机器学习(3)特征提取2 -- 文本特征提取(包括中文文本特征提取)
目录
一、文本特征提取
1、基础理论
2、过程
3、API介绍
4、特征值转化为二维矩阵
5、特征值转化为稀疏矩阵
代码
二、中文文本特征提取
1、字符串列表中文处理
1-1、得到初始数据集
1-2、创建词语生成器
1-3、分割得到的中文字符串
1-4、返回列表字符串
2、稀疏矩阵
3、二维矩阵
一、文本特征提取
1、基础理论
分隔依据:以空格作为分隔。
排序依据:按照顺序进行排序(即数字->A->Z)
(注:标点符号和单个字符忽略。)
stop_words( )停用单词
2、过程
1、获取数据集
2、实例化转换器类
3、提取特征值
3、API介绍
sklearn.feature_extraction.text.CountVectorizer
4、特征值转化为二维矩阵
# 数据集
data = ['life is short, i like like AI', 'life is short, i dislike dislike AI']
# 提取特征值,转化为二维矩阵
def Matrix():
# 1、实例化转换器类
transfer = CountVectorizer()
# 2、提取特征值
feature_data = transfer.fit_transform(data)
print('二维矩阵特征值:\n', feature_data.toarray())
print('特征名字:', transfer.get_feature_names())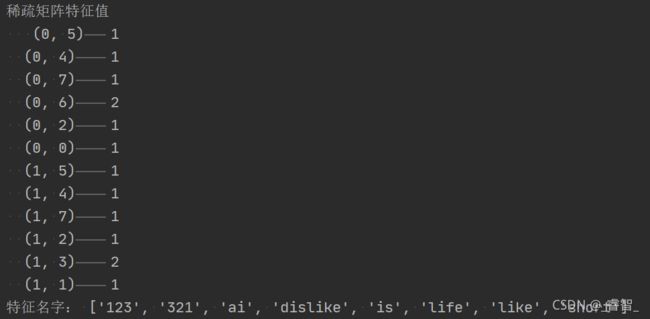
5、特征值转化为稀疏矩阵
# 数据集
data = ['life is short, i like like AI', 'life is short, i dislike dislike AI']
# 提取特征值,转化为稀疏矩阵
def Sparse():
# 1、实例化转换器类
transfer = CountVectorizer()
# 2、提取特征值
feature_data = transfer.fit_transform(data)
print('稀疏矩阵特征值\n', feature_data)
print('特征名字:', transfer.get_feature_names())
(按照顺序进行排序(即数字->A->Z),标点符号和单个字符忽略。)
代码
# 文本特征提取
from sklearn.feature_extraction.text import CountVectorizer
# 数据集
data = ['life is short, i like like AI 123', 'life is short, i dislike dislike AI 321']
# 提取特征值,转化为稀疏矩阵
def Count_Sparse():
# 1、实例化转换器类
transfer = CountVectorizer()
# 2、提取特征值
feature_data = transfer.fit_transform(data)
print('稀疏矩阵特征值\n', feature_data)
print('特征名字:', transfer.get_feature_names())
# 提取特征值,转化为二维矩阵
def Count_Matrix():
# 1、实例化转换器类
transfer = CountVectorizer()
# 2、提取特征值
feature_data = transfer.fit_transform(data)
print('二维矩阵特征值:\n', feature_data.toarray())
print('特征名字:', transfer.get_feature_names())
if __name__ == '__main__':
Count_Sparse() #稀疏矩阵(特征值)
Count_Matrix() #二维矩阵(特征值)
二、中文文本特征提取
1、字符串列表中文处理
1-1、得到初始数据集
# 数据集
data = ['我虽然是一只小菜鸡', '目前比较菜', '但是在不断干饭', '努力成为战斗鸡']1-2、创建词语生成器
首先需要把列表化字符串形式。,否则cut会报错。
# 创建生成器
generator = jieba.cut(str(text))
print(generator)![]()
1-3、分割得到的中文字符串
# 空格分割得到中文
Chinese = " ".join(generator)
print(Chinese)![]()
1-4、返回列表字符串
return list(Chinese)2、稀疏矩阵
# 提取特征值,转化为稀疏矩阵
def Count_Sparse():
# 1、获取中文数据集
Chinese = Chinese_Data(data)
# 2、实例化转换器类
transfer = CountVectorizer(analyzer ='char',lowercase=False)
# 3、提取特征值
feature_data = transfer.fit_transform(Chinese)
print('稀疏矩阵特征值\n', feature_data)
print('特征名字:', transfer.get_feature_names())稀疏矩阵特征值
(0, 3) 1
(1, 0) 1
(2, 1) 1
(3, 0) 1
(4, 17) 1
(5, 0) 1
(6, 26) 1
(7, 23) 1
(8, 0) 1
(9, 21) 1
(10, 0) 1
(11, 5) 1
(12, 12) 1
(13, 0) 1
(14, 14) 1
(15, 25) 1
(16, 0) 1
(17, 29) 1
(18, 0) 1
(19, 1) 1
(20, 0) 1
(21, 2) 1
(22, 0) 1
(23, 0) 1
(24, 0) 1
: :
(51, 15) 1
(52, 28) 1
(53, 0) 1
(54, 1) 1
(55, 0) 1
(56, 2) 1
(57, 0) 1
(58, 0) 1
(59, 0) 1
(60, 1) 1
(61, 0) 1
(62, 11) 1
(63, 10) 1
(64, 0) 1
(65, 16) 1
(66, 7) 1
(67, 0) 1
(68, 18) 1
(69, 19) 1
(70, 0) 1
(71, 29) 1
(72, 0) 1
(73, 1) 1
(74, 0) 1
(75, 4) 1
特征名字: [' ', "'", ',', '[', ']', '一', '不', '为', '但', '前', '力', '努', '只', '在', '小', '干', '成', '我', '战', '斗', '断', '是', '比', '然', '目', '菜', '虽', '较', '饭', '鸡']3、二维矩阵
# 提取特征值,转化为二维矩阵
def Count_Matrix():
# 1、获取中文数据集
Chinese = Chinese_Data(data)
# 2、实例化转换器类
transfer = CountVectorizer(analyzer ='char',lowercase=False)
# 3、提取特征值
feature_data = transfer.fit_transform(Chinese)
print('二维矩阵特征值:\n', feature_data.toarray())
print('特征名字:', transfer.get_feature_names())二维矩阵特征值:
[[0 0 0 ... 0 0 0]
[1 0 0 ... 0 0 0]
[0 1 0 ... 0 0 0]
...
[0 1 0 ... 0 0 0]
[1 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
特征名字: [' ', "'", ',', '[', ']', '一', '不', '为', '但', '前', '力', '努', '只', '在', '小', '干', '成', '我', '战', '斗', '断', '是', '比', '然', '目', '菜', '虽', '较', '饭', '鸡']