CCF BDCI | 算能赛题决赛选手说明论文-04
基于TPU平台实现人群密度估计
队名:innovation
| 陈照照 数据科学与大数据技术20级 台州学院 中国-瑞安 [email protected] |
董昊 数据科学与大数据技术20级 台州学院 中国-杭州 [email protected] |
陈晓聪 数据科学与大数据技术20级 台州学院 中国-宁波 [email protected] |
| 卓佳伟 数据科学与大数据技术20级 台州学院 中国-福州 [email protected] |
董坤 数据科学与大数据技术20级 台州学院 中国-定西 [email protected] |
陶欣 讲师 台州学院 中国-台州 [email protected] |
团队简介
我们因大学相遇,因志趣相识,同属20级数据科学与大数据技术专业,就读于台州学院。台州学院坐落在新兴的滨海城市——台州,东濒东海,南连雁荡,北倚天台,山水神秀,人杰地灵,是理想的治学修身之地。
我们热爱数据科学与人工智能,在参与竞赛的过程中丰富自己的经历,在实践中寻找自己的不足,在相互帮助之下共同成长,共同进步,并以之为跳板开拓视野。
摘要
人群密度估计在公共安全管理中发挥着重要的作用,估计人群密度的模型需要兼顾准确性与实时性。本文在模型选择与转换、模型量化、图像处理等方面探索并定量比较了多种配置下人群密度估计模型的推理效果。通过对比我们复现的评分指标以及官方给出的测试结果,选用VGG模型并量化成int8bmodel格式,将测试集图像大小强制调整为高576px,宽768px,锐度和亮度同时提高1.5倍是我们得出的最好方法。实验结果表明,与出题方给出的原始解法相比,该方法在推理速度与推理精度上均有明显的提高。
关键词
TPU、人群密度估计、图像处理
1 研究背景与思路
人群密度估计是计算机视觉中的一项重要任务。在公共场所,人群踩踏事件对公共安全产生了巨大的负面影响。准确而有效地估计人群密度是监测人群状态、制定疏散策略的关键[1]。对于人群密度估计问题,现有的的研究分为两类。一类基于机器学习,如基于集成回归的机器学习模型[2],一类基于深度学习,如CNN[3]、CSRNet[4]。这些方法已经真实地应用于现实生活的人群密度检测来避免人群踩踏事故的发生。本文研究的目的是选用最优的深度学习预训练模型在兼顾推理精度与速度的情况下部署在算能TPU芯片上,使模型的实用性和泛化性得到进一步的提高。
本文研究思路如图1所示,首先确定评估方法为推理精度与推理速度得分的总和,推理精度由MAE、RMSE、NAE得出。然后在CSRNet、MCNN、VGG模型中三选一,在fp32bmodel、int8bmodel模型转换格式中二选一。在模型的量化中尝试200、230、250、350、500为迭代次数。最后对测试集图像的大小进行按比例以及不按比例的调整,并对图像的对比度、锐度、亮度、色度进行增强,选出一个最合适的方法。

图1:研究思路
2 评估方法
本次赛题通过Mean Absolute Error(MAE)平均绝对误差、Root Mean Squared Error(RMSE)均方根误差和Normalized Absolute Error(NAE)标准化绝对误差,三个指标评估模型精度。
MAE得分计算公式:
 (1)
(1)
RMSE得分计算公式:
 (2)
(2)
NAE得分计算公式:
 (3)
(3)
三个指标得分公式:
![]() (4)
(4)
![]() (5)
(5)
![]() (6)
(6)
将计算得到的MAE_SCORE,RMSE_SCORE,NAE_SCORE之和称为ACC_SCORE,精确度得分公式:
![]() (7)
(7)
时间方面的得分称为TIME_SCORE,TIME为数据集单张图片推理的平均时间,单位为秒,时间得分公式:
![]() (8)
(8)
最终得分称为FINAL_SCORE,最终得分计算公式为:
![]() (9)
(9)
基于以上公式,我们自行实现了评估指标函数。下文中各方案的比较中均使用该评估指标,考虑到实现方式与运行环境,可能与官方的得分计算方式略有差异。
3模型选择与转换
3.1 fp32bmodel
模型的转换有两种格式。首先是将traced_model.pt转换为fp32bmodel格式。为便于参赛选手模型优化,大赛方特选取A榜测试集10张图片给出参考答案。用A榜10张有参考答案的图片进行测试,VGG模型的精确度得分是最高的,其次是CSRNet模型。在时间得分上,MCNN得分最高。在总分上,VGG得分最高。用A榜1201张测试图片进行测试,在精确度得分上,MCNN模型的得分严重下滑,但在时间得分上依然保持最高。由于最终的得分需要考虑到模型的泛化问题,单凭10张图片的测试成绩是不够准确的。根据A榜测试集1201张图片的测试结果,我们暂且按FINAL_SCORE模型降序排名:VGG模型、CSRNet模型、MCNN模型。

图2:A榜测试集CSRNet,MCNN,VGG 模型转为fp32bmodel格式测试结果
3.2 int8bmodel
接下来是将traced_model.pt转换为int8bmodel格式,默认量化校准图片数量为200张。结合图2,由于MCNN模型的精确度得分过低,考虑量化的时间成本,优先选择VGG和CSRNet模型转换为int8bmodel格式。又由于CSRNet模型和VGG模型在本次实验中呈现出来的结果与转换为fp32bmodel格式的结果呈正相关,推测MCNN在int8bmodel上也不会有更出色的表现。因此本次实验舍弃了MCNN模型。
对比CSRNet模型和VGG模型,无论是在精度得分,还是在时间得分上,无论是在A榜10张测试图片上进行测试,还是在A榜1201张测试图片上进行测试,VGG模型都略胜一筹,所以确定选择模型为VGG,转化格式为int8bmodel进行后续实验。

图3:A榜测试集CSRNet、VGG模型转为int8bmodel格式测试结果
4 模型的量化
选择VGG模型以及确定转换的格式后,继续进行模型的量化。命题方默认量化校准图片数量为200张,即从固定的200张图片中,反复随机选取200张。为了探究迭代次数对推理结果的影响,选取200张、230张、250张、350张、500张作为量化校准的迭代次数。
经过对比,在用A榜10张图片进行测试时,量化校准迭代次数为250时得分是最高的,其次是200、230。在用A榜1201张图片进行测试时,5种量化校准图片数量的得分趋于平缓,说明不同的迭代次数之间差别不大,迭代次数的变化对最终结果的得分不起关键性作用。但在A榜1201张图片的测试集中,用230张量化校准图片险胜250张,再一次考虑到模型的泛化问题,最终选择了量化校准迭代次数为230时的VGG模型。
由于A榜测试集10张图片人群密度答案已知,因此可以计算出精确度各分项得分,而A榜其它图片的答案是未公布的,暂无法计算出分项得分。

图4:A榜测试集VGG模型int8bmodel转换方法下不同量化校准数量测试结果
5 测试集图像的处理
5.1 图像大小
确定了模型以及模型的转化方法和量化方法,为探讨预训练模型对各种尺寸输入的适应性,将图像大小进行调整。由于模型的输入尺寸是固定的,在进行推理之前,需要将小于固定尺寸的图放大,大于固定尺寸的图需要用滑动窗口将输入切分成不大于576px*768px的子图分别推理。而大部分的图都是大于该固定尺寸的。因此,大部分的图像都需要被切分,且越大的图像就会被切分成更多的子图,有了更多的子图,推理速度也会更慢。
出赛方提供的demo中,将图像按比例缩放到高和宽最大不大于2048px*2048px,最小不小于576px*768px。为加速推理,在测试集图像大小的修改上,尝试图像按比例以及不按比例调整两种方法。将数据集中所有图片的高分别调整为不大于1536px、1280px、1216px、1168px、567px,宽则适应比例。如图5,随设定尺寸的减小,所有指标都成上升趋势。接着做了一个大胆的尝试,强制将所以图像的尺寸调为576px*768px,适应模型的最小尺寸。又考虑到高大于宽的图像失真过于明显,对于原始尺寸高大于宽的图像均做顺时针旋转90度的处理。在A榜10张图片测试的结果中,该方法的精确度得分与时间得分均有所提高且与假设预期符合。在用A榜1201张图片测试的结果中,最终得分也是成上升趋势。由于比赛时间与A榜提交次数的限制,没有得出用1201张图片测试的结果。
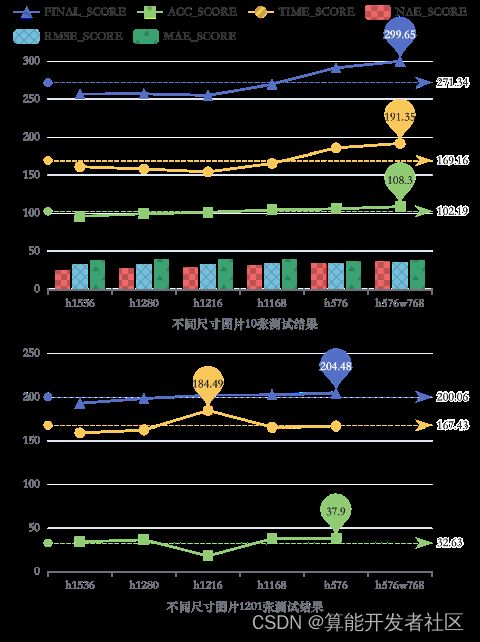
图5:A榜测试集VGG模型int8bmodel转换方法下不同尺寸图片测试结果
5.2 图像增强
5.2.1 提升对比度、锐度、亮度、色度
调整完图像大小后,模型推理速度得到了大幅的提高。增强图像对比度、锐度是深度学习图像预处理的常用方法[5]。为增加模型推理的精度,尝试以1.5倍增强图片的对比度、锐度、亮度以及色度。由图6可知,图像增强以后,在时间得分上相当,在精确度得分上,增强对比度分数下滑明显,增强色度未能使得分发生明显变化,但锐度与亮度的增强对精确度的得分小有提高。

图6:A榜测试集10张图片对比度、锐度、亮度、色度分别增强1.5倍测试结果
5.2.2 继续增强锐度、亮度
尝试将锐度、亮度分别增强2倍、3倍。在时间得分上,基本保持不变,略有下滑趋势。在精确度得分上,继续增强锐度未能使得分发生明显变化,略呈下滑趋势。但继续增强亮度使得分变化明显,不仅严重下滑,而且变成了负值。总体来说,继续增强锐度与亮度并没有达到更好地效果。
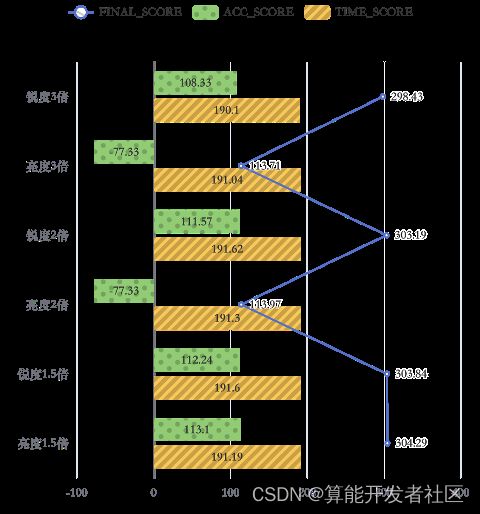
图7:A榜测试集10张图片锐度和亮度分别增强1.5、2、3倍测试结果
5.2.3 锐度与亮度的组合
锐度与亮度增强过度不能使得精确度继续增加,尝试将锐度与亮度同时增强1.5倍,如图8所示,除时间得分略有下降以外,其他指标均有所增加,整体分数有了显著提高。

图8:A榜测试集10张图片锐度、亮度分别增强1.5倍与组合增强1.5倍的对比
确定方法后在B榜测试集上做了7次实验,将时间得分得分最高的一次(test6)提交官网,用最终得分减test6的时间得分,得出其精确度得分。因方法相同精确度均相同,用其它6次的时间得分分别加上test6的精确度得分,即可得出最终得分。如图9,时间得分波动幅度在1分左右,最终得分呈现稳定状态。
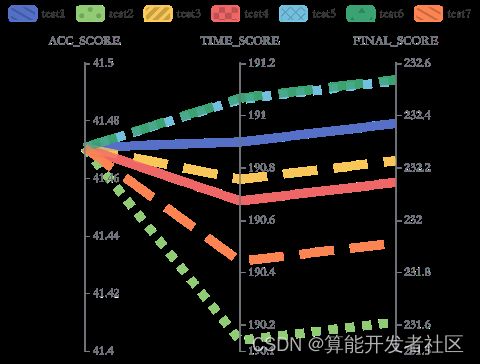
图9:同时增加亮度、锐度1.5倍B 榜测试结果
小结
在模型选择与转化上,选取VGG模型以及转换为int8bmodel格式。在模型的量化上,选择用量化校准迭代次数为230。将测试集所有高大于宽的图片做顺时针旋转90度处理并将所有图片大小强制转换为高576px,宽768px来提高推理速度。为了提高测试精度,同时将锐度与亮度增强1.5倍,最终得分232.53747466,在B榜测试集排名第五。
致谢
在本次竞赛中,特别感谢赛会主办方和出题方给我们这个机会可以将所学用于实际。还要由衷感谢陶欣老师和宋海峰老师。因为有陶老师的技术指导以及宋老师的思路引导,为我们模型的部署以及方法的改进提供了很多帮助,让我们获益匪浅,特在此致以诚挚的谢意。
参考
- S. Wang, Z. Pu, Q. Li, Y. Guo and M. Li, "Edge Computing-Enabled Crowd Density Estimation based on Lightweight Convolutional Neural Network," 2021 IEEE International Smart Cities Conference (ISC2), 2021, pp. 1-7, doi: 10.1109/ISC253183.2021.9562877.
- Saleem, M.S., Khan, M.J., Khurshid, K. et al. Crowd density estimation in still images using multiple local features and boosting regression ensemble. Neural Comput & Applic 32, 16445–16454 (2020). https://doi.org/10.1007/s00521-019-04021-2
- Wang,S.,Pu等.Edge Computing-Enabled Crowd Density Estimation based on Lightweight Convolutional Neural Network[],2021.
- Li Y , Zhang X , Chen D . CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes[J]. IEEE, 2018.
- Abdullah,,Faisal等.Multi-Person Tracking and Crowd Behavior Detection via Particles Gradient Motion Descriptor and Improved Entropy Classifier[J].ENTROPY,2021,23(5).