Deep learning based segmentation for automated training of apple trees on trellis wires
ABSTRACT
由于其果实产量和质量高,以及在修剪和收获过程中适用于机器人操作,格子式结果墙培训系统正在成为现代苹果园的标准配置。在美国 PNW 地区将幼小的苹果树训练成格架训练树冠系统的常见做法是,人工选择树枝,然后将其绑在 6 或 7 层的水平格架线上。由于熟练劳动力的减少和劳动力成本的迅速增加,对苹果树进行这些现代果园建筑的人工培训变得越来越具有挑战性,因此使用传感和机器人技术的自动化培训可能是一种替代解决方案。分割树干、树枝和网格线是自动化树训练操作的关键步骤。在这项研究中,开发了一种基于深度学习的语义分割方法来自动执行此分割任务。使用 Kinect V2 传感器获取目标树木的 RGB 和点云数据。然后使用简单和前景 RGB 图像来训练基于卷积神经网络 (CNN) 的分割网络 (SegNet),以分割主干、分支和格子线。具有一些共同特征的树干和树枝相互分割,简单 RGB 图像的精度分别为 0.82 和 0.89,前景 RGB 图像的精度分别为 0.91 和 0.92。类似地,具有与树干和树枝截然不同的特征的网格线在简单和前景 RGB 图像中的分割精度分别为 0.92 和 0.97。获得的结果表明,与简单 RGB 图像相比,所开发的语义分割技术在前景 RGB 图像上的性能更好。在前景-RGB 图像中识别分割区域边界的准确度(由边界-F1 分数表示)对于主干、分支和网格线分别为 0.93、0.89 和 0.91。这些结果显示了采用基于深度学习的语义分割在果园环境中自动化苹果树训练的巨大潜力。
1. Introduction

图 1. 苹果树训练过程示意图;未经训练的树 (a) 被手动训练为正式架构 (b);而 © 描述了经过训练的树到格子结构的示例(红线代表格子线)。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
华盛顿州是美国新鲜市场苹果产量的主要州,占全国产量的 60% 以上(USDANASS,2017)。与传统果园相比,现代棚架苹果园通常具有提高产量和果实品质的潜力。树木训练操作的目的是用矮树创建所需的狭窄树冠结构,同时也为这些树木提供强大的支持(如果没有格子系统的支持,树木将无法容纳其上种植的水果数量)。因此,培训操作有助于改善通过树冠的光线拦截和空气流动,从而提高产量和果实质量。因此,这种训练有素的狭窄果园系统提供更简单的树冠,可以促进更高的劳动效率,更容易进行机械化或机器人操作,并带来更高的盈利能力(Weber,2000 年;Whiting,2018 年)。树训练是创建这种树结构的基本操作之一,它需要在不同的生长阶段将选定的分支水平连接到网格线(图 1)。一个典型的过程包括两个主要步骤:(i)根据果园工人的经验选择靠近网格线的分支(根据分支基部直径及其相对于网格线的位置,图 1a); (ii) 抓住选定的树枝并将它们绑在网格线上(图 1b)。由于这种树木培训程序目前由半熟练工人手动执行,因此该操作劳动强度大且成本高。在过去十年中,尤其是在过去几年中,商业果园主越来越难以获得足够的劳动力来完成这项任务,这表明特种作物生产的劳动力总体短缺(Brady 等人,2016 年)。为了保持苹果(和其他果树)产业的可持续发展,必须通过采用创新的机器人解决方案来实现树木培训等劳动密集型田间作业的自动化(Hertz 和 Zahniser,2013 年)。
1.1. Related work
近年来,关于收割等农田作业自动化的各种研究已经发表(Baeten 等人,2008 年;Bulanon 和 Kataoka,2010 年;Ji 等人,2012 年;Amatya 等人,2016 年;Silwal 等人,2017 年;Fu 等人al, 2019) 和修剪(Elfiky 等人,2015 年;Karkee 和 Adhikari,2015 年;Chattopadhyay 等人,2016 年;Akbar 等人,2016 年;Schupp 等人,2017 年;He 和 Schupp,2018 年)。大多数这些系统使用基于机器视觉的技术来识别目标树冠对象(例如苹果、树枝)以进行自动化操作。例如,Karkee 等人 (2014) 为机器人修剪重建了苹果树的 3D 骨架; Wu 等人 (2014) 使用条带编程重建了山核桃树的 3D 结构; Elfiky 等人(2015)使用基于骨骼估计的树木几何特征进行机器人修剪;和 Amatya 等人 (2016) 使用贝叶斯分类器确定了樱桃树的树枝,用于自动收获樱桃。同样,在机器人训练中,树干和树枝的分割和识别是迈向自动化操作的第一步。除了树枝和树干的分割之外,为训练而系在树枝上的格子线的分割也很重要。因此,苹果树和格子线的树干和树枝的分割对于映射所有树枝至关重要和树冠中的格子线,选择所需的树枝与格子线捆绑/训练,并提供自动树训练操作所需的 3D 位置信息。
上述关于检测/分割果树树枝的研究通常使用传统的机器视觉技术,由于环境和树冠条件的显着变化,特别是由于光照变化和背景物体的存在,这些技术在野外条件下的应用往往受到限制(Amara 等等人,2017 年)。很少有研究试图通过使用行间平台(隐藏背景物体)和人造光来克服这些挑战。例如,Botterill 等人 (2017) 为修剪机器人使用了行间平台和人造光。使用跨行平台和人造光本身就具有挑战性,这限制了许多机器人/自动化农业作业在商业果园中的使用。或者,低成本 RGB-D(红、绿、蓝和深度)相机的可用性使得使用深度信息过滤掉背景物体成为可能,从而避免了对空中平台和人造光的需求。关于使用 RGB-D 相机准确检测水果的研究已有报道(Nguyen 等人,2016 年;Tao 和 Zhou,2017 年;Perez 等人,2017 年;Gan 等人,2018 年;Gené-Mola 等人,2019 年;Lin 等人, 2019 年;Yu 等人,2019 年)和植物表型应用(Chéné 等人,2012 年;Zhang 和 Grift,2012 年;Hoffmeister 等人,2016 年;Santos 和 Rodrigues,2016 年;Narvaez 等人,2017 年;Mack 等人, 2018 年;以及 Milella 等人,2019 年)。尽管深度信息的使用消除了对用于背景抑制的跨行平台的需求,但对不同光照条件的敏感性以检测所需物体仍然是一个挑战。在这种多变的照明条件下,使用传统的机器视觉技术从所需对象中对对象进行子分类/分类,其检测/分割精度仍然受到很大限制。这个问题要求有必要使用 RGB-D 信息以及最先进的机器视觉技术(例如深度学习),以便在实际条件下成功进行自动化/机器人操作。
近年来,人工智能(包括基于深度学习的对象检测和分类技术)已被证明可以提高识别室内和室外环境中对象的鲁棒性和准确性(Girshick 等人,2014 年;Makantasis 等人,2015 年;Noh等人,2015 年)。目标检测和分类技术在农业应用中的性能受到可变环境条件的限制。基于深度学习的技术可以解决这些局限性,并且由于其高稳健性和准确性而优于传统的图像处理技术(Kamilaris 和 Prenafeta-Boldú,2018 年)。在农业中,深度学习技术在检测水果和树枝方面的应用很少见(Sa 等人,2016 年;Bargoti 和 Underwood,2017 年;Chen 等人,2017 年;Rahnemoonfar 和 Sheppard,2017 年;Liu 等人,2019 年)。Botterill 等人 (2017) 使用三角特征匹配算法 3D 重建葡萄树冠层,并使用人工智能网络在受控照明条件下(使用人造光)决定修剪的分支,并固定背景,这限制了其在实时现场条件。 Zhang 等人 (2018) 检测到已经使用 R-CNN(基于区域的卷积神经网络)在果壁结构中训练过的苹果树枝,该网络后来用于开发自动振动收割机。该技术对未经训练的树缺乏适用性,由于树的结构更加复杂和多变,这对检测和分类提出了更多挑战。此外,他们的技术在检测分支段以获得树的完整结构后需要额外的处理步骤,例如曲线拟合。在这项工作中,除了分支和主干部分之外,还需要分割出格子线。
基于卷积神经网络 (CNN) 的 SegNet 专为语义分割而设计,可以根据图像的形状、外观和空间关系区分图像中存在的不同像素类别,以实现准确的对象分割(Badrinarayanan 等人,2017 年)。与其他深度学习方法相比,语义分割的这一特征使其更强大,可以根据空间准确地分割出图像中外观不同的区域(例如树干/树枝与格子线)以及外观相似的区域关系(主干与分支)。除了分割区域,语义分割还保留了图像场景的边界信息,有助于减少实时应用的图像后处理,例如从树枝到格子线的机器人训练。在之前的一项研究中,作者开发了一种基于 CNN 的算法来分割未经训练的树的树干和树枝(Majeed 等人,2018 年)。然而,网格线的分割比分割树干和树枝更具挑战性,需要更多的图像来训练网络(Kamilaris 和 Prenafeta-Boldú,2018)。与其他类别(主干和分支)相比,网格线非常细,导致此类像素数量明显减少。在这种类别分布不均匀的情况下,分割精度很容易受到主导类别的影响(Badrinarayanan 等人,2017)。 Madaan 等人 (2017) 综合生成了大量图像(67、702 张图像)来分割用于飞行器自主导航的传输线。由于网格线分割对于自动/机器人苹果树训练至关重要,一些数据增强和类平衡技术可能有助于更有效地为网络提供各种数据以提高学习性能(Krizhevsky 等人,2012 年)。因此,本研究旨在开发一种由数据增强技术支持的改进方法,并使用 RGB-D 信息在不同光照条件下(即晴天、阴天和夜晚)真实地准确分割苹果树冠的树干、树枝和格子线。 支持田间条件下自动苹果树训练的时间。
1.2. Goals and objectives
本研究的总体目标是研究一种基于深度学习的系统,该系统可以有效地分割出苹果树冠层中的树干、树枝和格架线,以便在商业果园环境中进行自动树木训练。具体目标是:(i)使用颜色和深度信息以及基于深度学习的语义分割技术分割出树干、树枝和网格线; (ii) 仅使用颜色 (RGB) 信息(简单 RGB 图像)以及颜色 (RGB) 和深度信息(前景 RGB 图像)来比较网络性能。从这项研究中获得的结果将为开发自动化苹果树培训系统奠定基础。
2. Materials and methods
2.1. Experimental field
在这项研究中,使用了商业果园(Prosser,WA)中密集种植、未经训练的一岁(第一片叶子)苹果树(Geneva® G.41 砧木上的‘Envy’)的图像(图 2a)。树木是独立的,并被训练成 V 型格架果园架构(图 2b),其中格架线的水平层间隔约。 50厘米。树距和行距分别为45厘米和330厘米,平均树高约200厘米。
2.2. Image acquisition
未经训练的休眠苹果树的 RGB 图像和 3D 点云数据于 2018 年 1 月使用安装在图像采集平台(图 2b)上的 Kinect V2 传感器(Microsoft Corporation,Redmond,WA)获取,并使用 Matlab® 2017b 实现软件(Mathworks,Natick,MA)。传感器距离地面的高度为 1.10 m,传感器与树行中心之间的距离为 1.10 m。在整个图像采集过程中,高度和距离保持不变。 Kinect V2 可以使用其深度和 RGB 传感器获取 RGB、深度和点云数据。 Kinect V2 的深度(70.7 × 60°)和 RGB(84.1 × 53.8°)传感器的视野不同,这对共同配准两种类型的信息提出了挑战。然而,在点云数据中,深度和RGB信息已经映射到一起,这使得利用深度信息对RGB图像进行背景去除变得方便简单。由于这种简单性,与 RGB 图像一起获取了分辨率为 1920 × 1080 像素的点云数据。在不同光照条件下(即晴天和阴天,以及使用发光二极管或 LED 灯的夜间),总共获得了 509 张随机选择的树木的 RGB 图像和点云数据集(图 2c-e)。白天图像是在上午 9:00 到 11:00 之间收集的,夜间图像是在下午 5:00 到 6:00 之间收集的。图 3a 显示了使用 Kinect V2 获取的 RGB 图像的示例。
2.3. Image pre-processing
目标树的 RGB 图像也可能在背景中包含许多其他树和网格线,这可能会降低分割精度(图 3a)。然而,可以使用深度信息移除这些背景对象,因为目标树木比背景中的树木更靠近传感器。从点云数据中提取 RGB 图像中每个像素的深度信息。然后使用 1.30 m 的距离阈值去除任何超出阈值距离的物体。图 3b 显示了背景去除后的示例图像,其中可以清楚地看到目标树和网格线。

图 2. (a) 本研究中使用的年轻(一岁)商业果园; (b) 实验场和图像采集系统示意图;以及在不同光照条件下收集的示例图像,即(c)晴天; (d) 多云; (e) 夜间使用 LED(发光二极管)灯。
2.4. SegNet for semantic segmentation
SegNet(基于编码器-解码器的深度卷积网络)(Badrinarayanan 等人,2017 年)架构专为像素级语义分割而设计。这能够根据类之间存在的外观、形状和空间关系有效地分割区域。该网络由编码器(编码器深度为 5)和相应的解码器组成,随后是最终的像素级分类层。编码器网络有 13 个卷积层,对应于 VGG16 的初始 13 个卷积层(Simonyan 和 Zisserman,2014)。对于 SegNet,丢弃了 VGG16 的全连接层以保留高分辨率的编码器特征图并显着减少参数数量。图 4 显示了 SegNet 分割苹果树干、树枝和网格线的总体过程和训练架构。

图 3. (a) Simple-RGB 图像示例; (b) 使用 1.30 m 的深度阈值去除背景后相应的前景-RGB 图像。
每个编码器通过使用滤波器组执行卷积生成一个特征映射集。随后对这些特征图进行批量归一化,然后使用 ReLU(整流线性单元)(f(x) = max(0,x)) 层应用激活函数,以提高学习过程的速度并确保之间的映射输入和输出空间。最后,为了实现稳健的分类,使用步幅为 2 的 2×2 窗口进行最大池化,然后进行 2 倍子采样以实现更多的平移不变性(Badrinarayanan 等人,2017)。此外,在所有编码器和解码器上选择每个卷积层的 3 × 3 恒定内核大小和步长 1,这有助于将特征映射深层中的像素追溯到输入图像。
SegNet 中的每个编码器都有一个相应的解码器网络,用于使用最大池索引对来自其相应编码器的输入特征图进行上采样。然后将这些特征图与解码器滤波器进行卷积,以从最大池中生成的稀疏特征图中产生密集特征。每个解码器过滤器中的通道数与上采样特征图的数量相同。在解码器过滤器的每个卷积层生成的密集特征图在将它们馈送到 ReLU 层之前进行批量归一化。归一化后,最后一个解码器末尾的这些密集特征表示被馈送到分类层(soft-max)。最后,使用 soft-max 分类层确定每个像素属于特定类别的概率。
2.5. Network training and testing
由于数据集较小(356 张训练图像和 153 张测试图像),使用迁移学习方法(导入预训练网络,然后使用新数据集进行微调)在实现稳定模型的同时获得相对准确的结果,避免网络陷入局部最小值 (Chen et al, 2017)。在这项研究中,来自预训练 VGG16 模型的编码器权重,在 ImageNet 数据库(Simonyan 和 Zisserman,2014)上训练,由于其更高的对象定位和分类能力而被初始化。通过替换 soft-max 分类层并微调网络以从未经训练的苹果树树冠图像中分割树干、树枝和格子线来进行迁移学习。
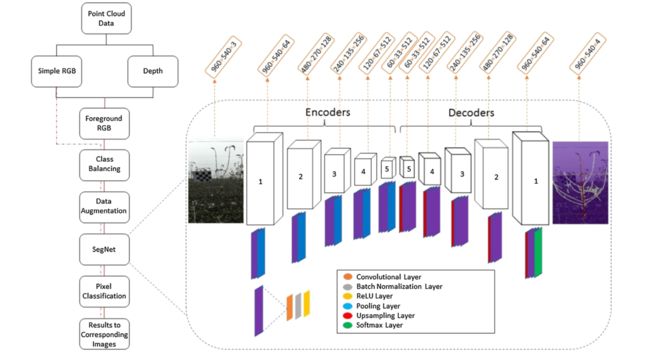
图 4. 用于在休眠季节分割苹果树冠层中的树干、树枝和网格线的 SegNet 的说明性流程图和总体架构。
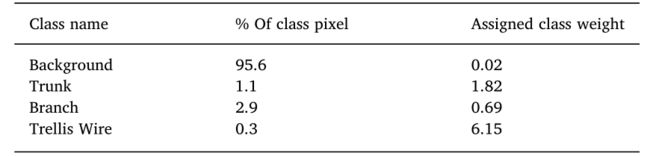
表 1 每个目标类别中图像像素的百分比以及分配给这些类别的相应权重。
使用 Matlab® 中的像素级标记对总共 509 张图像进行了手动标记,其中 356 张随机选取的图像 (70%) 用于训练,其余图像(153 张图像,30%)用于测试。每张图片都被标记为背景、树干、树枝和网格线四类。除了树干、树枝和格子线(例如,背景树和格子线、贴纸和棋盘)之外,图像中存在的所有对象都被标记为背景类的一部分。每个类代表其在图像中的相应区域,需要对其进行分割。为了满足所用计算环境(NVIDIA GeForce GTX 1080 GPU)的要求,每张图像及其各自的标签都被缩小到 960 × 540 像素。
表 1 描述了每个类中的像素比例(使用图像数据集中属于每个类的像素数计算),表明背景具有最大(95.6%)的像素比例,格子线类具有最少(0.3%) ),这可能会导致对优势阶级的偏见,从而影响学习过程。为了尽量减少这个问题,使用了中频类别平衡,其中分配给每个类别的权重是通过将类别频率中位数除以完整训练数据集上的类别频率来确定的(Badrinarayanan 等人,2017),表示为:

其中 c 表示特定类别(背景、主干、分支或网格线),而 median_freq 是频率的中值。表 1 提供了计算出的类别权重。
为了提高网络的准确性和性能,可以使用数据增强,通过反射、平移和其他变换人工生成更多的训练样本 (Krizhevsky et al, 2012)。本研究在左/右方向使用随机反射技术,在 X/Y 方向随机平移 ± 10 个像素,以生成训练样本的变化。在训练过程中,每张图像在被馈送到网络进行训练之前被随机反射和/或翻译。这种技术有两个优点:(i)网络被引入到训练数据的更多变化中,因此最小化了训练数据过度拟合的机会; (ii) 每个时期的图像总数保持不变(356 张训练图像),因此网络总训练时间不会增加。
需要优化各种训练参数以提高分割性能。固定动量为 0.9 的随机梯度下降 (SGD) 算法用于在训练过程中帮助收敛网络(Keskar 等人,2016),而交叉熵损失用作训练网络的目标函数(Long 等人,2015) ).经过多次试错运行后,初始学习率、最小批量大小和最大纪元分别设置为 0.001、1 和 100。在每个训练时期之前,训练数据的顺序是随机的。
2.6. Performance evaluation
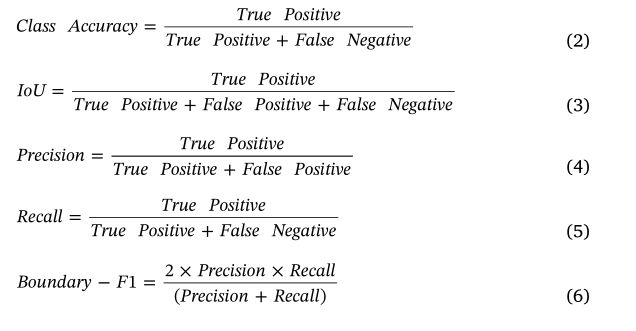
基于区域的(全局准确度、类别准确度、归一化混淆矩阵和联合交集 (IoU))和基于轮廓的(边界-F1)测量均用于评估网络性能。全局精度定义为在测试数据集中正确分类的像素的百分比,而类别精度(等式(2))是通过对所有可用类别的分类像素进行平均来测量的。 IoU (Eq. (3)) 表示所有类并集的平均交集,也称为 Jaccard 指数。这些基于区域的措施没有评估分割区域边界的准确性,而这对于这种自动树训练操作来说是一个非常重要的措施。此外,IoU 测量是严格的,因为它惩罚误报并且它有利于区域平滑而不是边界精度(Csurka 等人,2004)。因此,在本研究中,还分析了边界-F1 分数(等式(6)),它提供了预测和地面真实类边界之间基于 F1 测量的准确性。
4. Conclusions
本研究的目标是创建一种方法,可以有效地分割出苹果树冠层中的树干、树枝和格架线,以便在果园环境中将苹果树枝自动训练为格架线。这项研究发现,使用简单 RGB 图像和基于深度学习的语义分割技术,可以成功地将树干、树枝和网格线从背景中分割出来。使用前景-RGB 图像(使用距离阈值去除背景)训练的网络可以提高分割的准确性。从这项研究中得出的一些具体结论包括:
- 使用基于深度学习的语义分割技术和彩色 (RGB) 图像,在果墙苹果园(休眠季节)中成功分割了树干、树枝和格子线。使用这种技术,平均精度为 0.89,IoU 为 0.52,Boundary-F1 为 0.81。
- 与没有去除背景的图像相比,使用去除背景的 RGB 图像 (Foreground-RGB) 在平均准确度 (0.94)、IoU (0.58) 和 Boundary-F1 (0.92) 得分方面有显着提高。这项工作(包括网格线)使用有限数量的训练图像 (356) 实现的分割精度水平表明,可能没有必要使用大量合成图像来训练深度学习模型。
- 分析测试数据集中的单个图像表明,基于深度学习的语义分割可以在白天和夜间的真实果园环境中使用。通过增加类似条件下训练图像的数量和/或通过预处理这些图像去除镜面反射率,可以进一步改善在夜间条件下获取的图像的分割结果。
在未来的研究中,将通过估计树冠结构所需的基本参数(包括树枝基部直径和树枝基部位置以及与格架线的距离)来选择最佳树枝进行树木训练。这些选定树枝的位置信息可由机器人机器用于自动树木训练操作。