赠书 | 新手指南——如何通过HuggingFace Transformer整合表格数据


作者 | Ken Gu
翻译| 火火酱~,责编 | 晋兆雨
出品 | AI科技大本营
头图 | 付费下载于视觉中国
*文末有赠书福利
不可否认,Transformer-based模型彻底改变了处理非结构化文本数据的游戏规则。截至2020年9月,在通用语言理解评估(General Language Understanding Evaluation,GLUE)基准测试中表现最好的模型全部都是BERT transformer-based 模型。如今,我们常常会遇到这样的情形:我们手中有了表格特征信息和非结构化文本数据,然后发现,如果将这些表格数据应用到模型中的话,可以进一步提高模型性能。因此,我们就着手构建了一个工具包,以方便后来的人可以轻松实现同样的操作。
 在Transformer的基础之上进行构建
在Transformer的基础之上进行构建
使用transformer的主要好处是,它可以学习文本之间的长期依赖关系,并且可以并行地进行训练(与sequence to sequence模型相反),这意味着它可以在大量数据上进行预训练。
鉴于这些优点,BERT现在成为了许多实际应用程序中的主流模型。同样,借助HuggingFace Transformer之类的库,可以轻松地在常见NLP问题上构建高性能的transformer模型。
目前,使用非结构化文本数据的transformer模型已经为大众所熟知了。然而,在现实生活中,文本数据往往是建立在大量结构化数据或其他非结构化数据(如音频或视觉信息)的基础之上的。其中每一种数据都可能会提供独一无二的信号。我们将这些体验数据(音频、视频或文本)的不同方式称为模态。
以电商评论为例。除了评论文本本身之外,还可以通过数字和分类特征来获取卖家、买家以及产品的相关信息。
在本文中,我们将一起学习如何将文本和表格数据结合在一起,从而为自己的项目提供更强的信号。首先,我们将从多模态学习领域开始——该领域旨在研究如何在机器学习中处理不同的模态。
 多模态文献综述
多模态文献综述
目前的多模态学习模式主要集中在听觉、视觉和文本等感官模态的学习上。
在多模态学习中,有多个研究分支。根据卡内基梅隆大学(Carnegie Mellon University)MultiComp实验室提出的分类方法,我们要处理的问题属于多模态融合(Multimodal Fusion)问题——如何将两种或两种以上的模态信息结合起来进行预测。
由于文本数据是我们的主模态,因此我们将重点关注以文本作为主要模态的文献,并介绍利用transformer架构的模型。
 结构化数据的简单解决方案
结构化数据的简单解决方案
在深入研究各文献之前,我们可以采取一个简单的解决方案:将结构化数据视为常规文本,并将其附加到标准文本输入中。以电商评论为例,输入可构建如下:Review. Buyer Info. Seller Info. Numbers/Labels. Etc.不过,这种方法有一个缺点,那就是它受到transformer所能处理的最大令牌长度的限制。
 图像和文本Transformer
图像和文本Transformer
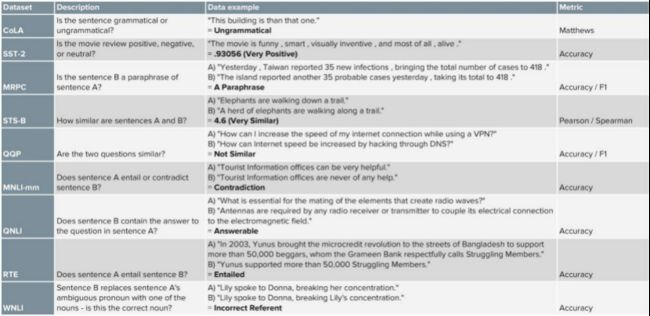
在过去的几年中,用于图像和文本的transformer扩展取得了显著的进步。Kiela等人在2019年发表的论文《Supervised Multimodal Bitransformers for Classifying Images and Text》中,将预训练的ResNet和预训练的BERT分别应用在非模态图像和文本上,并将其输入双向transformer。其关键性创新是将图像特征作为附加令牌应用到transformer模型中。 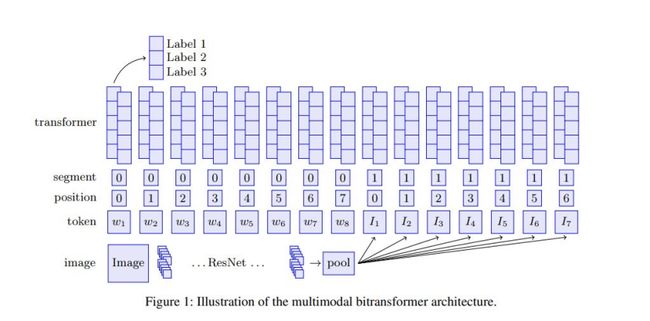 此外,ViLBERT(Lu et al.,2019)和VLBert(Su et al.,2020)等模型对图像和文本的预训练任务进行了定义。这两个模型都在Conceptual Captions数据集上进行了预训练,该数据集中包含大约330万幅图像-标题对(带有alt文本标题的网络图像)。以上两个模型,对于给定的图像,预训练对象检测模型(如Faster R-CNN)会获取图像区域的向量表示,并将其视为输入令牌嵌入到transformer模型中。
此外,ViLBERT(Lu et al.,2019)和VLBert(Su et al.,2020)等模型对图像和文本的预训练任务进行了定义。这两个模型都在Conceptual Captions数据集上进行了预训练,该数据集中包含大约330万幅图像-标题对(带有alt文本标题的网络图像)。以上两个模型,对于给定的图像,预训练对象检测模型(如Faster R-CNN)会获取图像区域的向量表示,并将其视为输入令牌嵌入到transformer模型中。
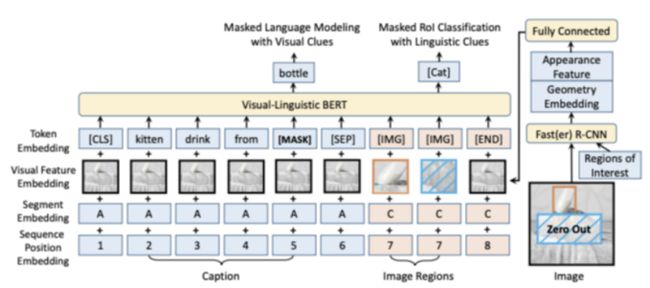
例如,ViLBert对以下目标进行了预训练:
1. 遮蔽多模态建模:遮蔽输入图像和单词令牌。对于图像,模型会预测对应图像区域中捕获图像特征的向量;而对于文本,则根据文本和视觉线索预测遮蔽文本。
2. 多模态对齐:预测图像和文本是否匹配对齐,即是否来自同一图像-标题对。
预训练任务的图像和遮蔽多模态学习示例如下所示:对于给定图像和文本,如果我们把dog遮蔽掉的话,那么模型应该能够借助未被遮蔽的视觉信息来正确预测被遮蔽的单词是dog。
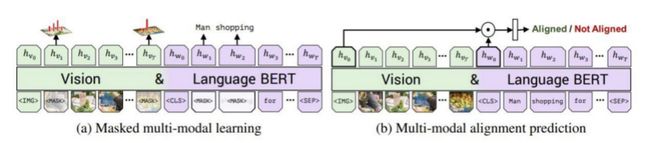
 所有模型都使用了双向transformer模型,这是BERT的骨干支柱。不同之处在于模型的预训练任务和对transformer进行的少量添加。在ViLBERT的例子中,作者还引入了一个co-attention transformer层,以明确定义不同模态之间的attention机制。
所有模型都使用了双向transformer模型,这是BERT的骨干支柱。不同之处在于模型的预训练任务和对transformer进行的少量添加。在ViLBERT的例子中,作者还引入了一个co-attention transformer层,以明确定义不同模态之间的attention机制。
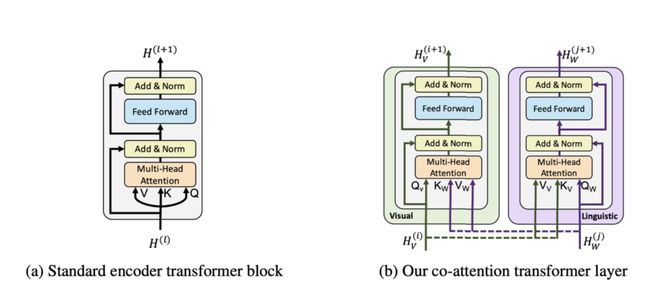 最后,还有由Tan和Mohit于2019年发表的LXMERT——另一个预训练transformer模型,从Transformer 3.1.0版本开始,它已经实现为库的一部分了。LXMERT的输入与ViLBERT和VLBERT相同。但是,LXMERT在聚合数据集上进行预训练,其中也包括视觉问答数据集。LXMERT总共对918万个图像-文本对进行了预训练。
最后,还有由Tan和Mohit于2019年发表的LXMERT——另一个预训练transformer模型,从Transformer 3.1.0版本开始,它已经实现为库的一部分了。LXMERT的输入与ViLBERT和VLBERT相同。但是,LXMERT在聚合数据集上进行预训练,其中也包括视觉问答数据集。LXMERT总共对918万个图像-文本对进行了预训练。
音频、视频、文本对准Transformers
除了用于组合图像和文本的transformer之外,还有针对音频、视频和文本模态的多模态模型。这方面的论文有Tsai等人于2019年发表的《MulT, Multimodal Transformer for Unaligned Multimodal Language Sequences》,以及Rahman等人于2020年发表的《Multimodal Adaptation Gate (MAG) from Integrating Multimodal Information in Large Pretrained Transformers》。
与ViLBert类似,MuIT中也在模态对中采用了co-attention机制。同时,MAG希望通过门控机制在某些transformer层中注入其他模态信息。
文本和知识图谱嵌入式Transformer
有一些研究还将知识图谱看作除文本数据之外的另一重要信息。在Ostendorff等人于2019年发表的《Enriching BERT with Knowledge Graph Embeddings for Document Classification》中,除了元数据特征外,还使用Wikidata 知识图谱中作者实体特征进行图书类别分类。在进入最终分类层之前,模型会将这些特征、书名和描述的BERT输出文本特征进行简单组合。
关键要点
采用针对多模态数据的transformer的目的是要确保多模态之间有attention或权重机制。attention机制可以发生在transformer架构的不同位置,例如编码输入嵌入、在中间注入、或在transformer对文本数据进行编码后进行组合。
 多模态Transformers工具包
多模态Transformers工具包
我们利用从文献综述以及最先进的transformer综合HuggingFace库中学到的知识,开发了一个工具包。该多模态-transformer包拓展了所有HuggingFace 表格数据transformer。欢迎大家点击下方链接查看代码、文档和工作示例。
(链接:
https://github.com/georgianpartners/Multimodal-Toolkit?ref=hackernoon.com)
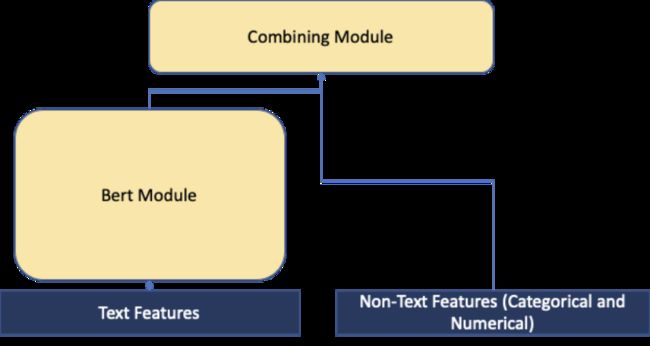
在更高的层面上,文本数据以及包含分类和数字数据表格特征的transformer模型输出会在组合模块中进行组合。由于我们的数据中没有对齐,所以我们选择在transformer输出之后对文本特征进行组合。组合模块实现了多种整合模态的方法,包括attention和门控方法。点击下方链接,获取更多相关细节。
(链接:
https://multimodal-toolkit.readthedocs.io/en/latest/notes/combine_methods.html?ref=hackernoon.com)
 演练
演练
下面,我们将通过一个服装评论推荐示例进行演练。我们将使用Colab笔记本中示例的简化版本,利用Kaggle上的女装电商服装评论,其中包含23000条客户评论。
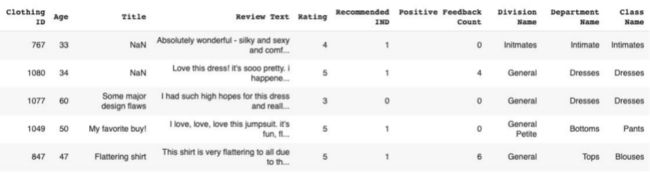 该数据集中,在标题和评论文本列中有文本数据,在“服装ID”、“部门名称”、和“类别名称”列中有分类特征,在“评级”和“好评数”中有数字特征。
该数据集中,在标题和评论文本列中有文本数据,在“服装ID”、“部门名称”、和“类别名称”列中有分类特征,在“评级”和“好评数”中有数字特征。
加载数据集
首先,我们将数据加载到TorchTabularTextDataset中,与PyTorch的数据加载器配合作业,包括HuggingFace Transformers文本输入、我们指定的分类特征列和数字特征列。为此,我们还需要加载HuggingFace tokenizer.。
 加载表格模型Transformer
加载表格模型Transformer
接下来,我们用表格模型加载transformer。首先,在TabularConfig对象中指定表格配置。然后将其设置为HuggingFace transformer 配置对象的tabular_config成员变量。这里,我们还要指定表格特性与文本特性的结合方式。在本例中,我们将使用加权和的方法。
在设置好tabular_config集之后,我们就可以使用与HuggingFace相同的API来加载模型。点击下方链接,了解当前包含该表格组合模块的transformer模型列表。
(列表链接:
https://multimodal-toolkit.readthedocs.io/en/latest/modules/model.html?ref=hackernoon.com#module-multimodal_transformers.model.tabular_transformers)

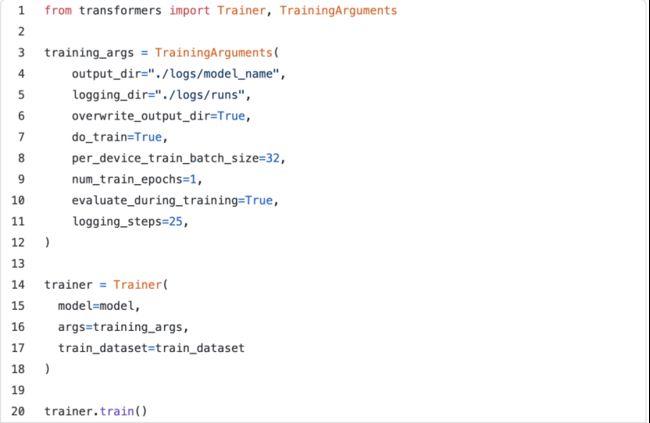
训练
这里,我们可以使用HuggingFace的Trainer。需要指定训练参数,在本例中,我们将使用默认参数。
 一起来看看训练中的模型吧!
一起来看看训练中的模型吧!
 结果
结果
我们还使用该工具包对女性电商服装评论数据集进行了推荐预测实验,对墨尔本Airbnb开放数据集进行了价格预测实验。前者是一个分类任务,而后者是一个回归任务,结果如下表所示。text_only combine方法是仅使用transformer的基线,本质上与SequenceClassification模型的HuggingFace相同。
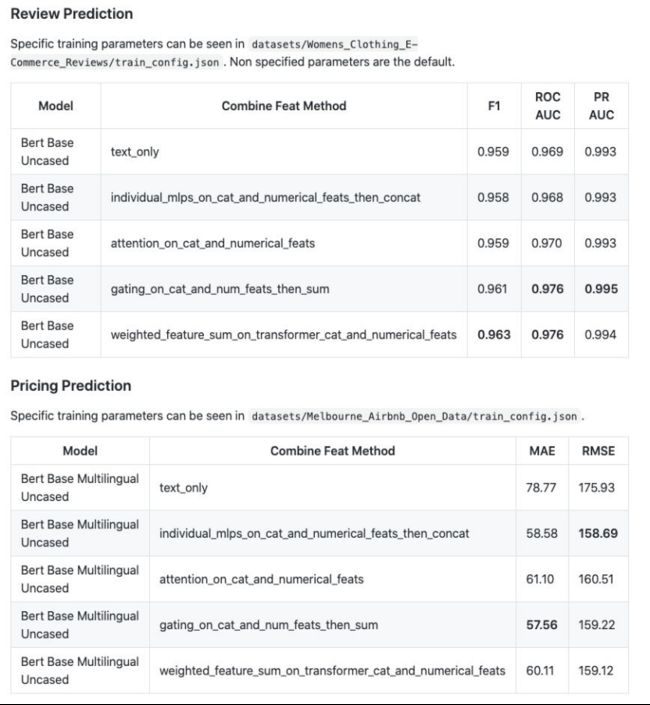
不难看出,相比于纯文本方法,表格特征的加入有助于提高性能。此外,表格数据的训练信号越强,性能越好。例如,在评论推荐案例中,纯文本模型就已经是非常强大的基线了。

下一步工作
我们已经在自己的项目中成功使用了这个工具箱,也欢迎大家在自己的下一个机器学习项目中进行试用!
快速回顾一下本文中提到的论文:
图像和文本Transformer
Supervised Multimodal Bitransformers for Classifying Images and Text (Kiela et al. 2019)
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks (Lu et al. 2019)
VL-BERT: Pre-training of Generic Visual-Linguistic Representations (Su et al. ICLR 2020)
LXMERT: Learning Cross-Modality Encoder Representations from Transformers (Tan et al. EMNLP 2019)
音频、视频、文本对准Transformers
Multimodal Transformer for Unaligned Multimodal Language Sequences (Tsai et al. ACL 2019)
Integrating Multimodal Information in Large Pretrained Transformers (Rahman et al. ACL 2020)
知识图谱嵌入式Transformers
Enriching BERT with Knowledge Graph Embeddings for Document Classification (Ostendorff et al. 2019)
ERNIE: Enhanced Language Representation with Informative Entities (Zhang et al. 2019
原文链接:
https://hackernoon.com/a-beginner-guide-to-incorporating-tabular-data-via-huggingface-transformers-052i3zko
本文由AI科技大本营翻译,转载请注明出处
#欢迎留言在评论区和我们讨论#

看完本文,对于表格数据处理你有什么想说的?
欢迎在评论区留言
我们将在 12 月 3 日精选出 3 条优质留言
赠送《Python数据科学实践》纸质书籍一本哦!

更多精彩推荐
U^2-Net跨界肖像画,完美复刻人物细节,GitHub标星2.5K+
Python画出心目中的自己
清华、北大教授同台激辩:脑科学是否真的能启发AI?
想在边缘运行计算机视觉程序?先来迎接挑战!
你熟知的开源项目,幕后推手竟然是他们?