MobileNets进化史
2019-11-18 17:45:26
BDTC大会官网:https://t.csdnimg.cn/q4TY
一、MobileNets V1(2017)

论文链接:
https://arxiv.gg363.site/abs/1704.04861
摘要
为了处理移动和嵌入式视觉任务,本文提出了MobileNets模型。MobileNets基于流线型结构设计,利用深度可分离卷积来建立轻量级深度神经网络。MobileNets引入了两个超参数,让我们可以根据不同任务的条件约束,自由选择模型的尺度规模,通过这两个简单的全局超参数,MobileNets在速度和精度两方面实现了很好的均衡。实验证明,作为轻量级深度网络,MobileNets在诸如识别,定位,检测等计算机视觉任务中都具有普适性和有效性。
简介
为了获得更丰富,更多层次的特征,现有的卷积神经网络倾向于在网络宽度,深度方面做文章。这些方法固然提升了网络的性能,但同时也带来了复杂的网络结构和繁琐的参数设置,在算力,速度,存储空间上都有很大的不足,这些缺陷,也阻碍了一些理论上很好的网络架构在真实应用中的项目落地。
为了满足移动和嵌入式视觉任务的需要,MobileNets构造了一种高效的网络架构,同时引入两个超参数,以便构建体量小、延迟低的模型。
背景
MobileNets的设计主要建立在深度可分离卷积的知识上,所以先了解一下深度可分离卷积的思想,对下文MobileNets的理解有帮助。
深度可分离卷积,英文表述是Depthwise Separable Conv。下图是一个典型的深度可分离卷积结构,整体可以分为两大步骤:Depthwise Conv和PointwiseConv。与传统卷积相比,极大的减少了参数量。具体解释一下这两个步骤:
-
Depthwise Conv:按照通道数进行卷积,为每一个通道分配一个卷积核,得到的feature maps的维度为输入通道数。
-
将第一步得到的feature maps Concat起来,进行1x1卷积。得到最终深度可分离卷积的输出。
-
这样做,参数量是否真的减少了呢?我们可以用一个小模型举例:
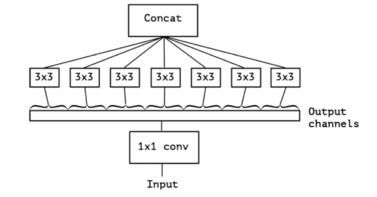
-
输入 feature map:W x H x 5
-
卷积核:3x3x3(共3个,每个尺寸为3x3的卷积核)
-
预期输出feature map:W x H x 3
(1)标准卷积:
parameters=3x3x5x3=135
(2)深度可分离卷积:
parameters=3x3x5+1x1x5x3=60
(3)两种卷积参数量对比:
![]()
可以看到,即使在卷积核数量很少,输入输出维度相差不大的情况下,参数量也减少了一般以上。如果卷积核数量增加,卷积越复杂,参数减少的效果会越明显。
MobileNet 结构
-
深度可分离卷积
在背景知识中,我们已经简单的介绍了关于深度可分离卷积的相关内容。MobileNets主要是依托其建立的,本节中,我们用具体的公式进行阐述和理解。
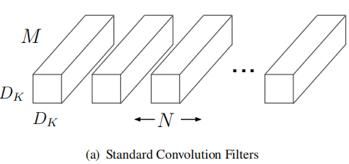
总体而言,深度可分离卷积可以看做是一种分解卷积的形式,它将标准卷积分解为深度卷积和点卷积(1x1卷积)。MobileNets中,在depthwise conv阶段,对于输入特征图的每一个通道都应用一个卷积核,然后在pointwiseconv阶段,利用1x1的卷积将第一步得到的featuremap结合起来,得到最终输出。一个标准卷积在一个步骤中过滤并将输入组合成一组新的输出,而在深度可分离卷积中,将此过程一分为二,首先进行滤波,然后进行合并。这种卷积分解的效果是大大减少了计算量和模型大小。具体可以表示为:
(a) 标准卷积:
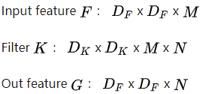
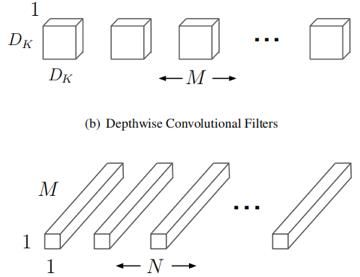
下图是标准卷积中的卷积核,共有N个卷积核,每一个卷积核的通道数等于输入feature的通道数
那么标准卷积的输出,可以表示为:
![]()
计算成本为:
![]()
标准卷积运算的作用是基于卷积核对特征进行滤波,并结合特征得到新的表示。
(b)深度可分离卷积
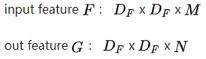
下图是深度可分离卷积的卷积核和点点卷积部分示意图。深度可分卷积由深度卷积和点卷积构成。使用深度卷积为每个输入通道应用一个卷积核。随后进行一个简单的1×1卷积,MobileNets对两个步骤都使用BN层和ReLU激活函数。
深度可分离卷积的输出,可以表示为:
![]()
计算成本,可以分两步表示:
depthwise Conv部分,计算成本为:
![]()
pointwise Conv部分,计算成本为:
![]()
那么,总的计算成本为:
![]()
可以比较一下两种卷积的参数量,深度可分离卷积参数:标准卷积参数比值为
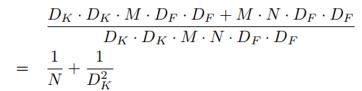
其中,N是卷积核的数量,Dk 是卷积核尺寸。从中也可以看出,卷积核数量越多,尺寸越大,参数减少量越显著。作者通过实验表明,MobileNet使用3×3深度可分离卷积,相比标准卷积,计算量减少了8到9倍,仅在精度上略有降低。
-
网络结构和训练
有了深度可分离卷积的基础,本小节主要探讨MobileNets的结构设计和具体训练情况。
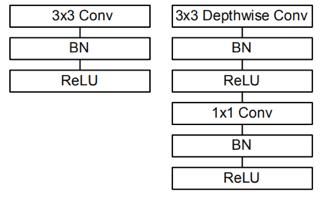
下图是MobileNet中一个块的结构,可以看到,相比传统卷积,MobileNet在depthwise Conv和pointwise Conv后面都加入了BN层和ReLu层。
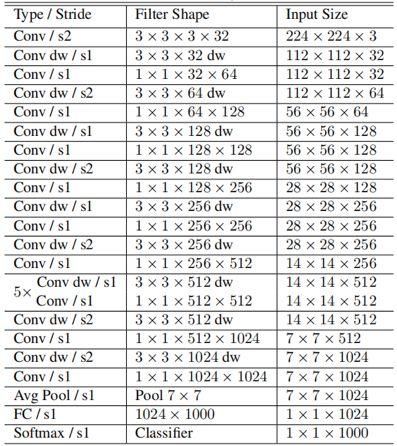
有了基本结构之后,我们可以看一下MobileNet主体的结构,如下表所示,S表示步长,用来下采样。
在训练上的要点有:
利用RMSprop优化算法,使用较少的正则化和数据扩充技术,因为小型模型的过拟合问题较少,在深度方向的滤波器上设置很小或没有权值衰减(l2正则化),因为它们的参数很少。
在摘要部分就提到,MobileNets引入了两个超参数,让我们可以根据不同任务的条件约束,自由选择模型的尺度规模,下面就来介绍一下这两个超参数。
-
Width Multiplier: Thinner Models
尽管基础的MobileNet结构已经具备了低延时,模型小的优势。但是有时候一个具体的案例或者应用可能会需要更小型、更快速的网络结构,这个时候,就需要我们根据基础的MobileNets灵活设计,因此,引入了第一个超参数,Width Multiplier α,宽度参数 α的作用是将每一层的网络变得更thin。对于一个给定的层,输入通道由 MM 变为αM,输出通道由 NN 变为 αN,那么相应的MobileNets的计算成本变为:
![]()
α的取值范围为(0,1],通常的取值有1,0.75,0.5和0.25。如果α取1的话,就是基础的MobileNets,如果 αpha <1,就是一个更thin的MobileNets。宽度参数的引入,大大减少了参数量,减少约 α^2。
-
Resolution Multiplier: Reduced Representation
宽度参数α能够让网络变得更thin,除此之外,MobileNets中还引入了第二个超参数,分辨率参数ρ来减少神经网络的计算成本。将分辨率参数应用到包括输入层的每一层网络中。同时应用宽度参数αph和分辨率参数 ρ之后,计算成本变为:
![]()
其中,ρ的范围是(0,1],通常通过 ρ的设置使得分辨率变为224,192,160或128。如果 ρ取1,就是基础MobileNets,如果 ρ<1,就是一个分辨率更小的MobileNets。宽度参数的引入,大大减少了参数量,减少约 ρ^2。
由于MobileNets v1是MobileNets系列的开山之作,所以我们介绍的比较详细,接下来的V2和V3,只针对创新点,具体算法和结构进行介绍。
二、MobileNets V2(2018)

论文链接:
http://openaccess.thecvf.com/content_cvpr_2018/html/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.html
创新点
-
Linear Bottlenecks
在高维空间上,诸如ReLU这种激活函数能有效增加特征的非线性表达,但是仅限于在高维空间中,如果维度降低,到了低维空间,再加入ReLU则会破坏特征,如下图所示,当把原始输入维度增加到15或30后再作为ReLU的输入,输出恢复到原始维度后不会丢失太多的输入信息;相比之下如果原始输入维度只增加到2或3后再加上ReLU进行非线性转化,输出恢复到原始维度后信息丢失较多。

基于这些结论,作者在MobileNets v2中提出了Linear Bottlenecks结构,也就是在执行了降维的卷积层后面,不再加入类似ReLU等的激活函数进行非线性转化,这样做的目的也是尽可能的不造成信息丢失。
-
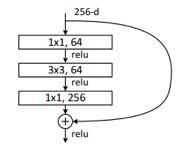
Inverted residuals
在ResNet中,为了构建更深的网络,提出了ResNet的另一种形式,bottleneck,结构如下所示,一个bottleneck由一个1x1卷积(降维),3x3卷积和1x1卷积(升维)构成。
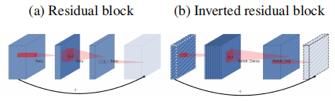
但是这种先降维后升维的顺序不太适合MobileNets,因为在MobileNets中的深度可分离卷积中,Depthwise Conv卷积的层数是输入通道数,本身就比较少,如果跟残差网络中的bottleneck一样,先压缩,后卷积提取,可得到的特征就太少了。因此,本文采取了一种逆向的方法,先升维,卷积,再降维,称为Inverted residuals。如下图所示,(a)在残差网络block中,先降维后卷积升维,而在Inverted residual block中,先升维,再卷积降维。
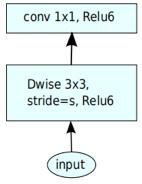
网络结构
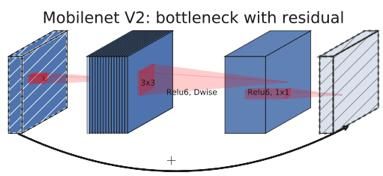
在MobileNets v2中,基本的结构组成是一个带残差的深度可分离卷积bottleneck。
先回顾一下MobileNets v1的结构,非常的简洁,基于深度可分离卷积,先进行depthwiseconv,再进行pointwise conv。得到最终的输出特征。
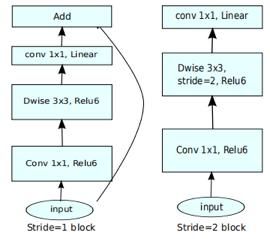
而在MobileNets v2中,引入了Linearbottlenecks和Inverted Residuals等结构,可以看到,在原先的基础上,再进行depthwiseconv之间,先进行了一个1x1卷积,用于升维,而且在降维操作后,不再接入ReLU等非线性激活函数。当且仅当输入输出层维度相同时,才利用shortcut进行连接。因此有下图两种结构
三、MobileNets v3(2019)

*在MobileNets中还有关于网络搜索部分的论述说明,这里不做过多介绍,感兴趣可点击原文阅读。
论文链接:
https://arxiv.gg363.site/abs/1905.02244
MobileNets V1引入深度可分卷积作为传统卷积层的有效替代。深度可分离卷积通过将空间滤波与特征生成机制分离,有效地分解了传统卷积。深度可分卷积由两个独立的层定义:用于空间滤波的轻量级深度卷积和用于生成特征的1x1点卷积,通过独立层的定义,有效地减少了参数量,提升运行效率。
MobileNets v2 引入了linear bottleneck和Inverted residual结构,很好的扩展了MobileNets v1,如下图所示,v2由1x1升维、深度卷积和1x1降维组成。当且仅当输入和输出具有相同数量的通道时,才使用residual连接进行连接。这种结构在输入和输出处保持了一种紧凑的表示,同时在内部扩展到高维特征空间,以增加非线性全通道转换的表现力。
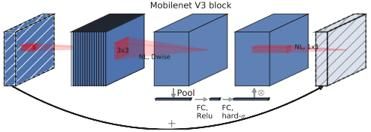
在MobileNets的基础上,MnasNet在在bottleneck结构中引入了基于挤压和激励的轻量级注意力模块。进一步对MobileNetsv2进行了扩展。
创新点
MobileNets v3博采众长,使用这些层的组合作为构建块,以构建最有效的模型。如下图所示,综合了以上三种模型的思想:MobileNets V1的深度可分离卷积,MobileNets V2的线性bottleneck和逆残差结构,MnasNet的基于挤压和激励结构的轻量级注意力模型。
-
激活函数swish
谷歌在2017提出的h-swish是基于swish激活函数的改进,所以先了解一下swish。
(1)表达式:
(2)图像:
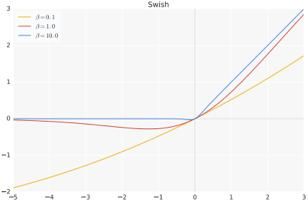
(3)优势:Swish具备无上界有下界、平滑、非单调的特性。并且Swish在深层模型上的效果优于ReLU。
但是在MobileNets v3中,作者认为在轻量级的架构中,swish会增加运算成本,于是提出了h-swish进行替代。
-
新的激活函数h-swish
作者认为,可以用一个近似函数逼近swish中的σ部分,减少运行成本。
![]()
网络结构
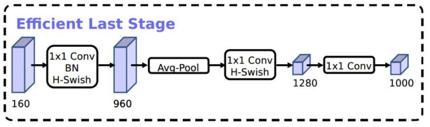
如下图所示,在MobileNets v2使用1×1卷积来构建最后层,能得到更高维的特征空间。在预测时,能提取到更丰富的特征,但是同时也引入了额外的计算成本与延时。
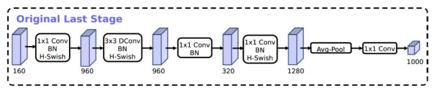
因此,作者的想法是在保留高维,具有丰富特征的前提下,尽量减少时延,具体改进如下图所示,将带有h-wise的1x1层放在平均池化层之后。
自2017年v1版本发布以来,谷歌家的MobileNets系列一直是轻量级网络中的翘楚,经过三个版本的更新迭代,MobileNets早已成为在移动端部署深度卷积网络的代表算法。本文按照时间线,梳理MobileNet三个版本的核心算法思想,并探讨更新过程中的具体改进,希望通过此文,我们能够对MobileNets有一个更清晰直观的了解。