零基础边缘端智能安防训练营 | Lesson 3
5个课时,落地AI应用!
欢迎大家来到AidLux零基础边缘端智慧安防训练营~

前面两节课,主要介绍了AI项目的一些背景,及使用AidLux实现AI功能的一些方式。
在第三节课,我们主要完成越界识别项目中人体检测模型的训练和部署测试,本节课内容框架如下:
1 Crowdhuman数据集下载及说明
2 人体检测数据集标注文件转换
3 云服务器训练人体检测模型
4 PC端Pytorch推理测试
5 Aidlux端模型推理测试
6 课堂小作业
1. Crowdhuman数据集下载及说明
因为项目需要人体检测的模型,所以先带大家训练一个检测模型,并转换成AidLux可以部署的方式,进行推理测试。
人体检测的数据集有很多,这里采用的是旷视开源的Crowdhuman数据集,官网是:http://www.crowdhuman.org

△图据http://www.crowdhuman.org
Crowdhuman数据集包含三个方面:15000张的训练数据集、4370张的验证数据集、5000张的测试数据集,其中训练集和验证集都有标注信息。
△图据http://www.crowdhuman.org
按照官网的提升信息下载之后,得到的文件是这样的。

包含train、val和test数据集的方式,共24370张图片,总共有13G。
考虑到数据集文件比较大,大家可以和AidLux AI开发者交流down,以便后期自己训练时挑选使用。

为了便于大家快速尝试训练人体检测模型,在后续的操作演示中,主要采用了val数据集4370张图片,给大家整体流程串通测试用。
即用CrowdHuman_val.zip和annotation_val.odgt,本节课的资料包存放在lesson3资料包/lesson3_data文件夹中。

大家可以根据自己的需要,后期选择是否将训练集也都添加进去。
2. 人体检测数据集标注文件转换
lesson3的资料包课件总共有三个:
一个是各类代码lesson3_codes,一个是数据集lesson3_data,一个是需要安装的软件。

2.1 Crowdhuman数据集整理
在lesson3_data数据集中,新建一个文件夹Crowdhuman_data,并将网盘下载的Crowdhuman_val.zip和annotation_val.odgt,全都拷贝到Crowdhuman_data中。
将其中的CrowdHuman_val.zip解压缩,可以得到一个Images文件夹,里面包含4370张图片。
将Images文件夹拷贝到Crowdhuman_data路径下,并修改成JPEGImages,此外新建一个Annotations,如下图所示。
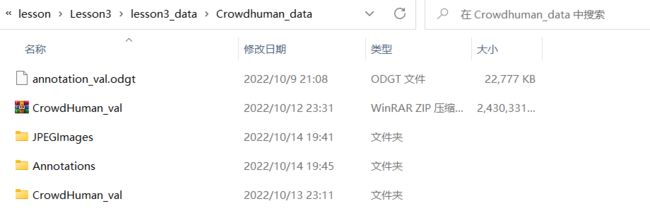
即JPEGImages文件夹里面有val数据集的4370张图片,而Annotations文件夹是空的。
下面编写代码,将annotation_val.odgt中的标注信息提取出来,变成和4370张图片对应的XML格式。
tips:如果是使用train训练集的15000张图片进行训练,则将三个训练集中的所有图片都拷贝到JPEGImages中,其他的都是一样的。
2.2 标注文件odgt格式转换成xml格式
在lesson3_codes/data_prepare_code文件夹中,放置了编写数据清洗的脚本data_code.py。
运行脚本需要使用VScode编程软件打开data_code.py的文件夹,首先修改其中的roadlabels、roadimages、fpath三个路径。
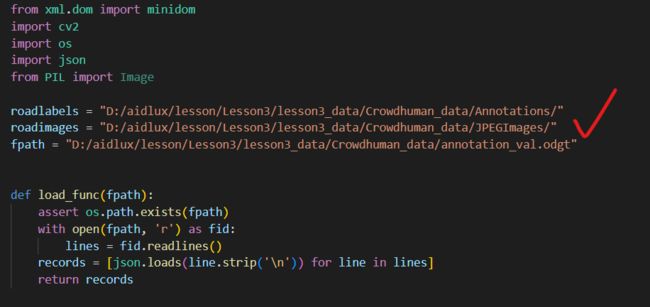
需要注意的是Crowdhuman中,有三种标注内容:vbox、fbox、hbox,分别对应:可看到的人体、完整人体、人脸。
本次训练过程中主要使用完整人体图像进行训练,因此主要用到fbox的标签。
再修改下面的两个地方,fbox即表示提取annotation_val.odgt中完整人体的检测框信息,而person表示转换成xml后人体的标签名称信息。

运行代码后,可以看到VScode运行界面会对于每张对应的图片标注信息,进行提取处理。

最终在lesson3_data/Crowdhuman_data/Annotations中可以得到4370张VOC格式的xml文件。
2.3 Labelimg标注验证
前面生成好标注文件后,大家最好再校验一下,看生成的是否正确,怎么校验呢?
大家还记得在lesson3的资料包中,还有个lesson3_software的文件夹吧,这里面就是一个LabelImg的标注软件,可以通过它来进行校验。
找到LabelImg.exe的文件,直接点击打开就行。

将Crowdhuman_data/JPEGImages里面的xml,复制最前面的10个左右xml,粘贴到文件夹Crowdhuman_data/Annotations里面。

再使用Labelimg里面的Open Dir打开Annotations文件夹。

可以看到我们生成的标注信息,检查一下是否有标注错误的。如果都没有,那说明其他生成的也是对的。

验证没问题后,将Annotations文件夹里面,刚刚拷贝的图片全部删除。
到这一步为止,我们训练时需要用到的4370张样本集就准备好了。
tips:这里主要用的val里面的数据集,如果用train里面的数据集,大家也可以用同样的方式进行梳理准备。
2.4 训练/验证数据集整理
本次训练营主要采用Yolov5的算法,因此我们需要将上面VOC格式转换成Yolov5可以训练的格式。
所以我们还准备了数据清理&切分的脚本,即:
lesson3_code/data_prepare_code/train_data_split.py。
为了让大家更好的尝试,也将清洗切分的每一步都整理成了流程。(大家如果平时也训练Yolo算法,可以按照自己的方式来操作。)
(1)新建train_data文件夹
在lesson3_data文件夹中,新建一个train_data文件夹。
并在train_data里面新建一个images_label_split/crowdhuman_val文件夹,且将前面2.2转换好对应的JPEGImages和Annotations,拷贝到crowdhuman_val文件夹里面。

(2)数据集清洗
先来解释一下为什么要清洗数据集。
实际项目标注的数据集,会有各种问题。比如有图片,但是没有标注xml;或者有的目标标注的太小,像10*10像素这种。针对一些标注的问题,可以进行梳理。
清洗的代码,即train_data_split.py中的这个阶段一的部分。

首先修改最下面的数据集路径,即刚刚新建的那个数据集路径。

运行train_data_split.py代码,会进行清洗梳理,并在最后会用代码显示标注信息结果。
大家可以按“Enter”键,查看是否有标错的图片,确认一下。

(3)训练集&验证集切分
确认图片和标签文件没有问题后,我们还需要对标注好的4370张图片划分成训练集和验证集。
这里我们按照8:2的方式来切分,即80%是训练集,20%是验证集。
所用的代码,主要是train_data_split.py中的阶段二的部分。
需要注意的是,因为只想运行阶段二的代码,所以得将阶段一的所有代码都注释掉。
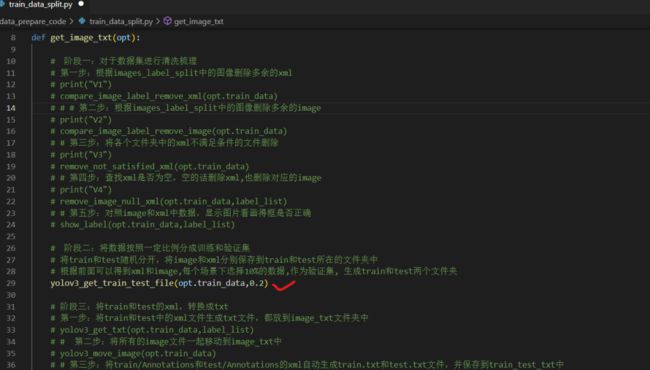
做完注释,运行代码,会对于4370张图片进行逐一读取。

在train_data文件夹中,我们可以看到多了train和test两个文件夹,里面是对应的image和xml文件。

3. 云服务器训练人体检测模型
3.1 云服务器简介
有了人体数据集,我们就可以训练检测模型了,而训练模型需要用到GPU服务器。
有GPU服务器的同学,大家可以直接用自己的电脑训练。没有也没关系,我们也给大家准备了使用云服务训练模型的教程。
本次课程采用的算力平台主要是AutoDL AI算力云,官网https://www.autodl.com。
大家自行选择。

注册完毕后,进入后台的主页面,点击左上角的“算力市场”。
可以看到不同区域,有不同的空闲服务器,每台服务器的显卡、算力和价格都不同,大家可以根据自己的需求进行选择。

新注册的训练一下Yolo数据集是够用了。

3.2 查看符合条件的云网盘
因为后面训练都是在云服务器上,所以需要将数据集和代码都先上传到云服务器的网盘里面,便于后续操作。
不过这里还有个要注意的地方,选择的网盘与服务器的地区要保持一致,所以最好是确认列表内的实例中,哪些区域的算力设备符合自己租赁的范围之后,再做选择
这里使用的是内蒙的服务器,后面实例购买的时候,同样是内蒙的实例,就可以在系统盘中直接找到相应的文件。
确定相应的地方的网盘,上传代码文件等。

3.3 训练&验证集图片上传
我们将前面的一些文件,传输到“我的网盘”里面。主要上传三个文件:
(1)训练&验证集图片
将train_data文件夹中的images_label_split文件夹删除,只留下刚刚划分的train和test文件夹。

为了上传方便,将train_data文件夹,压缩成一个train_data.zip。

(2)数据集整理代码
将data_prepare_code文件夹,进行压缩,变成data_prepare_code.zip文件夹。
(3)Yolov5训练代码
将Yolov5_code训练代码,进行压缩,变成yolov5_code.zip。

(4)后台上传文件
点击AutoDL后台-我的网盘,将刚刚的三个zip文件进行上传。

3.4 新建实例设备
到了这里,所需的代码、数据集就都准备好了。
接下来可以准备新建一个实例设备操作。
选择和网盘对应的区的实例。

挑选GPU服务器时,右侧展示的都是单卡的价格,要注意有的设备必须要多张卡一起租。
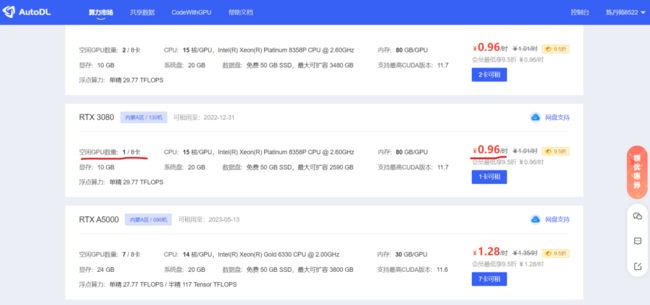
点击进入后,可以修改两个地方,一个是GPU数量,一个是新建实例的基础镜像。
GPU数量选择1,表示单卡;新建实例镜像,选择了Pytorch的版本。
在结算的地方,可以看到可用的代金券。
点击“立即创建”后,就可以看到创建的实例了。
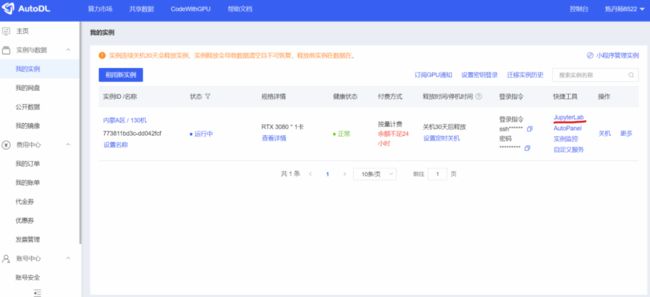
点击右面的“JupyterLab”,可以进入控制台页面。
可以点击下面的“终端”,打开一个终端页面,就可以进行操作了。
如果一个终端页面不够操作的话,可以点击左上方的“+”号,新增加几个终端页面。

在上面,可以看到autodl-nas,这个就是我们刚刚使用的网盘。

进入autodl-nas文件夹后,里面有前面新上传的三个zip文件。

将三个zip文件,使用unzip的方式进行解压。

最后可以看到,三个文件夹都被解压缩成功。

3.5 标注文件xml格式转换txt格式
先查看一下训练数据集train_data的路径,因为会涉及到转换后的txt路径,在云服务器上运行加训练。
先cd train_data文件夹,再输入pwd,可以看到这时的数据集路径是:/root/autodl-nas/train_data。

然后再去修改代码中的路径,首先cd data_prepare_code文件夹里,再vim train_data_split.py,使用前面的阶段三中的代码,将标注的人体xml文件转换成txt文件。

vim train_data_split.py后,打开页面,拖到最下方,即这个部分。

按键盘上的“i”,进入代码的编辑状态,移动到路径处,修改成云服务器上对应的路径,我们的是/root/autodl-nas/train_data,大家可以对应修改。

修改完成后,按键盘上的Esc键,跳出编辑状态。
再输入“:”,会跳出输入框,再输入"wq!",表示对于该修改内容,保存编辑强制退出,回到原始页面。
因为云服务器我们刚刚新建实例的时候,没有安装任何安装包。所以先pip install opencv-python,安装一下。

将xml转换成txt格式进行中。
![]()
再进入train_data文件夹中,会发现多了两个文件夹,训练时可以使用。

3.6 训练人体检测模型
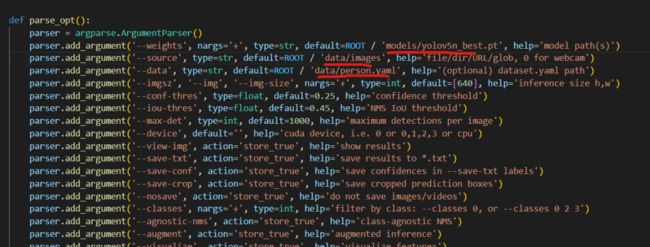
训练人体模型,主要就用到/autodl-nas/yolov5_code文件,在训练之前还要修改一下参数。
(1)新建person.yaml
因为训练的是人体检测模型,所以在yolov5_code/data文件夹中,新增一个person.yaml。
这一步需要注意的是,训练集和验证集的路径都要修改一下,此外还有类别数,以及类别标签。

(2)修改train.py参数
而在yolov5_code/train.py文件中,主要修改models初始化模型的路径,这里使用的yolov5n的模型权重。
cfg即模型对应的网络结构路径,data是新增的person.yaml路径。
此外还有epochs训练迭代的次数,batch-size大小,imgsz可以修改,这里默认640。

(3)修改models/yolov5n.yaml
修改其中的类别数量,因为人体就一个类别,修改成1。

(4)训练人体检测模型
因为训练的时候,需要一系列的库文件,所以回到yolov5_code的路径下,输入 pip install -r requirements,安装所需的库文件。
大家如果遇到tqdm安装的报错,可以输入pip install tqdm,看下有哪些版本,找对应的版本下载。
安装完成后,输入python train.py,就可以开始训练了。

训练过程中,一般会得到两个模型:
一个是best.pt,即epoch迭代的过程中,map精度对比比较好保存的模型;
一个是last.pt,即迭代过程中,最后一次epoch保存的模型。

在后面测试的时候,主要使用best.pt文件。
3.7 下载检测模型
在AutoDL的我的网盘,找到runs下面最新训练人体检测模型,路径可以参考:

将best.pt模型下载下来,修改成yolov5n_best.pt,并放到资料包代码文件夹中。

4. PC端Pytorch推理测试
云服务器主要是用来训练,测试部分包括模型转换,都还是在我们自己的PC电脑上。
当我们训练出一个人体检测模型时,比如得到最轻量型的yolov5n.pt文件之后,先在PC端电脑上,用人体检测模型针对图片和视频进行效果测试,这次还是采用训练营重新修改编写的代码。
4.1 Pytorch功能库的安装
我们特意找了一台空白的电脑,没有安装任何功能库的电脑进行整体的测试,大家可以按照步骤操作,安装所需的库。
(1)Pytorch库的安装
如果没有安装Pytorch会报错。

首先打开Pytorch的官网:https://pytorch.org,根据电脑配置,进行选择。
比如我们现在用的电脑系统是Window系统,没有GPU显卡。

下方的显示窗口会跳出pip3 install torch torchvision torchaudio,当然在下载的时候为了网络加速,还添加了清华源。
组成下载代码:
pip3 install torch torchvision torchaudio -i
https://pypi.tuna.tsinghua.edu.cn/simple

最终很快下载好Pytroch,及torchvision等一系列的相关函数库。

(2)其他相关库下载
除了Pytorch,代码中还有一系列的依赖库,这里也列出相关的下载链接,可以一个个下载安装。
Pandas下载:
pip3 install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
yaml下载:
pip3 install pyyaml -i https://pypi.tuna.tsinghua.edu.cn/simple
tqdm下载:
pip3 install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple
matplotlib下载:
pip3 install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
seaborn下载:
pip3 install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
scipy下载:
pip3 install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
ipython下载:
pip3 install ipython -i https://pypi.tuna.tsinghua.edu.cn/simple
4.2 针对图片进行推理测试
我们使用yolov5的模型,对于images里面的图片进行推理,测试一下效果。
打开detect_image.py文件,这里主要修改代码中的模型、图片路径、yaml文件。
使用Run->"Run Without Debuging",运行后可以得到一张张推理的图片效果。

4.3 视频进行推理测试
因为实际项目中主要使用视频进行推理,所以我们再加载视频,进行推理测试。
视频处理的代码,我们也重新进行了梳理,放在detect_video.py中。
主要修改模型路径、视频路径以及yaml的路径。

运行后,可以得到视频的推理结果。

5. AidLux端模型推理测试
在PC端测试完之后,我们要在安装了AidLux的边缘设备上使用。
在前面我们介绍过,AidLux针对推理部分,在底层进行了加速优化。要将pt模型移植到AidLux上使用,需要进行转换模型,进行修改推理代码的操作。
5.1 pt模型转换成tflite模型
模型转换的文件是export.py文件,在AidLux中主要运行的是tflite的方式,因此主要修改其中的三个地方。
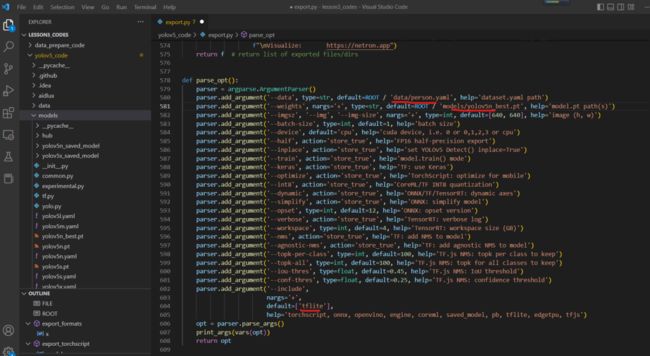
因为需要tensorflow,没有安装库的情况下,运行时会报错:

所以再输入:
pip3 install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple,下载tensorflow库。

安装好再运行export.py文件,在models文件夹下面,可以看到生成的yolov5n-fp16.tflite文件。

5.2 AidLux视频推理代码理解
本次课程在AidLux中使用的推理测试代码,已经放到yolov5_code/aidlux文件夹的yolov5.py中了,大家也可以将训练好的tflite放到aidlux文件夹中。
AidLux有专属的函数接口AidLite,大家可以在
https://docs.aidlux.com/#/intro/ai/ai-aidlite,查看相关的介绍和使用说明。
这其中的代码和原本PC端的代码有一些不同,这里也梳理讲解一下,主要分为三个部分:
(1)加载相关的函数库

(2)模型初始化及加载
这里主要用到两个函数接口,一个是aidlite_gpu.aidlite()和aidlite.ANNMode()。

AidLite初始化的说明:

AidLite加载模型的说明:

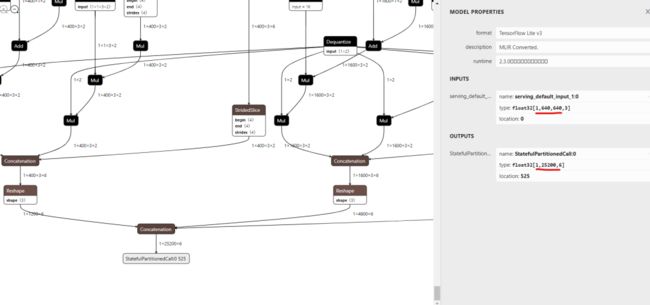
此外还有两行in_shape,out_shape,这里可以通过netron查看一下相关的模型参数。
我们使用https://netron.app/,打开刚刚的yolov5n_best-fp16.tflite文件,点击最下方的输出单元,可以看到输出的信息。
(3)视频读取&模型推理代码
视频读取和模型推理的地方也比较简单,这里做了详细描述,大家可以对照查看。

5.3 代码复制到AidLux中
和第二节课中一样,我们将yolov5的代码,全部上传到AidLux的home下面。
操作方式可以在远程连接的网页版AidLux中,打开文件浏览器,进入home下方,点击上传按钮,将lessons3_codes进行上传。

5.4 远程连接AidLux软件
在第二节课中,我们讲解了使用SSH,连接到AidLux的方式。
大家也可以远程连接到lesson3_codes,当看到红色部分的SSH:AIDLUX,即说明远程连接成功。

5.5 推理测试AidLux代码
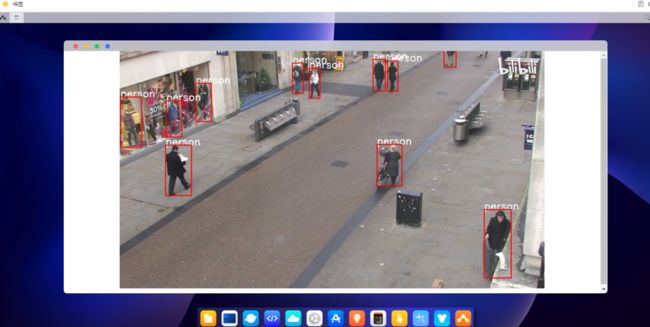
打开aidlux文件夹中的yolov5.py进行视频推理测试,在手机版本的AidLux和PC端网页的AidLux中,都可以看到推理的显示结果。
tips:需要注意的是,在运行的时候,需要把手机版本里面的aidlux页面叉掉,免得会有冲突,运行的线程会直接被killed掉。
6.课堂小作业
这节课我们主要学习了如何使用云服务器,训练yolov5的人体检测模型。并将训练好的检测模型,转换成AidLux可以使用的tflite模型,且对一个图片和视频进行推理测试,看到实际的效果。
本节课最后留一个小作业。
大家可以随便拍摄一个小视频。并使用yolov5n_best-fp16.tflite模型进行推理测试,并将推理的得到的检测框分数绘制到每个人体上,同时检测框变为蓝色。比如下方的效果:

以上就是第三节课的内容。
大家可以进行AidLux AI开发者交流,有AidLux工程师和江大白等众多AI行业专家给予技术指导以及进行交流互动。
完成作业的同学可以将完成的Demo视频或截图交流分享,遇到问题的同学也可以提问~
本节课所需的数据集、资料包,大家可以在里面获取呦~