模型精度不降反升!我们是这样改进PACT量化算法的
点击左上方蓝字关注我们

随着人工智能应用在手机、IoT上的普及,受能耗和设备体积的限制,端侧硬件的计算性能和存储能力相对较弱,这给人工智能模型带来了新的挑战——需要模型更小更快更强。量化,就是其中的一个重要手段。因此,近年来量化成为学术界与工业界热门的研究方向。但与此同时,模型量化也引发了巨大的挑战。其中比较大的有两个:一是由于表示精度下降引起信息损失带来准确率的下降;二是量化带来的不连续性使神经网络的训练不稳定。学术和工业界的大多数工作也正是围绕它们展开的。
模型量化简单来说就是用更低比特数据(如8位整型)代替原浮点数据(32位)。听上去似乎是非常简单,但是实际操作下来会发现这个坑远远比想象中的大。量化最核心的挑战,是如何在减少模型数据位宽的同时,模型的准确度不要掉下来,也就是在压缩率与准确率损失间作trade-off。这衍生出很多有趣的子问题,比如量化对象是谁(weight,activation,gradient),量化到几位(8位,4位,2位,1位),量化参数选哪些(如moving rate,clipping value),量化参数是否可以自动优化,不同层是否需要不同的量化参数,如何在量化后恢复准确率或者在训练时考虑量化,等等……
PACT量化(PArameterized Clipping acTivation)是一种新的量化方法,该方法通过在量化激活值之前去掉一些离群点,将模型量化带来的精度损失降到最低,甚至比原模型准确率更高。想知道背后的原理吗?接下来,我带大家详细解读一下此算法。
量化的好处
量化是将以往用32bit或者64bit表达的浮点数用8bit、16bit甚至1bit、2bit等占用较少内存空间的形式进行存储。这样的好处是:
减少模型体积,降低模型存储空间需求;
降低内存带宽需求;
加速计算。现代移动端设备,基本都支持SIMD(单指令流多数据流),以128-bit 寄存器为例,单个指令可以同时运算 4个32位单精度浮点,或者8个16 位整型,或者16个8位整型。显然8位整型数在 SIMD 的加持下,运算速率要更快。
量化面临的最大问题
——精度受损
量化映射方式
通常,模型量化是将32bit浮点数转换成8bit整数,映射过程分为三种方式:
非饱和方式:将浮点数正负绝对值的最大值对应映射到整数的最大最小值。
饱和方式:先计算浮点数的阈值,然后将浮点数的正负阈值对应映射到整数的最大最小值。
仿射方式:将浮点数的最大最小值对应映射到整数的最大最小值。
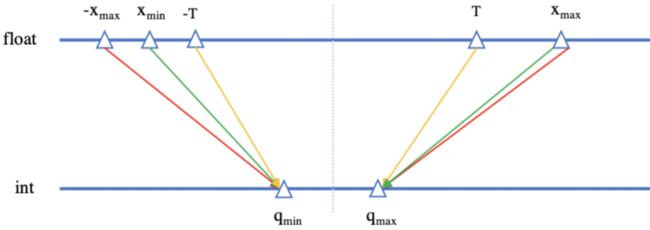
红色代表非饱和方式,黄色代表饱和方式,绿色代表仿射方式
量化精度损失原因
无论哪种映射方式,都会受到离群点、float参数分布不均匀的影响,造成量化损失增加。
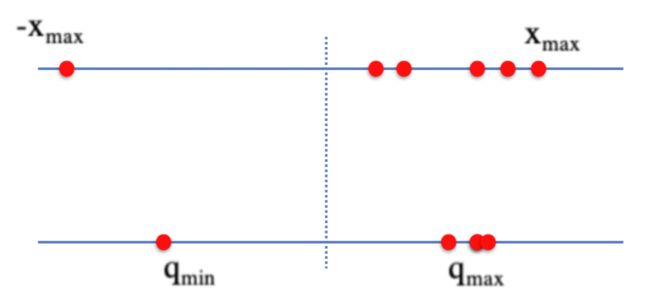
如上图,由于左侧的离群点,使得量化的范围更大,让量化后的右侧数值点变的过度密集,增大了量化损失。
以实际模型为例,下图的分布直方图,取自经典的CNN模型MobileNetV3中的一部分激活值,可以看到它的分布十分不均匀,最小值和最大值分别是-60和+80,但是绝大多数数据都分布在-20到+20之间。
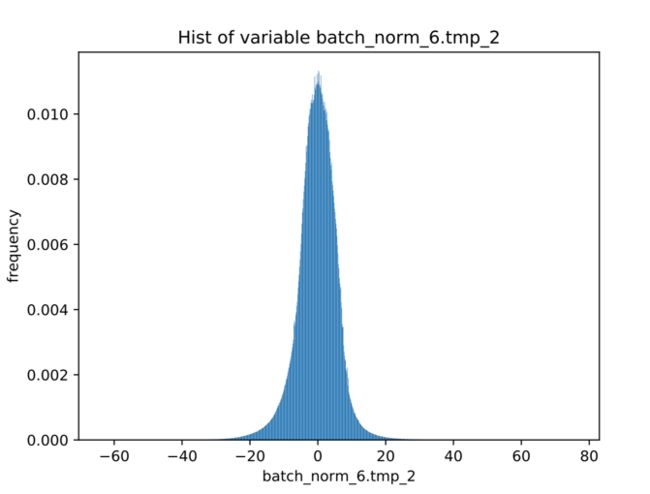
如果按照-60到+80的范围去确定量化scale,就会对分布密集的-20到+20范围带来较大的量化损失。
PACT量化原理
模型量化主要包括两个部分,一是对权重Weight量化,一是针对激活值Activation量化。同时对两部分进行量化,才能获得最大的计算效率收益。权重可以借助网络正则化等手段,让权重分布尽量紧凑,减少离群点、不均匀分布情况发生,而对于激活值还缺乏有效的手段。
PACT量化(PArameterized Clipping acTivation)是一种新的量化方法,该方法提出在量化激活值之前去掉一些离群点来降低模型量化带来的精度损失。提出方法的背景是作者发现:“在运用权重量化方案来量化activation时,激活值的量化结果和全精度结果相差较大”。作者发现,activation的量化可能引起的误差很大(相较于weight基本在 0到1范围内,activation的值的范围是无限大的,这是RELU的结果),所以提出截断式RELU 的激活函数。该截断的上界,即α 是可学习的参数,这保证了每层能够通过训练学习到不一样的量化范围,最大程度降低量化带来的舍入误差。

如上图,PACT解决问题的方法是,不断裁剪激活值范围,使得激活值分布收窄,从而降低量化映射损失。
PACT通过对激活数值做裁剪,从而减少激活分布中的离群点,使量化模型能够得到一个更合理的量化scale,降低量化损失。
PACT的公式如下所示:

可以看出PACT原始的思想是用PACT代替ReLU函数,对大于零的部分进行一个截断操作,截断阈值为a。
PaddleSlim改进版
PACT量化实现
实际应用场景中,各种模型结构并不一定都是用ReLU,为了使PACT方法能够得到更广泛的应用,就需要我们对其进行一定改进。改进后的PACT公式如下:

优势:飞桨推出的PaddleSlim提供了改进版的PACT方法,在激活值和待量化的OP(卷积,全连接等)之间插入这个PACT预处理,不只对大于0的分布进行截断,同时也对小于0的部分做同样的限制,从而更好地得到待量化的范围,降低量化损失。同时,截断阈值是一个可训练的参数,在量化训练过程中,模型会自动的找到一个合理的截断阈值,从而进一步降低量化精度损失。
下面我们使用具体实例给大家展示一下PACT量化的收益情况。
PaddleSlim改进版
PACT量化的收益展示
MobileNetV3模型Pact量化收益
MobileNetV3,作为MobileNet系列模型的集大成者,结合了MobileNetV1 模型的深度可分离卷积(depthwise separable convolutions), MobileNetV2 模型引入的具有线性瓶颈的倒残差结构(the inverted residual with linear bottleneck)和MnasNet 模型引入的基于squeeze and excitation结构的轻量级注意力模型,吸取众多模型之长,结合采用神经网络搜索的方法,是当前最理想的移动端轻量级模型之一。
为了打造嵌入式终端上”毫秒级”的深度学习应用,我们尝试对MobileNetV3进行量化操作。
然而,在实际的量化实验中,我们发现:MobileNetV3模型对量化极为敏感,一般的离线量化或量化训练带来的精度损失都很大,几乎达到了不可用的程度。但使用PACT量化策略后,可以明显解决这一问题。实验结果如下表所示。

使用普通的在线量化策略,训练过程中损失函数波动明显,最终量化损失大于10%,这么大的损失显然已经超过了常规深度学习任务所能容忍的范围。
使用PACT量化策略后,训练过程损失函数收敛稳定,最终模型精度达到77.5%,精度损失1.4%,显著好于普通量化策略。
OCR模型PACT量化收益
本次实验选取的是PaddleOCR主打的文本检测和识别以及方向分类模型。其中识别模型基于CRNN结构,原模型大小4.5M(包含参数文件和模型结构信息),识别准确率为66.49%; 检测模型基于DB结构,原模型大小2.5M, 原模型检测hmean评价指标为74.4;方向分类器基于MobileNetV3模型,原模型大小0.9M,分类准确率为94.03%。
我们可以用下图所示的流程对OCR模型进行量化压缩,本次我们使用的是PACT在线量化方案。
通过PACT在线量化,可以在不过分损伤模型准确率的前提下,降低模型的大小,提高预测性能。

量化后,识别模型大小从4.5M缩减到1.5M,识别准确率为65.33%,量化损失相对较小;检测模型大小从2.5M缩减到1.4M,检测hmean指标为74.9,PACT量化不仅没有降低模型精度反而带来了0.5%的提升;方向分类模型大小从0.9M缩减到0.45M,分类准确率为94.65%,量化同样带来了0.62%的精度提升。我们可以发现,合理使用量化方法,不仅不会对模型准确率带来过多损伤,甚至在一些场景下会带来一定的提升,同时可以享受模型体积缩小和预测速度提高带来的便利。

检测模型PACT量化精度收益
与OCR量化方法相同,我们对PaddleDetection中的Yolo模型进行PACT量化。相比普通的在线量化方法,PACT量化可以有效地降低目标检测任务上的量化损失。
经过实践数据可以了解到,移动端的目标检测模型YOLOv3-MobileNetV3,在COCO任务上,如果使用普通在线量化方法,MAP为28.2;但使用PACT量化可以降低量化损失,MAP为28.8。服务器端的大型检测模型PPYOLO-ResNet50vd如果使用普通在线量化方法,MAP为43.2;但使用PACT后MAP可以达到44.1。由此可以看出,PACT在目标检测任务上也有不错的表现。

从上面分类,OCR,检测三类实验我们已经发现,PACT量化方法相比普通量化,训练方法更稳定,最终的量化损失也更小。
PaddleSlim改进版
PACT量化的实现步骤
PACT量化功能来自飞桨PaddleSlim模型压缩工具库。PaddleSlim是一个模型压缩工具库,不仅支持PACT量化,还包含模型剪裁、知识蒸馏、超参搜索和模型结构搜索等一系列模型压缩策略。
使用PaddleSlim对模型进行PACT量化操作只需要以下4步:
选择量化配置
转换量化模型
启动量化训练
保存量化模型
下面分别对这几点进行讲解:
1. 选择量化配置
首先我们需要对本次量化的一些基本量化配置做一些选择,例如weight量化类型,activation量化类型等。如果没有特殊需求,可以直接拷贝我们默认的量化配置。全部可选的配置可以参考PaddleSlim量化文档,例如我们用的量化配置如下:

2. 转换量化模型
在确认好我们的量化配置以后,我们可以根据这个配置把我们定义好的一个普通模型转换为一个模拟量化模型。我们根据量化原理中介绍的PACT方法,定义好PACT函数pact和其对应的优化器pact_opt。在这之后就可以进行转换,转换的方式也很简单:

3. 启动量化训练
得到了量化模型后就可以启动量化训练了,量化训练与普通的浮点数模型训练并无区别,无需增加新的代码或逻辑,直接按照浮点数模型训练的流程进行即可。
4. 保存量化模型
量化训练结束后,我们需要对量化模型做一个转化。PaddleSlim会对底层的一些量化OP顺序做调整,以便预测使用。转换及保存的基本流程如下所示:

参考链接
上文提到的三个PACT量化实例链接如下。
MobileNetV3 PACT:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/demo/quant/pact_quant_aware
OCR PACT:
https://github.com/PaddlePaddle/PaddleOCR/tree/develop/deploy/slim/quantization
Detection PACT:
https://github.com/PaddlePaddle/PaddleDetection/tree/master/slim/quantization
PACT量化功能来自飞桨PaddleSlim模型压缩工具库,除了PACT量化,PaddleSlim还提供模型剪裁、知识蒸馏、超参搜索和模型结构搜索等一系列模型压缩策略,详细介绍请参阅以下文档。
如果您对飞桨的模型压缩感兴趣,欢迎加飞桨小哥哥的微信,回复paddleslim,进入技术交流群。

如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨PaddleSlim项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddleSlim
Gitee:
https://Gitee.com/PaddlePaddle/PaddleSlim
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。

扫描二维码 | 关注我们
微信号 : PaddleOpenSource
END
精彩活动