Transformer 结构详解:位置编码 | Transformer Architecture: The Positional Encoding
注意:本文部分句子采用义译,确保原文意思不变,但不保证用词和原作完全一致,不要抠字眼。
文章目录
- 使用正弦函数为模型添加位置信息
-
- 什么是位置编码?为什么我们需要位置编码。
- 提出的方法
- The intuition
- 其他细节
- 相对位置
- FAQ
-
- 为什么位置编码是和词嵌入相加而不是将二者拼接起来?
- 位置信息层层传递之后不会消失吗?
- 为什么同时使用正弦和余弦?
- 总结
- 原文信息 | Original blog link
- 参考
使用正弦函数为模型添加位置信息
Transformer是只基于自注意力机制的序列到序列架构。因为并行计算能力以及高性能。使得它在NLP领域中大受欢迎。
现在常见的几个深度学习框架都实现了transformer,这让很多学生都能够方便使用到transformer。但是这也存在一个弊端,他会让我们忽略模型的一些细节。
在本文中我,不打算研究它的整体结构,毕竟现在已经有很多优秀的文章介绍其结构了。在本文中我仅对transformer结构的一部分进行探讨,就是位置编码。
当我阅读论文原文1的时候,我的脑海里浮现出来一些问题,但是不幸的是,原文中没有提供足够的信息解答我的疑惑,所以在本文中,我想尝试将位置编码单拎出来,看看它是如何工作的。
注意:为了理解本文,请确保你在阅读本文之前已经熟悉了Transformer的基本架构。如果不懂可以看看相关的教程,比如图解transformer | The Illustrated Transformer
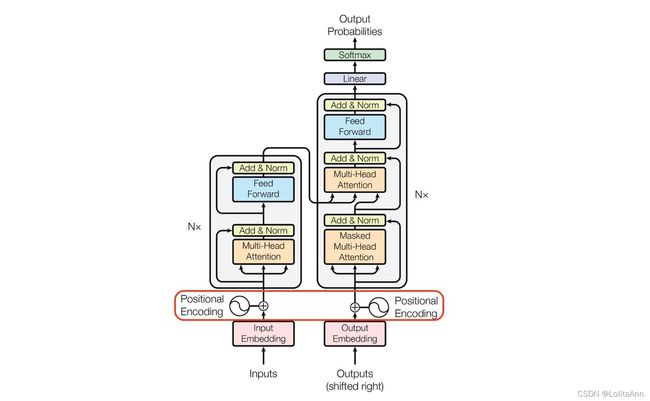
什么是位置编码?为什么我们需要位置编码。
对任何语言来说,句子中词汇的顺序和位置都是非常重要的。它们定义了语法,从而定义了句子的实际语义。RNN结构本身就涵盖了单词的顺序,RNN按顺序逐字分析句子,这就直接在处理的时候整合了文本的顺序信息。
但Transformer架构抛弃了循环机制,仅采用多头自注意机制。避免了RNN较大的时间成本。并且从理论上讲,它可以捕捉句子中较长的依赖关系。
由于句子中的单词同时流经Transformer的编码器、解码器堆栈,模型本身对每个单词没有任何位置信息的。因此,仍然需要一种方法将单词的顺序整合到模型中。
想给模型一些位置信息,一个方案是在每个单词中添加一条关于其在句子中位置的信息。我们称之为“信息片段”,即位置编码。
第一个可能想到的想法是为每个时间步添加一个 [ 0 , 1 ] [0,1] [0,1]范围内的数字,其中0表示第一个单词,1表示最后一个单词。
这会导致什么问题?
问题之一是你无法计算出在特定范围内有多少个单词。换句话说,时间步长 δ δ δ在不同的句子中含义不一致。
作者意思是句子长度不同时,会导致某段区间内词汇数量不一致。

另一个想法是为每个时间步按一定步长线性分配一个数字。 也就是说,第一个单词是“1”,第二个单词是“2”,依此类推。
这种方法的问题在于,随着句子变长,这些值可能会变得特别大,并且我们的模型可能会遇到比训练时更长的句子,此外,我们的模型可能会忽略某些长度的样本。这会损害模型的泛化。
理想情况下,应满足以下标准:
- 每个时间部都有唯一的编码。
- 在不同长度的句子中,两个时间步之间的距离应该一致。
- 模型不受句子长短的影响,并且编码范围是有界的。(不会随着句子加长数字就无限增大)
- 必须是确定性的。
提出的方法
作者提出的编码是一种简单但是很精妙的方法,满足上述所有标准。
首先,它不是单独某个数字,它是一个d维向量,其中包含句子中特定位置的信息。其次,这种编码并没有集成到模型本身中,该向量用于为每个单词提供有关其在句子中位置的信息。
也就是说,其修改了模型的输入,添加了单词的顺序信息。
令
- t t t 是句子中某词汇的位置。
- p t → ∈ R d \overrightarrow{p_{t}} \in \mathbb{R}^{d} pt∈Rd 是其encoding。
- d d d是encoding的维度(其中 d ≡ 2 0 d \equiv{ }_{2} 0 d≡20 )
f : N → R d f: \mathbb{N} \rightarrow \mathbb{R}^{d} f:N→Rd 是将位置转化成位置向量 p t → \overrightarrow{p_{t}} pt 的函数,其定义如下:
p t → ( i ) = f ( t ) ( i ) : = { sin ( ω k ⋅ t ) , if i = 2 k cos ( ω k ⋅ t ) , if i = 2 k + 1 {\overrightarrow{p_{t}}}^{(i)}=f(t)^{(i)}:= \begin{cases}\sin \left(\omega_{k} \cdot t\right), & \text { if } i=2 k \\ \cos \left(\omega_{k} \cdot t\right), & \text { if } i=2 k+1\end{cases} pt(i)=f(t)(i):={sin(ωk⋅t),cos(ωk⋅t), if i=2k if i=2k+1
其中 ω k = 1 1000 0 2 k / d \omega_{k}=\frac{1}{10000^{2 k / d}} ωk=100002k/d1
上边有个 d ≡ 2 0 d \equiv{ }_{2} 0 d≡20,意思就是定义一个 d d d,这个数除2之后余数为0。
我问了一下正在读统计学硕士的同学。

从函数定义可以推导出,频率沿向量维数递减。因此它在波长上形成了一个从 2 π 2 \pi 2π到 10000 ⋅ 2 π 10000 · 2 \pi 10000⋅2π的几何级数。
你也可以把 p t → \overrightarrow{p_{t}} pt 想象成一个sin和cos交替的向量( d d d可以被2整除 ):
p t → = [ sin ( ω 1 ⋅ t ) cos ( ω 1 ⋅ t ) sin ( ω 2 ⋅ t ) cos ( ω 2 ⋅ t ) ⋮ sin ( ω d / 2 ⋅ t ) cos ( ω d / 2 ⋅ t ) ] d × 1 \overrightarrow{p_{t}}=\left[\begin{array}{c} \sin \left(\omega_{1} \cdot t\right) \\ \cos \left(\omega_{1} \cdot t\right) \\ \sin \left(\omega_{2} \cdot t\right) \\ \cos \left(\omega_{2} \cdot t\right) \\ \vdots \\ \sin \left(\omega_{d / 2} \cdot t\right) \\ \cos \left(\omega_{d / 2} \cdot t\right) \end{array}\right]_{d \times 1} pt=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡sin(ω1⋅t)cos(ω1⋅t)sin(ω2⋅t)cos(ω2⋅t)⋮sin(ωd/2⋅t)cos(ωd/2⋅t)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤d×1
The intuition
你可能想知道,正余弦组合怎么能代表一个位置/顺序?
其实很简单,假设你想用二进制格式表示一个数字:

你可以看到不同位置上的数字交替变化。最后一位数字每次都会0、1交替;倒数第二位置上两个交替一次,以此类推。
找规律,第 i i i位置上 2 i 2^i 2i个数据交替一次。
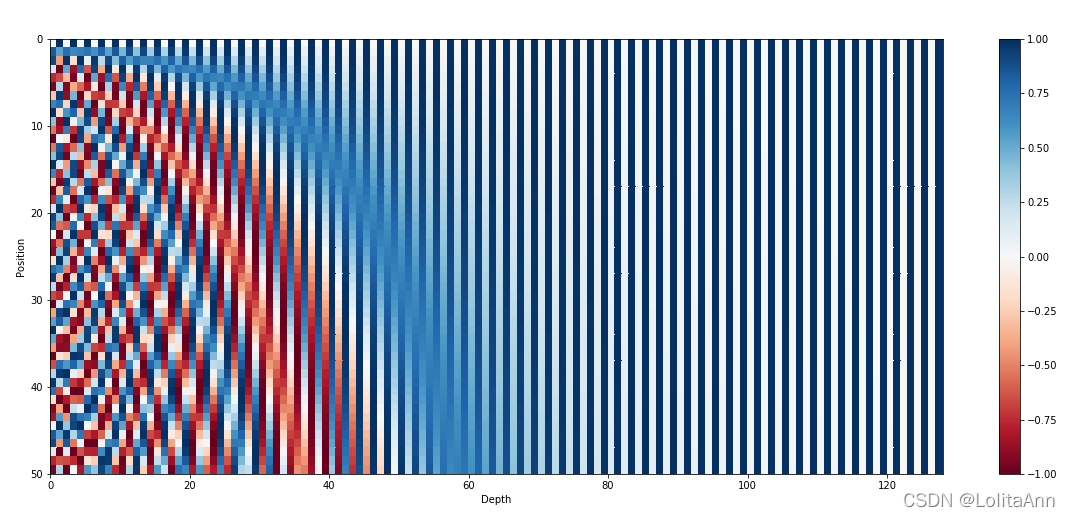
但是在浮点数的世界中使用二进制值是对空间的浪费,所以我们可以用正弦函数代替。事实上,正弦函数也能表示出二进制那样的交替。此外随着正弦函数频率的降低,也可以达到上图红色位到橙色位交替频率的变化。
下图使用正弦函数编码,句子长度为50(纵坐标),编码向量维数128(横坐标)。可以看到交替频率从左到右逐渐减慢。
其他细节
前面我们只提到了位置编码是给句子中的单词添加位置信息的,但具体是怎么实现的呢?
在论文原文中是直接将词嵌入向量和位置编码进行相加,即对于句子 [ w 1 … w n ] [w_1 \dots w_n] [w1…wn]中的每个词 w t w_t wt, 最终的输入如下:
ψ ′ ( w t ) = ψ ( w t ) + p t → \psi^{\prime}\left(w_{t}\right)=\psi\left(w_{t}\right)+\overrightarrow{p_{t}} ψ′(wt)=ψ(wt)+pt
- p t → \overrightarrow{p_{t}} pt 位置编码
- ψ ( w t ) \psi\left(w_{t}\right) ψ(wt) 词嵌入
为了实现,这个所以我们需要让位置编码的维数和词嵌入向量的维数相等。
d word embedding = d postional embedding d_{\text {word embedding }}=d_{\text {postional embedding }} dword embedding =dpostional embedding
相对位置
正弦位置编码的另一个特点是,可以让模型获取相对位置。以下是原文中的一段话:
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k k k, P E p o s + k PE_{pos+k} PEpos+k can be represented as a linear function of P E p o s PE_{pos} PEpos.
但为什么这一说法成立?为了充分理解原因,可以看一下这篇文章2(点右上角参考)。不看也可以,我在这里总结了一个简短一点的版本:
对于对应频率 ω k \omega_{k} ωk的每个正余弦对,有一个线性变换 M ∈ R 2 × 2 M \in \mathbb{R}^{2 \times 2} M∈R2×2 (独立于 t t t ),使下列等式成立:
M . [ sin ( ω k ⋅ t ) cos ( ω k ⋅ t ) ] = [ sin ( ω k ⋅ ( t + ϕ ) ) cos ( ω k ⋅ ( t + ϕ ) ) ] M .\left[\begin{array}{l} \sin \left(\omega_{k} \cdot t\right) \\ \cos \left(\omega_{k} \cdot t\right) \end{array}\right]=\left[\begin{array}{l} \sin \left(\omega_{k} \cdot(t+\phi)\right) \\ \cos \left(\omega_{k} \cdot(t+\phi)\right) \end{array}\right] M.[sin(ωk⋅t)cos(ωk⋅t)]=[sin(ωk⋅(t+ϕ))cos(ωk⋅(t+ϕ))]
证明:
令 M M M 是一个 2 × 2 2 \times 2 2×2的矩阵,我们想得到 u 1 , v 1 , u 2 u_{1}, v_{1}, u_{2} u1,v1,u2 and v 2 v_{2} v2 使下式成立:
[ u 1 v 1 u 2 v 2 ] ⋅ [ sin ( ω k ⋅ t ) cos ( ω k ⋅ t ) ] = [ sin ( ω k ⋅ ( t + ϕ ) ) cos ( ω k ⋅ ( t + ϕ ) ) ] \left[\begin{array}{ll} u_{1} & v_{1} \\ u_{2} & v_{2} \end{array}\right] \cdot\left[\begin{array}{l} \sin \left(\omega_{k} \cdot t\right) \\ \cos \left(\omega_{k} \cdot t\right) \end{array}\right]=\left[\begin{array}{l} \sin \left(\omega_{k} \cdot(t+\phi)\right) \\ \cos \left(\omega_{k} \cdot(t+\phi)\right) \end{array}\right] [u1u2v1v2]⋅[sin(ωk⋅t)cos(ωk⋅t)]=[sin(ωk⋅(t+ϕ))cos(ωk⋅(t+ϕ))]
使用三角函数的定理,我们可以将等式右边展开如下:
[ u 1 v 1 u 2 v 2 ] ⋅ [ sin ( ω k . t ) cos ( ω k . t ) ] = [ sin ( ω k . t ) cos ( ω k . ϕ ) + cos ( ω k . t ) sin ( ω k . ϕ ) cos ( ω k . t ) cos ( ω k . ϕ ) − sin ( ω k . t ) sin ( ω k . ϕ ) ] \left[\begin{array}{ll} u_{1} & v_{1} \\ u_{2} & v_{2} \end{array}\right] \cdot\left[\begin{array}{l} \sin \left(\omega_{k} . t\right) \\ \cos \left(\omega_{k} . t\right) \end{array}\right]=\left[\begin{array}{l} \sin \left(\omega_{k} . t\right) \cos \left(\omega_{k} . \phi\right)+\cos \left(\omega_{k} . t\right) \sin \left(\omega_{k} . \phi\right) \\ \cos \left(\omega_{k} . t\right) \cos \left(\omega_{k} . \phi\right)-\sin \left(\omega_{k} . t\right) \sin \left(\omega_{k} . \phi\right) \end{array}\right] [u1u2v1v2]⋅[sin(ωk.t)cos(ωk.t)]=[sin(ωk.t)cos(ωk.ϕ)+cos(ωk.t)sin(ωk.ϕ)cos(ωk.t)cos(ωk.ϕ)−sin(ωk.t)sin(ωk.ϕ)]
普通的矩阵乘法运算将其拆开:
u 1 sin ( ω k . t ) + v 1 cos ( ω k . t ) = cos ( ω k . ϕ ) sin ( ω k . t ) + sin ( ω k . ϕ ) cos ( ω k . t ) u 2 sin ( ω k ⋅ t ) + v 2 cos ( ω k . t ) = − sin ( ω k . ϕ ) sin ( ω k . t ) + cos ( ω k . ϕ ) cos ( ω k . t ) \begin{aligned} &u_{1} \sin \left(\omega_{k} . t\right)+v_{1} \cos \left(\omega_{k} . t\right)=\cos \left(\omega_{k} . \phi\right) \sin \left(\omega_{k} . t\right)+\sin \left(\omega_{k} . \phi\right) \cos \left(\omega_{k} . t\right) \\ &u_{2} \sin \left(\omega_{k} \cdot t\right)+v_{2} \cos \left(\omega_{k} . t\right)=-\sin \left(\omega_{k} . \phi\right) \sin \left(\omega_{k} . t\right)+\cos \left(\omega_{k} . \phi\right) \cos \left(\omega_{k} . t\right) \end{aligned} u1sin(ωk.t)+v1cos(ωk.t)=cos(ωk.ϕ)sin(ωk.t)+sin(ωk.ϕ)cos(ωk.t)u2sin(ωk⋅t)+v2cos(ωk.t)=−sin(ωk.ϕ)sin(ωk.t)+cos(ωk.ϕ)cos(ωk.t)
通过求解上述方程我们可以得到:
u 1 = cos ( ω k ⋅ ϕ ) v 1 = sin ( ω k ⋅ ϕ ) u 2 = − sin ( ω k ⋅ ϕ ) v 2 = cos ( ω k ⋅ ϕ ) \begin{array}{ll} u_{1}=\cos \left(\omega_{k} \cdot \phi\right) & v_{1}=\sin \left(\omega_{k} \cdot \phi\right) \\ u_{2}=-\sin \left(\omega_{k} \cdot \phi\right) & v_{2}=\cos \left(\omega_{k} \cdot \phi\right) \end{array} u1=cos(ωk⋅ϕ)u2=−sin(ωk⋅ϕ)v1=sin(ωk⋅ϕ)v2=cos(ωk⋅ϕ)
所以最终的变换矩阵 M M M 是:
M ϕ , k = [ cos ( ω k ⋅ ϕ ) sin ( ω k ⋅ ϕ ) − sin ( ω k ⋅ ϕ ) cos ( ω k ⋅ ϕ ) ] M_{\phi, k}=\left[\begin{array}{cc} \cos \left(\omega_{k} \cdot \phi\right) & \sin \left(\omega_{k} \cdot \phi\right) \\ -\sin \left(\omega_{k} \cdot \phi\right) & \cos \left(\omega_{k} \cdot \phi\right) \end{array}\right] Mϕ,k=[cos(ωk⋅ϕ)−sin(ωk⋅ϕ)sin(ωk⋅ϕ)cos(ωk⋅ϕ)]
通过上述推到可以看到,最终的转换不依赖于 t t t。注意,可以发现矩阵 M M M与旋转矩阵非常相似。
旋转矩阵是一个数学概念,这里需要自己查一下相关资料。
类似地,我们可以为其他正余弦对找到 M M M,最终我们可以将 p t + ϕ → \overrightarrow{p_{t+\phi}} pt+ϕ表示为任何固定偏移量 ϕ \phi ϕ的 p t → \overrightarrow{p_{t}} pt的线性函数。这一特性使模型很容易学到相对位置信息。
正弦位置编码的另一个特性是相邻时间步之间的距离是对称的,并随时间衰减。
下图是所有时间步位置编码的点乘积可视化:

FAQ
为什么位置编码是和词嵌入相加而不是将二者拼接起来?
我找不到这个问题相关的理论依据。求和(与拼接相比)保存了模型的参数,现在我们将初始问题改为“在单词中添加位置嵌入有缺点吗?” 。这我会回答,不一定!
首先,如果我们回想一下上边的第一张可视化图,我们会发现位置编码向量的前几个维度用于存储关于位置的信息(注意,虽然我们的示例很小只有128维,但论文中的输入维度是512)。由于Transformer中的嵌入是从头开始训练的,所以设置参数的时候,可能不会把单词的语义存储在前几个维度中,这样就避开了位置编码。
作者意思是,虽然没有进行直接concat,但是进行了隐式concat。位置编码前半段比较有用,所以在编码嵌入向量的时候,将其语义信息往后放。

因此我认为最终的Transformer可以将单词的语义与其位置信息分开。此外,也没有理由支撑将二者分开拼接有什么好处。也许这样相加为模型提供比较好的特征。
更多相关信息可以看:
- Why add positional embedding instead of concatenate? #1591 3
- Discussion:Positional Encoding in Transformer4
位置信息层层传递之后不会消失吗?
Transformer里加了残差连接,所以模型输入的信息可以有效地传播到其它层。
为什么同时使用正弦和余弦?
个人认为,只有同时使用正弦和余弦,我们才能将 s i n e ( x + k ) sine(x+k) sine(x+k)和 c o s i n e ( x + k ) cosine(x+k) cosine(x+k)表示为 s i n ( x ) sin(x) sin(x)和 c o s ( x ) cos(x) cos(x)的线性变换。好像不能只用正弦或者只用余弦就能达到这种效果。如果你能找到单个正余弦的线性变换,可以在评论区补充。
总结
感谢阅读,希望这篇文章能对你有用。如果有问题欢迎批评指正。
引用格式:
@article{kazemnejad2019:pencoding,
title = "Transformer Architecture: The Positional Encoding",
author = "Kazemnejad, Amirhossein",
journal = "kazemnejad.com",
year = "2019",
url = "https://kazemnejad.com/blog/transformer_architecture_positional_encoding/"
}
原文信息 | Original blog link
原文链接:Transformer Architecture: The Positional Encoding
作者信息:
参考
Attention Is All You Need ↩︎
Linear Relationships in the Transformer’s Positional Encoding ↩︎
Why add positional embedding instead of concatenate? #1591 ↩︎
Discussion:Positional Encoding in Transformer ↩︎