0], -1)
output = self.fc1(output)
return output
def forward(self, input1, input2):
output1 = self.forward_once(input1)
output2 = self.forward_once(input2)
return output1, output2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43classSiameseNetwork(nn.Module):
def__init__(self):
super(SiameseNetwork,self).__init__()
self.cnn1=nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(1,4,kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(4),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(4,8,kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(8,8,kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.Dropout2d(p=.2),
)
self.fc1=nn.Sequential(
nn.Linear(8*100*100,500),
nn.ReLU(inplace=True),
nn.Linear(500,500),
nn.ReLU(inplace=True),
nn.Linear(500,5)
)
defforward_once(self,x):
output=self.cnn1(x)
output=output.view(output.size()[0],-1)
output=self.fc1(output)
returnoutput
defforward(self,input1,input2):
output1=self.forward_once(input1)
output2=self.forward_once(input2)
returnoutput1,output2
其实这个网络并没有什么特别之处,它可以接收一个100px * 100px的输入,并且在卷积层之后具有3个完全连接的层。
在上篇文章中,我展示了一对网络是如何处理数据对中的每个图像的。但在这篇文章中,只有一个网络。因为两个网络的权重是相同的,所以我们使用一个模型并连续地给它提供两个图像。之后,我们使用两个图像来计算损失值,然后再返回传播。这样可以节省大量的内存,绝对不会影响其他指标(如精确度)。
对比损失
我们将对比损失定义为
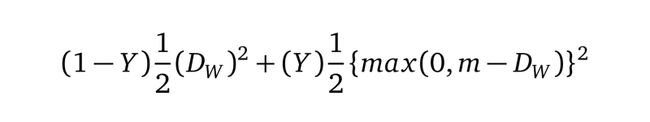 等式1.0
等式1.0
我们将Dw(也就是欧氏距离)定义为:
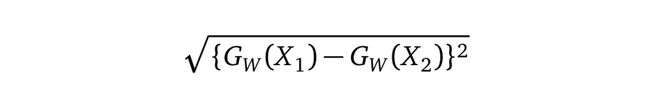
等式1.1
Gw是我们网络的一个图像的输出。
PyTorch中的对比损失看起来是这样的:
代码片段:默认边际价值为2的对比损失:
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
"""
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2)
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16classContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
"""
def__init__(self,margin=2.0):
super(ContrastiveLoss,self).__init__()
self.margin=margin
defforward(self,output1,output2,label):
euclidean_distance=F.pairwise_distance(output1,output2)
loss_contrastive=torch.mean((1-label)*torch.pow(euclidean_distance,2)
(label)*torch.pow(torch.clamp(self.margin-euclidean_distance,min=0.0),2))
returnloss_contrastive
数据集
在上一篇文章中,我想使用MNIST,但有些读者建议我使用我在同篇文章中所讨论的面部相似性样本。因此,我决定从MNIST / OmniGlot切换到AT&T面部数据集。
数据集包含40名测试对象的不同角度的图像。我从训练中挑选出3名测试对象的图像,以测试我们的模型。

不同类的样本图像

一名测试对象的所有样本图像
数据加载
我们的架构需要一个输入对,以及标签(类似/不相似)。因此,我创建了自己的自定义数据加载器来完成这项工作。它使用图像文件夹从文件夹中读取图像。这意味着你可以将其用于任何你所希望的数据集中。
代码段:该数据集生成一对图像和相似性标签。如果图像来自同一个类,标签将为0,否则为1:
class SiameseNetworkDataset(Dataset):
def __init__(self,imageFolderDataset,transform=None,should_invert=True):
self.imageFolderDataset = imageFolderDataset
self.transform = transform
self.should_invert = should_invert
def __getitem__(self,index):
img0_tuple = random.choice(self.imageFolderDataset.imgs)
#we need to make sure approx 50% of images are in the same class
should_get_same_class = random.randint(0,1)
if should_get_same_class:
while True:
#keep looping till the same class image is found
img1_tuple = random.choice(self.imageFolderDataset.imgs)
if img0_tuple[1]==img1_tuple[1]:
break
else:
img1_tuple = random.choice(self.imageFolderDataset.imgs)
img0 = Image.open(img0_tuple[0])
img1 = Image.open(img1_tuple[0])
img0 = img0.convert("L")
img1 = img1.convert("L")
if self.should_invert:
img0 = PIL.ImageOps.invert(img0)
img1 = PIL.ImageOps.invert(img1)
if self.transform is not None:
img0 = self.transform(img0)
img1 = self.transform(img1)
return img0, img1 , torch.from_numpy(np.array([int(img1_tuple[1]!=img0_tuple[1])],dtype=np.float32))
def __len__(self):
return len(self.imageFolderDataset.imgs)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37classSiameseNetworkDataset(Dataset):
def__init__(self,imageFolderDataset,transform=None,should_invert=True):
self.imageFolderDataset=imageFolderDataset
self.transform=transform
self.should_invert=should_invert
def__getitem__(self,index):
img0_tuple=random.choice(self.imageFolderDataset.imgs)
#we need to make sure approx 50% of images are in the same class
should_get_same_class=random.randint(0,1)
ifshould_get_same_class:
whileTrue:
#keep looping till the same class image is found
img1_tuple=random.choice(self.imageFolderDataset.imgs)
ifimg0_tuple[1]==img1_tuple[1]:
break
else:
img1_tuple=random.choice(self.imageFolderDataset.imgs)
img0=Image.open(img0_tuple[0])
img1=Image.open(img1_tuple[0])
img0=img0.convert("L")
img1=img1.convert("L")
ifself.should_invert:
img0=PIL.ImageOps.invert(img0)
img1=PIL.ImageOps.invert(img1)
ifself.transformisnotNone:
img0=self.transform(img0)
img1=self.transform(img1)
returnimg0,img1,torch.from_numpy(np.array([int(img1_tuple[1]!=img0_tuple[1])],dtype=np.float32))
def__len__(self):
returnlen(self.imageFolderDataset.imgs)
孪生网络数据集生成一对图像,以及它们的相似性标签(如果为真,则为0,否则为1)。 为了防止不平衡,我将保证几乎一半的图像是同一个类的,而另一半则不是。
训练孪生网络
孪生网络的训练过程如下:
1. 通过网络传递图像对的第一张图像。
2. 通过网络传递图像对的第二张图像。
3. 使用1和2中的输出来计算损失。
4. 返回传播损失计算梯度
5. 使用优化器更新权重。我们将用Adam来进行演示:
代码片段:训练孪生网络:
net = SiameseNetwork().cuda()
criterion = ContrastiveLoss()
optimizer = optim.Adam(net.parameters(),lr = 0.0005 )
counter = []
loss_history = []
iteration_number= 0
for epoch in range(0,Config.train_number_epochs):
for i, data in enumerate(train_dataloader,0):
img0, img1 , label = data
img0, img1 , label = Variable(img0).cuda(), Variable(img1).cuda() , Variable(label).cuda()
output1,output2 = net(img0,img1)
optimizer.zero_grad()
loss_contrastive = criterion(output1,output2,label)
loss_contrastive.backward()
optimizer.step()
if i %10 == 0 :
print("Epoch number {}\n Current loss {}\n".format(epoch,loss_contrastive.data[0]))
iteration_number =10
counter.append(iteration_number)
loss_history.append(loss_contrastive.data[0])
show_plot(counter,loss_history)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23net=SiameseNetwork().cuda()
criterion=ContrastiveLoss()
optimizer=optim.Adam(net.parameters(),lr=0.0005)
counter=[]
loss_history=[]
iteration_number=0
forepochinrange(0,Config.train_number_epochs):
fori,datainenumerate(train_dataloader,0):
img0,img1,label=data
img0,img1,label=Variable(img0).cuda(),Variable(img1).cuda(),Variable(label).cuda()
output1,output2=net(img0,img1)
optimizer.zero_grad()
loss_contrastive=criterion(output1,output2,label)
loss_contrastive.backward()
optimizer.step()
ifi%10==0:
print("Epoch number {}\n Current loss {}\n".format(epoch,loss_contrastive.data[0]))
iteration_number=10
counter.append(iteration_number)
loss_history.append(loss_contrastive.data[0])
show_plot(counter,loss_history)
网络使用Adam,以0.0005的学习率进行了100次的迭代训练。随着时间的变化,损失曲线如下所示:
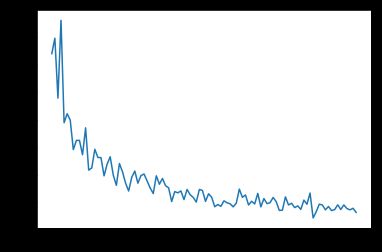
随时间变化的损失值曲线,x轴代表迭代次数
测试网络
我们从训练中抽取了3个测试对象,用于评估我们的模型性能。
为了计算相似度,我们只是计算Dw(公式1.1)。其中距离直接对应于图像对之间的不相似度。Dw的高值表示较高的不相似度。
代码片段:通过计算模型输出之间的距离来评估模型:
folder_dataset_test = dset.ImageFolder(root=Config.testing_dir)
siamese_dataset = SiameseNetworkDataset(imageFolderDataset=folder_dataset_test,
transform=transforms.Compose([transforms.Scale((100,100)),
transforms.ToTensor()
])
,should_invert=False)
test_dataloader = DataLoader(siamese_dataset,num_workers=6,batch_size=1,shuffle=True)
dataiter = iter(test_dataloader)
x0,_,_ = next(dataiter)
for i in range(10):
_,x1,label2 = next(dataiter)
concatenated = torch.cat((x0,x1),0)
output1,output2 = net(Variable(x0).cuda(),Variable(x1).cuda())
euclidean_distance = F.pairwise_distance(output1, output2)
imshow(torchvision.utils.make_grid(concatenated),\\\'Dissimilarity: {:.2f}\\\'.format(euclidean_distance.cpu().data.numpy()[0][0]))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18folder_dataset_test=dset.ImageFolder(root=Config.testing_dir)
siamese_dataset=SiameseNetworkDataset(imageFolderDataset=folder_dataset_test,
transform=transforms.Compose([transforms.Scale((100,100)),
transforms.ToTensor()
])
,should_invert=False)
test_dataloader=DataLoader(siamese_dataset,num_workers=6,batch_size=1,shuffle=True)
dataiter=iter(test_dataloader)
x0,_,_=next(dataiter)
foriinrange(10):
_,x1,label2=next(dataiter)
concatenated=torch.cat((x0,x1),0)
output1,output2=net(Variable(x0).cuda(),Variable(x1).cuda())
euclidean_distance=F.pairwise_distance(output1,output2)
imshow(torchvision.utils.make_grid(concatenated),\\\'Dissimilarity: {:.2f}\\\'.format(euclidean_distance.cpu().data.numpy()[0][0]))

模型的一些输出,较低的值表示相似度较高,较高的值表示相似度较低。
果然,实验结果相当不错。网络能够做到从图像中分辨出同一个人,即使这些图像是从不同角度拍摄的。与此同时,该网络在辨别不同的图像方面也做得非常好。
结论
我们讨论并实施了用一个孪生网络从面部图像对中进行面部识别的实验。当某个特定面部的训练样本很少(或只有一个)时,使用这个办法是非常有效的。我们使用一个有辨别性的损失函数来训练神经网络。
代码
点击此处获取该教程的完整代码。
本站微信群、QQ群(三群号 726282629):
