快速上手的Python版二维卡尔曼滤波解析
卡尔曼滤波是最好的线性滤波,但是需要推导的公式教多,也很细,这里推荐一个B站博主视频讲解的关于卡尔曼滤波,讲的很好,很细,适合小白学习,链接地址为:添加链接描述。如果完全没接触过卡尔曼滤波的,建议从第一集开始学习。
下面是我跟着这位博主学习后,再加上其他大神写的代码,融入我自己的理解,对代码进行修改后的版本,每一个部分都有详细的注释,更加的通俗易懂,希望能帮助到需要快速上手卡尔曼滤波的学习者。
卡尔曼的本质就下面五个公式:
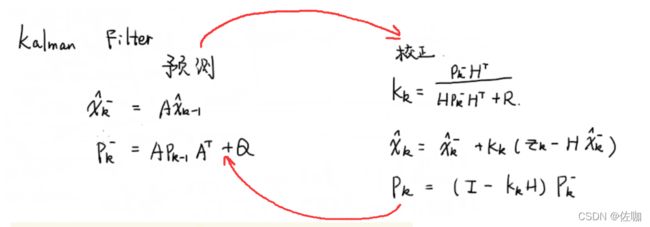
参数说明,见下:
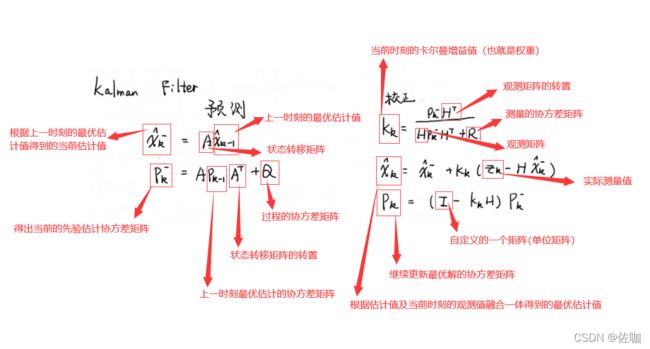
在卡尔曼滤波中需要调的参数主要有两个:
(1)Q矩阵:过程的协方差矩阵。注意:过程的协方差越小,说明预估的更准确,更可信。
(2)R矩阵:测量的协方差矩阵。注意:测量的协方差矩阵越小,说明测量的结果更准确,更可信。

怎么理解呢,假设你的测量设备是几万元或几千元的,测量值的可靠度较高(测量值的权值占比就需要较大),那么你的R矩阵就定义的小一些,比如定义为[[0.1,0],[0,0.1],这时候Q矩阵就可以定义的大一些,比如定义为[[1,0],[0,1]]。
如果你是使用的测量设备是某宝9.9元包邮的,那么你就应该相信估计值(估计值的权重占比就需要较大),这时候你的R矩阵就定义的大一些,比如定义为[[1,0],[0,1],这时候Q矩阵就可以定义的小一些,比如定义为[[0.11,0],[0,0.11]]。
想要获得较好的滤波预测效果,得不断的调试这两个矩阵的大小。
下面是详细的代码部分:
import numpy as np
import matplotlib.pyplot as plt
##下面是通过高斯正态分布产生误差
def gaussian_distribution_generator(var):
return np.random.normal(loc=0.0, scale=var, size=None) ##np.random.normal是正态分布
# 参数loc(float):正态分布的均值,对应着这个分布的中心。loc=0说明这一个以Y轴为对称轴的正态分布,
# 参数scale(float):正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦。
# 参数size(int 或者整数元组):输出的值赋在shape里,默认为None。
# 状态转移矩阵,上一时刻的状态转移到当前时刻
A = np.array([[1, 1],
[0, 1]])
# 过程噪声协方差矩阵Q,p(w)~N(0,Q),噪声来自真实世界中的不确定性 N(0,Q) 表示期望是0,协方差矩阵是Q
Q = np.array([[0.1, 0], # Q其实就是过程的协方差
[0, 0.1]]) # 过程的协方差越小,说明预估的越准确
# 观测噪声协方差矩阵R,p(v)~N(0,R) 也是测量的协方差矩阵
R = np.array([[1, 0], # R其实就是测量的协方差矩阵
[0, 1]]) #测量的协方差越小,说明测量的结果更准确
# 状态观测矩阵
H = np.array([[1, 0],
[0, 1]])
# 控制输入矩阵B
B = None
# 初始位置与速度
X0 = np.array([[0], # 二维的,定义初始的位置和速度,初始的位置为0 ,速度为1
[1]])
# 状态估计协方差矩阵P初始化(其实就是初始化最优解的协方差矩阵)
P = np.array([[1, 0],
[0, 1]])
if __name__ == "__main__":
# ---------------------------初始化-------------------------
X_true = np.array(X0) # 真实状态初始化
X_posterior = np.array(X0) # X_posterior表示上一时刻的最优估计值
P_posterior = np.array(P) # P_posterior是继续更新最优解的协方差矩阵
speed_true = [] # 实际的速度值
position_true = [] # 实际的位置值
speed_measure = [] # 测量到的速度值
position_measure = [] # 测量到的位置值
speed_prior_est = [] # 速度的先验误差 估计值
position_prior_est = [] # 位置的先验误差 估计值
speed_posterior_est = [] # 根据估计值及当前时刻的观测值融合到一体得到的最优估计速度值存入到列表中
position_posterior_est = [] # 根据估计值及当前时刻的观测值融合到一体得到的最优估计值位置值存入到列表中
for i in range(30):
# -----------------------生成真实值----------------------
# 生成过程噪声
# 通过Q矩阵产生误差
w = np.array(
[[gaussian_distribution_generator(Q[0, 0])], # gaussian_distribution_generator(Q[0, 0])的值为0.01103097596,(这值是随机的,每次运行都不一样)
[gaussian_distribution_generator(Q[1, 1])]]) # gaussian_distribution_generator(Q[1, 1])的值为-0.1242726240,(这值是随机的,每次运行都不一样)
X_true = np.dot(A, X_true) + w # 得到当前时刻实际的速度值和位置值,其中A是状态转移矩阵上一时刻的状态转移到当前时刻
speed_true.append(X_true[1, 0]) # 将第二行第一列位置的数值,1.01103098添加到列表speed_true里面
position_true.append(X_true[0, 0]) # 将第一行第一列位置的数值,1.01103098添加到列表position_true里面
# -----------------------生成观测值----------------------
# 生成观测噪声
##通过R矩阵产生误差
v = np.array(
[[gaussian_distribution_generator(R[0, 0])], # gaussian_distribution_generator(R[0, 0])的值为-0.62251186549,(这值是随机的,每次运行都不一样)
[gaussian_distribution_generator(R[1, 1])]]) # gaussian_distribution_generator(R[1, 1])的值为2.52779100481,(这值是随机的,每次运行都不一样)
Z_measure = np.dot(H, X_true) + v # 生成观测值,H为单位阵E # A是状态观测矩阵 # Z_measure表示测量得到的值
position_measure.append(Z_measure[0, 0])
speed_measure.append(Z_measure[1, 0])
################################################################下面开始进行预测和更新,来回不断的迭代#######################################################################
# ----------------------进行先验估计---------------------
X_prior = np.dot(A,X_posterior) # X_prior表示根据上一时刻的最优估计值得到当前的估计值 X_posterior表示上一时刻的最优估计值
position_prior_est.append(X_prior[0, 0]) # 将根据上一时刻计算得到的最优估计位置值添加到列表position_prior_est中
speed_prior_est.append(X_prior[1, 0]) # 将根据上一时刻计算得到的最优估计速度值添加到列表speed_prior_est.append中
# 计算状态估计协方差矩阵P
P_prior_1 = np.dot(A,P_posterior) # P_posterior是上一时刻最优估计的协方差矩阵 # P_prior_1就为公式中的(A.Pk-1)
P_prior = np.dot(P_prior_1, A.T) + Q # P_prior是得出当前的先验估计协方差矩阵 #Q是过程协方差
# ----------------------计算卡尔曼增益,用numpy一步一步计算Prior and posterior
k1 = np.dot(P_prior, H.T) # P_prior是得出当前的先验估计协方差矩阵
k2 = np.dot(np.dot(H, P_prior), H.T) + R # R是测量的协方差矩阵
K = np.dot(k1, np.linalg.inv(k2)) # np.linalg.inv():矩阵求逆 # K就是当前时刻的卡尔曼增益
# ---------------------后验估计------------
X_posterior_1 = Z_measure - np.dot(H, X_prior) # X_prior表示根据上一时刻的最优估计值得到当前的估计值 # Z_measure表示测量得到的值
X_posterior = X_prior + np.dot(K, X_posterior_1) # K就是当前时刻的卡尔曼增益 # X_posterior是根据估计值及当前时刻的观测值融合到一体得到的最优估计值
position_posterior_est.append(X_posterior[0, 0]) # 根据估计值及当前时刻的观测值融合到一体得到的最优估计位置值存入到列表中
speed_posterior_est.append(X_posterior[1, 0]) # 根据估计值及当前时刻的观测值融合到一体得到的最优估计速度值存入到列表中
# 更新状态估计协方差矩阵P (其实就是继续更新最优解的协方差矩阵)
P_posterior_1 = np.eye(2) - np.dot(K, H) # np.eye(2)返回一个二维数组,对角线上为1,其他地方为0
P_posterior = np.dot(P_posterior_1, P_prior) # P_posterior是继续更新最优解的协方差矩阵 ##P_prior是得出当前的先验估计协方差矩阵
# 可视化显示
if True:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 坐标图像中显示中文
plt.rcParams['axes.unicode_minus'] = False
fig, axs = plt.subplots(1, 2)
axs[0].plot(speed_true, "-", label="speed_true(实际值)", linewidth=1) # Plot some data on the axes.
axs[0].plot(speed_measure, "-", label="speed_measure(测量值)", linewidth=1) # Plot some data on the axes.
axs[0].plot(speed_prior_est, "-", label="speed_prior_est(估计值)", linewidth=1) # Plot some data on the axes.
axs[0].plot(speed_posterior_est, "-", label="speed_posterior_est(融合测量值和估计值)",
linewidth=1) # Plot some data on the axes.
axs[0].set_title("speed")
axs[0].set_xlabel('k') # Add an x-label to the axes.
axs[0].legend() # Add a legend.
axs[1].plot(position_true, "-", label="position_true(实际值)", linewidth=1) # Plot some data on the axes.
axs[1].plot(position_measure, "-", label="position_measure(测量值)", linewidth=1) # Plot some data on the axes.
axs[1].plot(position_prior_est, "-", label="position_prior_est(估计值)",
linewidth=1) # Plot some data on the axes.
axs[1].plot(position_posterior_est, "-", label="position_posterior_est(融合测量值和估计值)",
linewidth=1) # Plot some data on the axes.
axs[1].set_title("position")
axs[1].set_xlabel('k') # Add an x-label to the axes.
axs[1].legend() # Add a legend.
plt.show()
最后的运行结果见下:
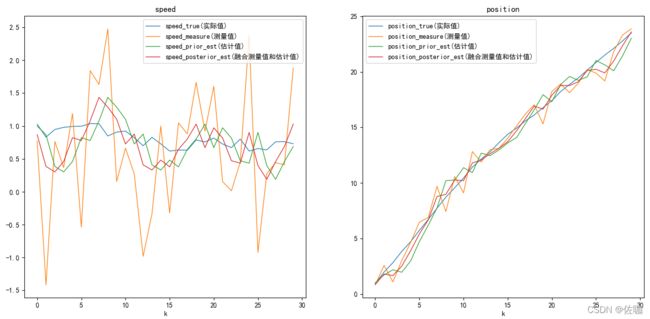
以上就是二维卡尔曼滤波的相关解析和代码,仔细看,仔细品,你看得懂的。
