Python笔记:数据排名
本文简要展示一下,怎么在pandas中用rank()函数进行数据排名。原理不作赘述,具体用法请看示例:
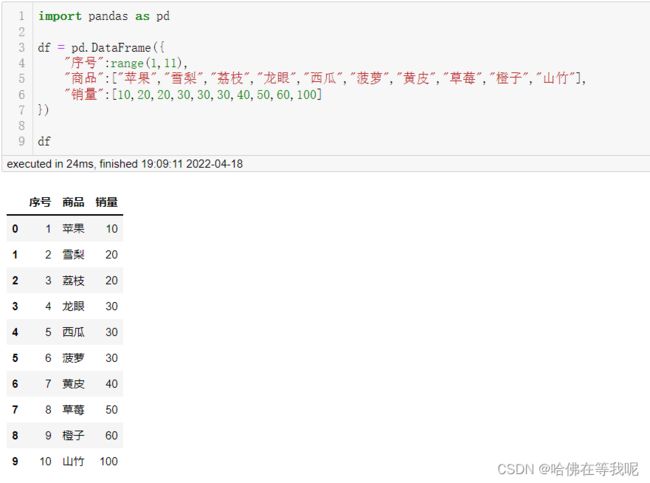
01. 构造数据集
import pandas as pd
df = pd.DataFrame({
"序号":range(1,11),
"商品":["苹果","雪梨","荔枝","龙眼","西瓜","菠萝","黄皮","草莓","橙子","山竹"],
"销量":[10,20,20,30,30,30,40,50,60,100]
})
df
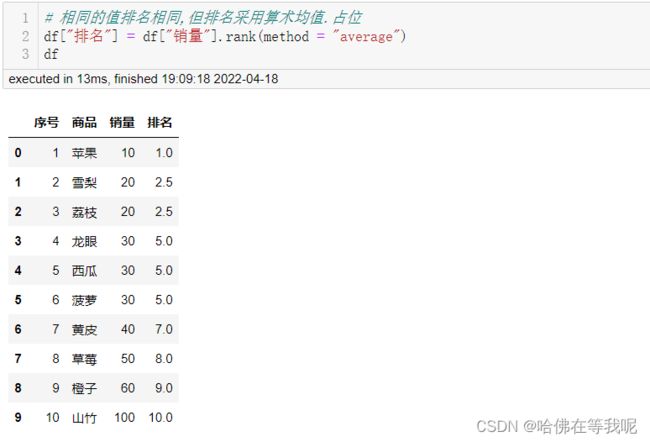
02. 算术均值排名
# 相同的值排名相同,但排名采用算术均值.占位
df["排名"] = df["销量"].rank(method = "average")
df
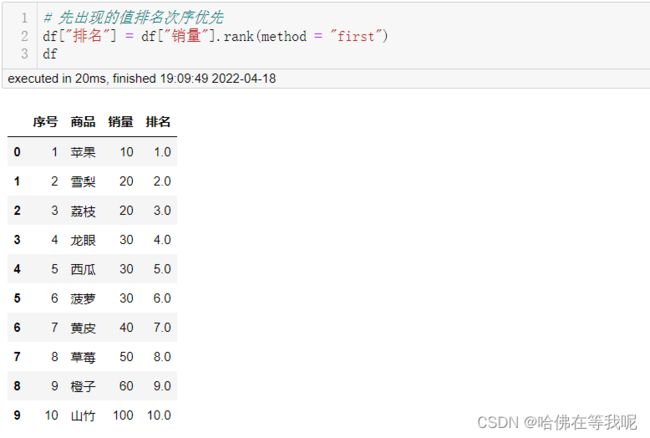
03. 先出现的值排名优先
# 先出现的值排名次序优先
df["排名"] = df["销量"].rank(method = "first")
df
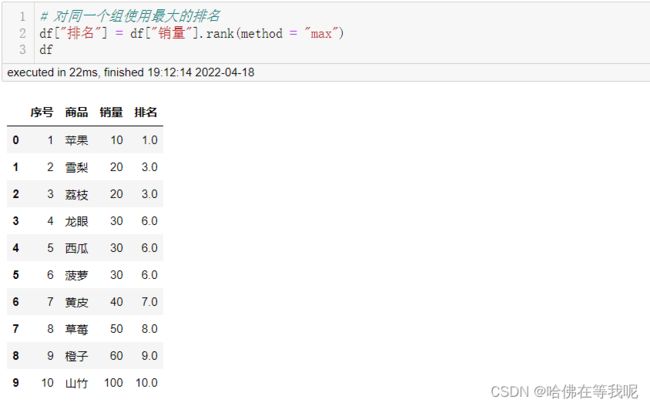
04. 对同一个组使用最大的排名
# 对同一个组使用最大的排名
df["排名"] = df["销量"].rank(method = "max")
df
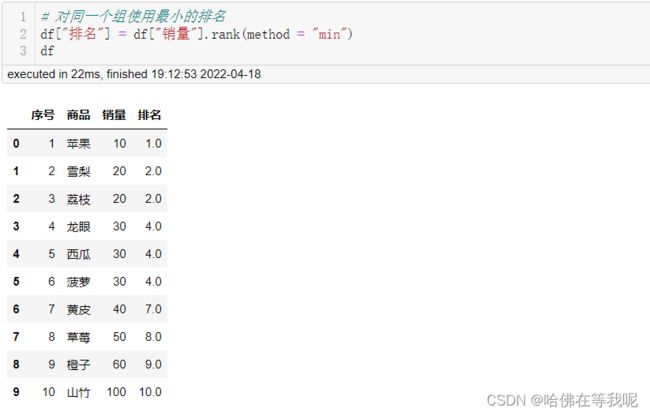
05. 对同一个组使用最小的排名
# 对同一个组使用最小的排名
df["排名"] = df["销量"].rank(method = "min")
df
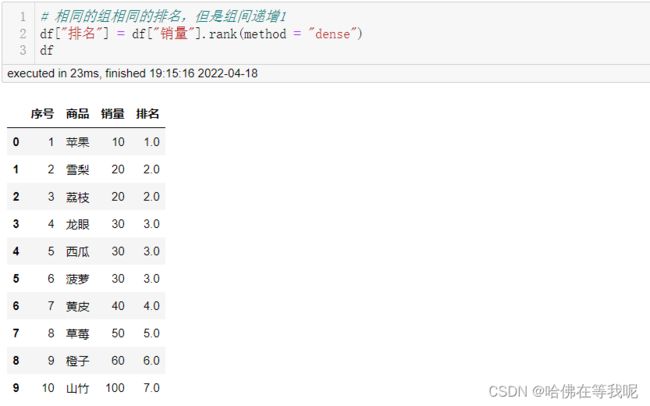
06. 同组同排名,组间递增1
# 相同的组相同的排名,但是组间递增1
df["排名"] = df["销量"].rank(method = "dense")
df
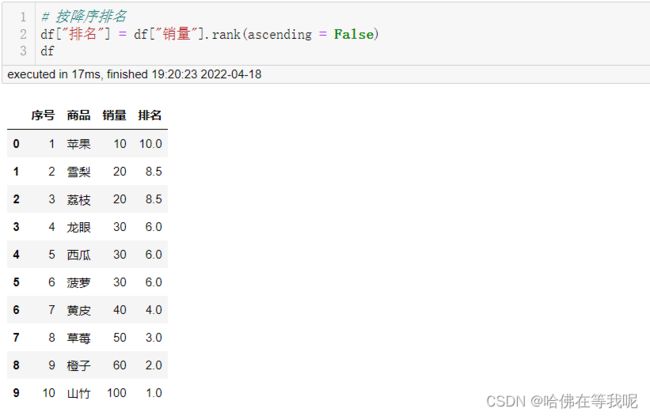
07. 按降序排名
# 按降序排名
df["排名"] = df["销量"].rank(ascending = False)
df
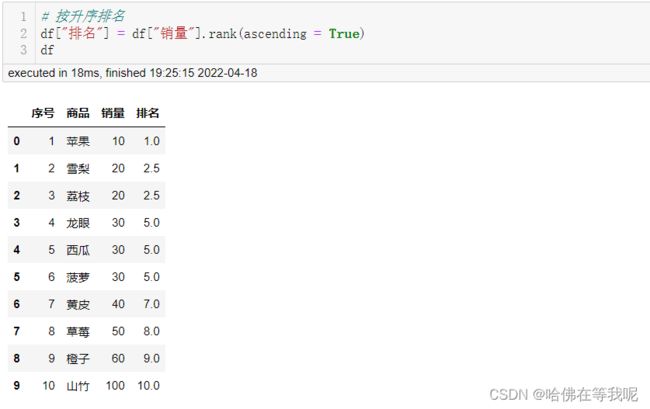
08. 按升序排名
# 按升序排名
df["排名"] = df["销量"].rank(ascending = True)
df
创作不易,分享难得。如果觉得本文对您有帮助,请不吝动动宝贵的手指帮忙点个赞以示支持一下。后期,我会用心分享更多更精彩、实用的干货给大家,以期共同进步。感谢阅读!