CTPN论文笔记
Connectionist Text Proposal Network (CTPN)。本文我基本是参考原论文翻译总结的。原论文是《Detecting Text in Natural Image with Connectionist Text Proposal Network》
2.1.1.与RPN比较
RPN在识别物体方面很好,但在文字方面不行,因为物体识别目前不需要太精确就能判断出物体类别,而文字识别需要非常的精确。
2.1.2.CTPN特点介绍
1.通过识别一系列小框框文字,分别给于文字分数、非文字分数,然后将他们结合在一起进行预测。
2.In-network 循环网络直接应用于卷积神经网络提取的图片特征。
3.可以同时处理一张图片中的多个文字,以及同时处理多种语音文字。
4.速度、精度都高,0.88 F-measure over 0.834 on the ICDAR 2013, and 0.61 F-measure over 0.54 in on the ICDAR 2015。速度达到0.14s/image。
2.1.3.以前识别方法回顾
1.文本识别,以前大体有两种,一种是connected-components (CCs) based approaches ,一种是 sliding-window based methods。
CCs只是抽取了一些低水平的参数,比如亮度、颜色、斜度。
sliding-window based methods是靠很多不同大小的窗口来获取文字或非文字窗口,而这些窗口又靠预训练好的识别器来识别。
2.物体识别:主要就是RPN了,以 Fast R-CNN model 为最为出名。
2.1.4.CTPN详细说明

1.16像素固定宽度。用16像素固定宽度的竖框来分析,而不是识别每个文字,因为容易混淆到底是单个文字的一部分,还是多个文字的组合。这种方法可以应用在不同大小的文字上。使用的VGG16提取的特征,当然也可以用其他模型。主要集中在纵坐标(y)的预测。

2.BLSTM。利用循环网络RNN来识别这些16像素宽度各个框的相关度,从而识别文字间的关联。下图可以看出来有RNN和没有RNN的区别。论文中使用的RNN是a bi-directional LSTM。


3.边界优化。毕竟是要将一堆16像素宽度的竖框合并在一起,来准确判断文字的长度。所以又加入了横坐标(x,宽度)方面的预测,来提升文字边界。

下图可以看出来加边界优化(红色框)和没加边界优化(黄色虚线框)的差异。

2.1.5.损失函数
L cl , L re and l re o , 分别代表文字/非文字分数 计算错误、坐标计算错误、边界计算错误.如CPTN框架图最后的三个输出(2k个文字/非文字分数、2k个坐标、k个边界)

2.1.6.CTPN准备训练数据说明
我在博客https://blog.csdn.net/zephyr_wang/article/details/104200499中描述了cptn的安装与运行。下面说下训练数据的准备。
1.初始数据
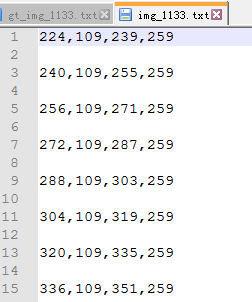
以下图为例,image(img_1133)就是这个图片了,label(gt_img_1133)数据是我标红色的坐标,x1,y1,x2,y2,x3,y3,x4,y4分别是224,109,704,109,704,259,224,259。

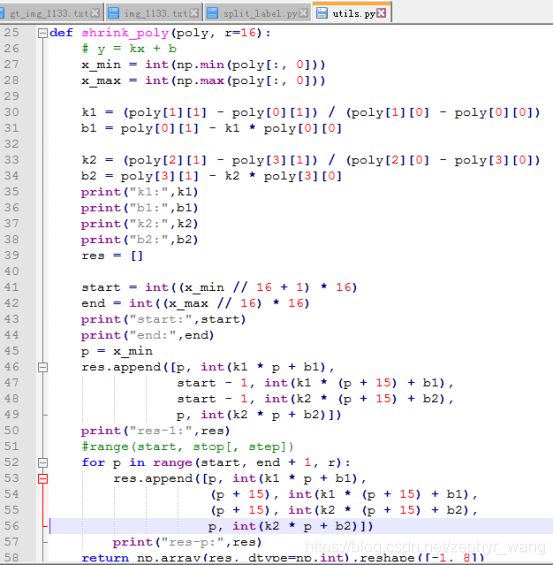
2.用gt_img_1133数据生成cptn需要的label。Cptn是需要16像素宽度的。
运行python ./utils/prepare/split_label.py就会生产最终需要的label了。
因为我的y1-y2=0,y3-y3=0,即高度相同,所以只是把这个长方形(x1,y1,x2,y2,x3,y3,x4,y4)按x坐标拆成一堆16像素宽度的anchor。最终label如下图所示。

3.split_label.py其实主要调用本目录utils的shrink_poly来生成最终label,代码截取如下。