何为非侵入式负荷分解
0 解答
有同学提出了一些问题,我在这里再说明一次。
1)深度学习算法应用于非侵入式负荷分解是不需要事件检测的吗?
回答:是的,不需要事件检测。深度学习算法应用于负荷辨识的话,必须要有事件检测。
2)负荷分解和负荷识别的实时性问题:是不是负荷分解的实时性差,需要1个星期,甚至好几个月的数据,所以实时性很差。负荷识别只需要几分钟,或者几小时的数据,所以实时性更好?
这里与是哪种技术路线无关,只和你的流程,流程中的算法有关。首先,上面提到的数据是指用来训练模型时用到的数据,这种数据一般是历史数据,与应用时的实时性无关。讨论实时性需要研究在进行电能分解时,每一次输入算法中的数据量(时间跨度)。通常来说,负荷识别研究的是高频数据,事件检测在发现事件后,需要提取前后稳态的数据,这个数据的时间跨度越短它实时性越好。而负荷分解一般研究的是低频数据,因此实时性会较差,但其每次模型输入的时间跨度并不会长达,几天,几个月。一般窗口为299,599又或者1024,而采样频率一般是1s或6s,因此它结果延迟大概在几分钟到几小时之间。
1 前言
正如之前所说的,负荷分解没有负荷识别路线的三个步骤,而是直接建立一个模型来表征总负荷和目标电器的映射关系。因此,负荷分解就分为三个可研究的部分,总负荷的数据,模型具体结构,目标电器的数据。总负荷的数据通常只有有功功率,但是近些年有研究者开始研究把无功功率、电流、视在功率也作为输入。目标电器通常来说只有有功功率,因为知道有功就可以知道消耗的电能了,但也有研究者在研究迁移学习时,在输出加上了一个标签用来表征该样本属于哪个房屋。负荷分解是回归任务,因此只要是能进行回归的网络就能用来做负荷分解,与它最开始是用来负荷预测、语音识别等无关。
2 映射形式
通常来说,映射形式分为序列到序列(seq2seq)、序列到点(seq2point)和序列到子序列(seq2subseq)。典型的seq2seq映射模型有:DAE和seq2seq模型;seq2point映射模型有:seq2point和Bilstm模型。seq2subseq映射模型有:SGN模型。
数学模型如下:
![]()
![]()
其中:![]() 是总负荷a到b位置的数据;
是总负荷a到b位置的数据;
![]() 目标电器a到b位置的数据;
目标电器a到b位置的数据;
 是时间窗口的长度;
是时间窗口的长度;
 是时间窗口的中点。
是时间窗口的中点。
三种映射方式的结构如下所示:

3 数据预处理
常见的数据集有REDD、UKDALE、AMPds等。各个数据集的比较如下[1]:
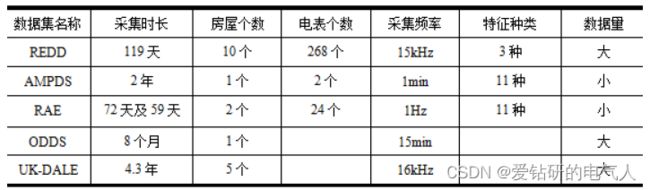
一开始很多人都在用nilmtk工具包进行数据预处理,但是后面大家将用到的代码取出来了就不需要nilmtk工具包了。
下面以UKDALE为例介绍如何处理数据:
1)对齐总表和分表的数据,并放到同一个文件中。
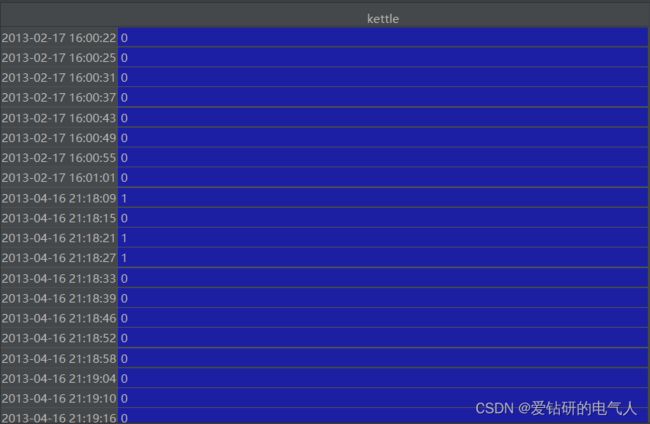
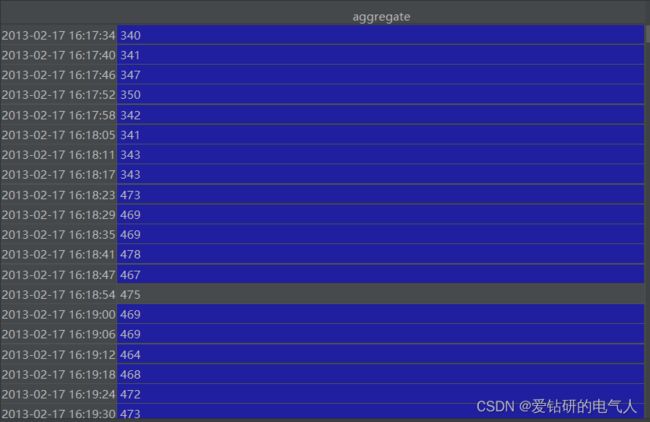 由于总表和分表的数据采样频率不同,因此首先要对分表的数据进行重采样,即保证两者的采样频率都是1/6Hz,然后并到一起。
由于总表和分表的数据采样频率不同,因此首先要对分表的数据进行重采样,即保证两者的采样频率都是1/6Hz,然后并到一起。
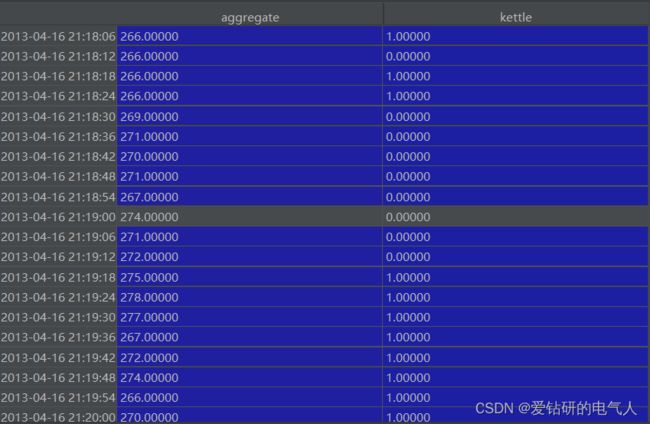
2)将时间删去,开始对其进行标准化处理。
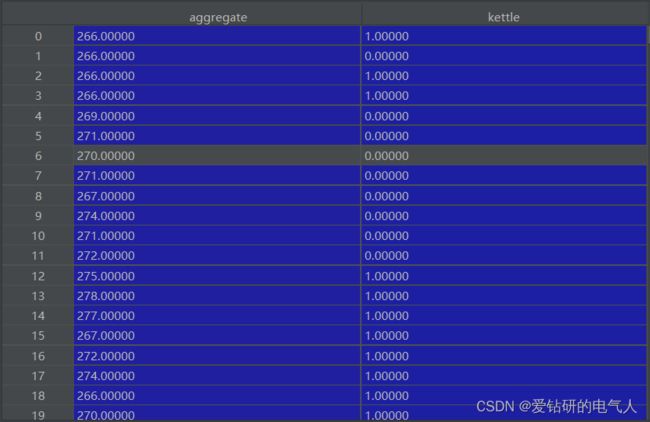
标准化的处理有很多种,常见的有z-score 标准化和min-max标准化等。
(1)z-score 标准化

(2)min-max标准化

以z-score 标准化为例进行标准化处理。
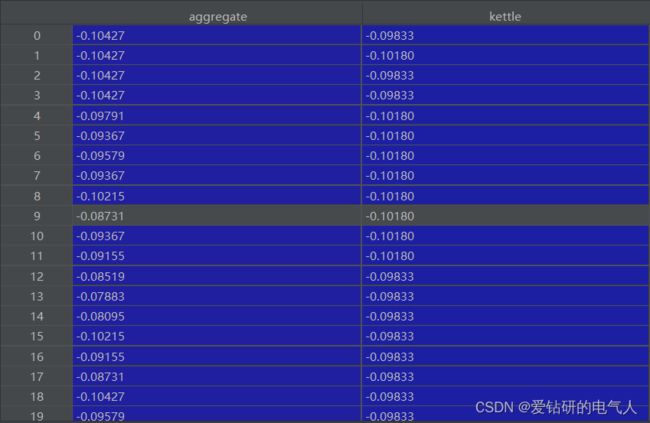
以min-max标准化为例进行标准化处理。

3)按7:2:1生成训练集、测试集和验证集。比例比例随意取的,看你的想法。

4 模型训练和测试
导入三个数据集,根据tensorflow或者pytorch框架,搭建网络模型。 然后进行训练和测试就行。后面会复现几个网络,并对结果进行对比。
5 指标计算
5.1 指标定义
模型好坏肯定需要指标进行评判。指标分为回归指标和分类指标。
负荷分解效果采用平均绝对误差(MAE)、均方误差(MSE)、总信号误差(SAE)评价,负荷识别效果采用PRECISION和F1评价。
MAE、MSE、SAE计算公式如下:
将目标电器的估计能耗和预设的阈值(本节设置为40W)比较,得到目标电器的开关状态。
RECALL表示正样本被正确预测的比例,用公式表示为:
![]()
![]()
式中 TP—— 状态为“On”的样本被正确预测的数量;
FN—— 状态为“On”的样本被错误预测的数量。
PRECISION表示被正确分类为“On”状态的样本数占所有被认为是“On”状态的样本数的比例。
![]()
式中 FP—— 状态为“Off”的样本被错误预测的数量。
F1是PRECISION和RECALL的加权平均值,越大的值意味着越好的状态识别率。
5.2 计算过程
将模型预测的结果和理想输出拼接在一起,然后根据5.1的公式写代码计算对应指标即可。
[1]贾惠彬,刘郅铂.非侵入式负荷分解文献综述[J].集成电路应用,2021,38(04):62-63.DOI:10.19339/j.issn.1674-2583.2021.04.021.