Doris-集成其他系统(四)
目录
- 0、准备
- 1、Spark 读写 Doris
-
- 1.1 准备 Spark 环境
- 1.2 使用 Spark Doris Connector
-
- 1.2.1 SQL 方式读写数据
- 1.2.2 DataFrame 方式读写数据(batch)
- 1.2.3 RDD 方式读取数据
- 1.2.4 配置和字段类型映射
- 1.3 使用 JDBC 的方式(不推荐)
- 2、Flink Doris Connector
-
- 2.1、准备 Flink 环境
- 2.2 SQL 方式读写
- 2.3 DataStream 读写
-
- 2.3.1 Source
- 2.3.2 Sink
- 2.4 通用配置项和字段类型映射
- 3 DataX doriswriter
-
- 3.1 编译
- 3.2 使用
- 3.3 参数说明
- 4 ODBC 外部表
-
- 4.1 使用方式
- 4.2 使用 ODBC 的 MySQL 外表
- 4.3 使用ODBC的Oracle外表
- 5 Doris On ES
-
- 5.1 原理
- 5.2 使用方式
-
- 5.2.1 Doris 中创建 ES 外表
- 5.2.2 启用列式扫描优化查询速度
- 5.2.3 探测 keyword 类型字段
- 5.2.4 开启节点自动发现,
- 5.2.5 配置 https 访问模式
- 5.2.6 查询用法
- 5.3 最佳实践
-
- 5.3.1 时间类型字段使用建议
- 5.3.2 获取 ES 元数据字段_id
0、准备
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
insert into table1 values
(1,1,'jim',2),
(2,1,'grace',2),
(3,2,'tom',2),
(4,3,'bush',3),
(5,3,'helen',3);
1、Spark 读写 Doris
1.1 准备 Spark 环境
创建 maven 工程,编写 pom.xml 文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.atguigu.dorisgroupId>
<artifactId>spark-demoartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<scala.binary.version>2.12scala.binary.version>
<spark.version>3.0.0spark.version>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>sparkcore_${scala.binary.version}artifactId>
<scope>providedscope>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>sparksql_${scala.binary.version}artifactId>
<scope>providedscope>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>sparkhive_${scala.binary.version}artifactId>
<scope>providedscope>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>2.12.10version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.47version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.49version>
dependency>
<dependency>
<groupId>org.apache.dorisgroupId>
<artifactId>spark-doris-connector-3.1_2.12artifactId>
<version>1.0.1version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.1version>
<executions>
<execution>
<id>compile-scalaid>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
<execution>
<id>test-compile-scalaid>
<goals>
<goal>add-sourcegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.0.0version>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
<configuration>
<archive>
<manifest>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-withdependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
plugins>
build>
project>
1.2 使用 Spark Doris Connector
Spark Doris Connector 可以支持通过 Spark 读取 Doris 中存储的数据,也支持通过
Spark 写入数据到 Doris。
1.2.1 SQL 方式读写数据
package com.atuigu.doris.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* TODO
*
* @version 1.0
* @author cjp
*/
object SQLDemo {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("SQLDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
sparkSession.sql(
"""
|CREATE TEMPORARY VIEW spark_doris
|USING doris
|OPTIONS(
| "table.identifier"="test_db.table1",
| "fenodes"="hadoop1:8030",
| "user"="test",
| "password"="test"
|);
""".stripMargin)
//读取数据
// sparkSession.sql("select * from spark_doris").show()
//写入数据
sparkSession.sql("insert into spark_doris
values(99,99,'haha',5)")
}
}
1.2.2 DataFrame 方式读写数据(batch)
package com.atuigu.doris.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* TODO
*
* @version 1.0
* @author cjp
*/
object DataFrameDemo {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("DataFrameDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
// 读取数据
// val dorisSparkDF = sparkSession.read.format("doris")
// .option("doris.table.identifier", "test_db.table1")
// .option("doris.fenodes", "hadoop1:8030")
// .option("user", "test")
// .option("password", "test")
// .load()
// dorisSparkDF.show()
// 写入数据
import sparkSession.implicits._
val mockDataDF = List(
(11,23, "haha", 8),
(11, 3, "hehe", 9),
(11, 3, "heihei", 10)
).toDF("siteid", "citycode", "username","pv")
mockDataDF.show(5)
mockDataDF.write.format("doris")
.option("doris.table.identifier", "test_db.table1")
.option("doris.fenodes", "hadoop1:8030")
.option("user", "test")
.option("password", "test")
//指定你要写入的字段
// .option("doris.write.fields", "user")
.save()
}
}
1.2.3 RDD 方式读取数据
package com.atuigu.doris.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
/**
* TODO
*
* @version 1.0
* @author cjp
*/
object RDDDemo {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("RDDDemo")
.setMaster("local[*]") //TODO 要打包提交集群执行,注释掉
val sc = new SparkContext(sparkConf)
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("test_db.table1"),
cfg = Some(Map(
"doris.fenodes" -> "hadoop1:8030",
"doris.request.auth.user" -> "test",
"doris.request.auth.password" -> "test"
))
)
dorisSparkRDD.collect().foreach(println)
}
}
1.2.4 配置和字段类型映射
1)通用配置项
| Key | Default Value | Comment |
|---|---|---|
| doris.fenodes | – | Doris FE http 地址,支持多个地址,使用逗号分隔 |
| doris.table.identifier | – | Doris 表名,如:db1.tbl1 |
| doris.request.retries | 3 | 向 Doris 发送请求的重试次数 |
| doris.request.connect.timeout.ms | 30000 | 向 Doris 发送请求的连接超时时间 |
| doris.request.read.timeout.ms | 30000 | 向 Doris 发送请求的读取超时时间 |
| doris.request.query.timeout.s | 3600 | 查询 doris 的超时时间,默认值为 1 小时,-1 表示无超时限制 |
| doris.request.tablet.size | Integer.MAX_VALUE | 一个 RDD Partition 对应的Doris Tablet 个数。此数值设置越小,则会生成越多的Partition。从而提升 Spark 侧的并行度,但同时会对 Doris造成更大的压力。 |
| doris.batch.size | 1024 | 一次从 BE 读取数据的最大行数。增大此数值可减少Spark 与 Doris 之间建立连接的次数。从而减轻网络延迟所带来的的额外时间开销。 |
| doris.exec.mem.limit | 2147483648 | 单个查询的内存限制。默认为 2GB,单位为字节 |
| doris.deserialize.arrow.async | false | 是否支持异步转换 Arrow 格式 到 spark-doris-connector迭代所需的 RowBatch |
| doris.deserialize.queue.size | 64 | 异步转换 Arrow 格式的内部处理队列,当doris.deserialize.arrow.async为 true 时生效 |
| doris.write.fields | – | 指定写入 Doris 表的字段或者字段顺序,多列之间使用逗号分隔。默认写入时要按照 Doris 表字段顺序写入全部字段。 |
| sink.batch.size | 10000 | 单次写 BE 的最大行数 |
| sink.max-retries | 1 | 写 BE 失败之后的重试次数 |
2)SQL 和 Dataframe 专有配置
| Key | Default Value | Comment |
|---|---|---|
| user | – | 访问 Doris 的用户名 |
| password | – | 访问 Doris 的密码 |
| doris.filter.query.in.max.count | 100 | 谓词下推中,in 表达式 value列表元素最大数量。超过此数量,则 in 表达式条件过滤在 Spark 侧处理。 |
3)RDD 专有配置
| Key | Default Value | Comment |
|---|---|---|
| doris.request.auth.user | – | 访问 Doris 的用户名 |
| doris.request.auth.password | – | 访问 Doris 的密码 |
| doris.read.field | – | 读取 Doris 表的列名列表,多列之间使用逗号分隔 |
| doris.filter.query | – | 过滤读取数据的表达式,此表达式透传给 Doris。Doris使用此表达式完成源端数据过滤 |
4)Doris 和 Spark 列类型映射关系:
| Doris Type | Spark Type |
|---|---|
| NULL_TYPE | DataTypes.NullType |
| BOOLEAN | DataTypes.BooleanType |
| TINYINT | DataTypes.ByteType |
| SMALLINT | DataTypes.ShortType |
| INT | DataTypes.IntegerType |
| BIGINT | DataTypes.LongType |
| FLOAT | DataTypes.FloatType |
| DOUBLE | DataTypes.DoubleType |
| DATE | DataTypes.StringType1 |
| DATETIME | DataTypes.StringType1 |
| BINARY | DataTypes.BinaryType |
| DECIMAL | DecimalType |
| CHAR | DataTypes.StringType |
| LARGEINT | DataTypes.StringType |
| VARCHAR | DataTypes.StringType |
| DECIMALV2 | DecimalType |
| TIME | DataTypes.DoubleType |
| HLL | Unsupported datatype |
注:Connector 中,将 DATE 和 DATETIME 映射为 String。由于 Doris 底层存储引擎处
理逻辑,直接使用时间类型时,覆盖的时间范围无法满足需求。所以使用 String 类型直接返回对应的时间可读文本。
1.3 使用 JDBC 的方式(不推荐)
这种方式是早期写法,Spark 无法感知 Doris 的数据分布,会导致打到 Doris 的查询压力
非常大。
package com.atuigu.doris.spark
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object JDBCDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new
SparkConf().setAppName("JDBCDemo").setMaster("local[*]")
val sparkSession =
SparkSession.builder().config(sparkConf).getOrCreate()
// 读取数据
// val df=sparkSession.read.format("jdbc")
// .option("url","jdbc:mysql://hadoop1:9030/test_db")
// .option("user","test")
// .option("password","test")
// .option("dbtable","table1")
// .load()
//
// df.show()
// 写入数据
import sparkSession.implicits._
val mockDataDF = List(
(11,23, "haha", 8),
(11, 3, "hehe", 9),
(11, 3, "heihei", 10)
).toDF("siteid", "citycode", "username","pv")
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
df.write.mode(SaveMode.Append)
.jdbc("jdbc:mysql://hadoop1:9030/test_db", "table1", prop)
}
}
2、Flink Doris Connector
Flink Doris Connector 可以支持通过 Flink 操作(读取、插入、修改、删除) Doris 中
存储的数据。
Flink Doris Connector Sink 的内部实现是通过 Stream load 服务向 Doris 写入数据, 同时
也支持 Stream load 请求参数的配置设定。
版本兼容如下:
| Connector | Flink | Doris | Java | Scala |
|---|---|---|---|---|
| 1.11.6-2.12-xx | 1.11.x | 0.13+ | 8 | 2.12 |
| 1.12.7-2.12-xx | 1.12.x | 0.13.+ | 8 | 2.12 |
| 1.13.5-2.12-xx | 1.13.x | 0.13.+ | 8 | 2.12 |
| 1.14.4-2.12-xx | 1.14.x | 0.13.+ | 8 | 2.12 |
2.1、准备 Flink 环境
创建 maven 工程,编写 pom.xml 文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.atguigu.dorisgroupId>
<artifactId>flink-demoartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
<flink.version>1.13.1flink.version>
<java.version>1.8java.version>
<scala.binary.version>2.12scala.binary.version>
<slf4j.version>1.7.30slf4j.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streamingjava_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flinkclients_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-plannerblink_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-runtimeweb_${scala.binary.version}artifactId>
<version>${flink.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>${slf4j.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>${slf4j.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.14.0version>
<scope>providedscope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.49version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackendrocksdb_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-sequence-fileartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>com.ververicagroupId>
<artifactId>flink-connector-mysql-cdcartifactId>
<version>2.0.0version>
dependency>
<dependency>
<groupId>org.apache.dorisgroupId>
<artifactId>flink-doris-connector-1.13_2.12artifactId>
<version>1.0.3version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>3.2.4version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305exclude>
<exclude>org.slf4j:*exclude>
<exclude>log4j:*exclude>
<exclude>org.apache.hadoop:*exclude>
excludes>
artifactSet>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesR
esourceTransformer">
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
2.2 SQL 方式读写
package com.atuigu.doris.flink;
import
org.apache.flink.streaming.api.environment.StreamExecutionEnviron
ment;
import
org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class SQLDemo {
public static void main(String[] args) {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv =
StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE flink_doris (\n" +
" siteid INT,\n" +
" citycode SMALLINT,\n" +
" username STRING,\n" +
" pv BIGINT\n" +
" ) \n" +
" WITH (\n" +
" 'connector' = 'doris',\n" +
" 'fenodes' = 'hadoop1:8030',\n" +
" 'table.identifier' = 'test_db.table1',\n" +
" 'username' = 'test',\n" +
" 'password' = 'test'\n" +
")\n");
// 读取数据
// tableEnv.executeSql("select * from flink_doris").print();
// 写入数据
tableEnv.executeSql("insert into
flink_doris(siteid,username,pv) values(22,'wuyanzu',3)");
}
}
2.3 DataStream 读写
2.3.1 Source
package com.atuigu.doris.flink;
import org.apache.doris.flink.cfg.DorisStreamOptions;
import org.apache.doris.flink.datastream.DorisSourceFunction;
import
org.apache.doris.flink.deserialization.SimpleListDeserializationS
chema;
import
org.apache.flink.streaming.api.environment.StreamExecutionEnviron
ment;
import
org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Properties;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class DataStreamSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("fenodes","hadoop1:8030");
properties.put("username","test");
properties.put("password","test");
properties.put("table.identifier","test_db.table1");
env.addSource(new DorisSourceFunction(
new DorisStreamOptions(properties),
new SimpleListDeserializationSchema()
)
).print();
env.execute();
}
}
2.3.2 Sink
1)Json 数据流写法一
package com.atuigu.doris.flink;
import org.apache.doris.flink.cfg.*;
import org.apache.doris.flink.datastream.DorisSourceFunction;
import
org.apache.doris.flink.deserialization.SimpleListDeserializationS
chema;
import
org.apache.flink.streaming.api.environment.StreamExecutionEnviron
ment;
import java.util.Properties;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class DataStreamJsonSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties pro = new Properties();
pro.setProperty("format", "json");
pro.setProperty("strip_outer_array", "true");
env
.fromElements(
"{\"longitude\": \"116.405419\", \"city\": \"
北京\", \"latitude\": \"39.916927\"}"
)
.addSink(
DorisSink.sink(
DorisReadOptions.builder().build(),
DorisExecutionOptions.builder()
.setBatchSize(3)
.setBatchIntervalMs(0L)
.setMaxRetries(3)
.setStreamLoadProp(pro).build(),
DorisOptions.builder()
.setFenodes("FE_IP:8030")
.setTableIdentifier("db.table")
.setUsername("root")
.setPassword("").build()
));
// .addSink(
// DorisSink.sink(
// DorisOptions.builder()
// .setFenodes("FE_IP:8030")
// .setTableIdentifier("db.table")
// .setUsername("root")
// .setPassword("").build()
// ));
env.execute();
}
}
2)RowData 数据流
package com.atuigu.doris.flink;
import org.apache.doris.flink.cfg.DorisExecutionOptions;
import org.apache.doris.flink.cfg.DorisOptions;
import org.apache.doris.flink.cfg.DorisReadOptions;
import org.apache.doris.flink.cfg.DorisSink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import
org.apache.flink.streaming.api.environment.StreamExecutionEnviron
ment;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.flink.table.types.logical.*;
/**
* TODO
*
* @author cjp
* @version 1.0
*/
public class DataStreamRowDataSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<RowData> source = env.fromElements("")
.map(new MapFunction<String, RowData>() {
@Override
public RowData map(String value) throws Exception
{
GenericRowData genericRowData = new
GenericRowData(4);
genericRowData.setField(0, 33);
genericRowData.setField(1, new Short("3"));
genericRowData.setField(2,
StringData.fromString("flink-stream"));
genericRowData.setField(3, 3L);
return genericRowData;
}
});
LogicalType[] types = {new IntType(), new SmallIntType(),
new VarCharType(32), new BigIntType()};
String[] fields = {"siteid", "citycode", "username", "pv"};
source.addSink(
DorisSink.sink(
fields,
types,
DorisReadOptions.builder().build(),
DorisExecutionOptions.builder()
.setBatchSize(3)
.setBatchIntervalMs(0L)
.setMaxRetries(3)
.build(),
DorisOptions.builder()
.setFenodes("hadoop1:8030")
.setTableIdentifier("test_db.table1")
.setUsername("test")
.setPassword("test").build()
));
env.execute();
}
}
2.4 通用配置项和字段类型映射
1)通用配置项:
| Key | Default Value | Comment |
|---|---|---|
| fenodes | – | Doris FE http 地址 |
| table.identifier | – | Doris 表名,如:db1.tbl1 |
| username | – | 访问 Doris 的用户名 |
| password | – | 访问 Doris 的密码 |
| doris.request.retries | 3 | 向 Doris 发送请求的重试次数 |
| doris.request.connect.timeout.ms | 30000 | 向 Doris 发送请求的连接超时时间 |
| doris.request.read.timeout.ms | 30000 | 向 Doris 发送请求的读取超时时间 |
| doris.request.query.timeout.s | 3600 | 查询 doris 的超时时间,默认值为 1 小时,-1 表示无超时限制 |
| doris.request.tablet.size | Integer. MAX_VALUE | 一个 Partition 对应的 Doris Tablet 个数。此数值设置越小,则会生成越多的 Partition。从而提升 Flink 侧的并行度,但同时会对Doris 造成更大的压力。 |
| doris.batch.size | 1024 | 一次从 BE 读取数据的最大行数。增大此数值可减少 flink 与 Doris 之间建立连接的次数。从而减轻网络延迟所带来的的额外时间开销。 |
| doris.exec.mem.limit | 2147483648 | 单个查询的内存限制。默认为 2GB,单位为字节 |
| doris.deserialize.arrow.async | false | 是否支持异步转换 Arrow 格式到 flink-dorisconnector 迭代所需的 RowBatch |
| doris.deserialize.queue.size | 64 | 异步转换 Arrow 格式的内部处理队列,当doris.deserialize.arrow.async 为 true 时生效 |
| doris.read.field | – | 读取 Doris 表的列名列表,多列之间使用逗号分隔 |
| doris.filter.query | – | 过滤读取数据的表达式,此表达式透传给Doris。Doris 使用此表达式完成源端数据过滤。 |
| sink.batch.size | 10000 | 单次写 BE 的最大行数 |
| sink.max-retries | 1 | 写 BE 失败之后的重试次数 |
| sink.batch.interval | 10s | flush 间隔时间,超过该时间后异步线程将缓存中数据写入 BE。 默认值为 10 秒,支持时间单位 ms、s、min、h 和 d。设置为 0表示关闭定期写入。 |
| sink.properties.* | – | Stream load 的导入参数例如’sink.properties.column_separator’ = ‘, ‘定义列分隔符’sink.properties.escape_delimiters’ = ‘true’特殊字符作为分隔符,’\x01’会被转换为二进制的 0x01’sink.properties.format’ = ‘json’‘sink.properties.strip_outer_array’ = 'true’JSON 格式导入 |
| sink.enable-delete | true | 是否启用删除。此选项需要 Doris 表开启批量删除功能(0.15+版本默认开启),只支持Uniq 模型。 |
| sink.batch.bytes | 10485760 | 单次写 BE 的最大数据量,当每个 batch 中记录的数据量超过该阈值时,会将缓存数据写入 BE。默认值为 10MB |
2)Doris 和 Flink 列类型映射关系:
| Doris Type | Flink Type |
|---|---|
| NULL_TYPE | NULL |
| BOOLEAN | BOOLEAN |
| TINYINT | TINYINT |
| SMALLINT | SMALLINT |
| INT | INT |
| BIGINT | BIGINT |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| DATE | STRING |
| DATETIME | STRING |
| DECIMAL | DECIMAL |
| CHAR | STRING |
| LARGEINT | STRING |
| VARCHAR | STRING |
| DECIMALV2 | DECIMAL |
| TIME | DOUBLE |
| HLL | Unsupported datatype |
3 DataX doriswriter
DorisWriter 支持将大批量数据写入 Doris 中。DorisWriter 通过 Doris 原生支持 Stream
load 方式导入数据, DorisWriter 会将 reader 读取的数据进行缓存在内存中,拼接成 Json 文本,然后批量导入至 Doris。
3.1 编译
可以自己编译,也可以直接使用我们编译好的包。
1)进入之前的容器环境
docker run -it \
-v /opt/software/.m2:/root/.m2 \
-v /opt/software/apache-doris-0.15.0-incubating-src/:/root/apachedoris-0.15.0-incubating-src/ \
apache/incubator-doris:build-env-for-0.15.0
2)运行 init-env.sh
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX
sh init-env.sh
3)手动上传依赖
上传 alibaba-datax-maven-m2-20210928.tar.gz,解压:
tar -zxvf alibaba-datax-maven-m2-20210928.tar.gz -C /opt/software
拷贝解压后的文件到 maven 仓库
sudo cp -r /opt/software/alibaba/datax/
/opt/software/.m2/repository/com/alibaba/
4)编译 doriswriter:
(1)单独编译 doriswriter 插件:
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX/DataX
mvn clean install -pl plugin-rdbms-util,doriswriter -DskipTests
(2)编译整个 DataX 项目:
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX/DataX
mvn package assembly:assembly -Dmaven.test.skip=true
产出在 target/datax/datax/.
hdfsreader, hdfswriter and oscarwriter 这三个插件需要额外的 jar 包。如果你并不需要这
些插件,可以在 DataX/pom.xml 中删除这些插件的模块。
5)拷贝编译好的插件到 DataX
Sudo cp -r /opt/software/apache-doris-0.15.0-incubating-src/extension/DataX/doriswriter/target/datax/plugin/writer/dorisw
riter /opt/module/datax/plugin/writer
3.2 使用
1)准备测试表
MySQL 建表、插入测试数据
CREATE TABLE `sensor` (
`id` varchar(255) NOT NULL,
`ts` bigint(255) DEFAULT NULL,
`vc` int(255) DEFAULT NULL,
PRIMARY KEY (`id`)
)
insert into sensor values('s_2',3,3),('s_9',9,9);
Doris 建表
CREATE TABLE `sensor` (
`id` varchar(255) NOT NULL,
`ts` bigint(255) DEFAULT NULL,
`vc` int(255) DEFAULT NULL
)
DISTRIBUTED BY HASH(`id`) BUCKETS 10;
2)编写 json 文件
vim mysql2doris.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"ts",
"vc"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop1:3306/test"
],
"table": [
"sensor"
]
}
],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"feLoadUrl": ["hadoop1:8030", "hadoop2:8030",
"hadoop3:8030"],
"beLoadUrl": ["hadoop1:8040", "hadoop2:8040",
"hadoop3:8040"],
"jdbcUrl": "jdbc:mysql://hadoop1:9030/",
"database": "test_db",
"table": "sensor",
"column": ["id", "ts", "vc"],
"username": "test",
"password": "test",
"postSql": [],
"preSql": [],
"loadProps": {
},
"maxBatchRows" : 500000,
"maxBatchByteSize" : 104857600,
"labelPrefix": "my_prefix",
"lineDelimiter": "\n"
}
}
}
]
}
}
3)运行 datax 任务
bin/datax.py job/mysql2doris.json
3.3 参数说明
⚫ jdbcUrl
描述:Doris 的 JDBC 连接串,用户执行 preSql 或 postSQL。
必选:是
默认值:无
⚫ feLoadUrl
描述:和 beLoadUrl 二选一。作为 Stream Load 的连接目标。格式为 “ip:port”。其中
IP 是 FE 节点 IP,port 是 FE 节点的 http_port。可以填写多个,doriswriter 将以轮询的方式访问。
必选:否
默认值:无
⚫ beLoadUrl
描述:和 feLoadUrl 二选一。作为 Stream Load 的连接目标。格式为 “ip:port”。其中 IP
是 BE 节点 IP,port 是 BE 节点的 webserver_port。可以填写多个,doriswriter 将以轮询的方式访问。
必选:否
默认值:无
⚫ username
描述:访问 Doris 数据库的用户名
必选:是
默认值:无
⚫ password
描述:访问 Doris 数据库的密码
必选:否
默认值:空
⚫ database
描述:需要写入的 Doris 数据库名称。
必选:是
默认值:无
⚫ table
描述:需要写入的 Doris 表名称。
必选:是
默认值:无
⚫ column
描述:目的表需要写入数据的字段,这些字段将作为生成的 Json 数据的字段名。字段之间用英文逗号分隔。例如: “column”: [“id”,“name”,“age”]。
必选:是
默认值:否
⚫ preSql
描述:写入数据到目的表前,会先执行这里的标准语句。
必选:否
默认值:无
⚫ postSql
描述:写入数据到目的表后,会执行这里的标准语句。
必选:否
默认值:无
⚫ maxBatchRows
描述:每批次导入数据的最大行数。和 maxBatchByteSize 共同控制每批次的导入数量。
每批次数据达到两个阈值之一,即开始导入这一批次的数据。
必选:否
默认值:500000
⚫ maxBatchByteSize
描述:每批次导入数据的最大数据量。和 ** maxBatchRows** 共同控制每批次的导入
数量。每批次数据达到两个阈值之一,即开始导入这一批次的数据。
必选:否
默认值:104857600
⚫ labelPrefix
描述:每批次导入任务的 label 前缀。最终的 label 将有 labelPrefix + UUID + 序号 组
成
必选:否
默认值:datax_doris_writer_
⚫ lineDelimiter
描述:每批次数据包含多行,每行为 Json 格式,每行的的分隔符即为 lineDelimiter。
支持多个字节, 例如’\x02\x03’。
必选:否
默认值:\n
⚫ loadProps
描述:StreamLoad 的请求参数,详情参照 StreamLoad 介绍页面。
必选:否
默认值:无
⚫ connectTimeout
描述:StreamLoad 单次请求的超时时间, 单位毫秒(ms)。
必选:否
默认值:-1
4 ODBC 外部表
ODBC External Table Of Doris 提供了 Doris 通过数据库访问的标准接口(ODBC)来访问
外部表,外部表省去了繁琐的数据导入工作,让 Doris 可以具有了访问各式数据库的能力,并借助 Doris 本身的 OLAP 的能力来解决外部表的数据分析问题:
(1)支持各种数据源接入 Doris
(2)支持 Doris 与各种数据源中的表联合查询,进行更加复杂的分析操作
(3)通过 insert into 将 Doris 执行的查询结果写入外部的数据源
4.1 使用方式
1)Doris 中创建 ODBC 的外表
方式一:不使用 Resource 创建 ODBC 的外表。
CREATE EXTERNAL TABLE `baseall_oracle` (
`k1` decimal(9, 3) NOT NULL COMMENT "",
`k2` char(10) NOT NULL COMMENT "",
`k3` datetime NOT NULL COMMENT "",
`k5` varchar(20) NOT NULL COMMENT "",
`k6` double NOT NULL COMMENT ""
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"host" = "192.168.0.1",
"port" = "8086",
"user" = "test",
"password" = "test",
"database" = "test",
"table" = "baseall",
"driver" = "Oracle 19 ODBC driver",
"odbc_type" = "oracle"
);
方式二:通过 ODBC_Resource 来创建 ODBC 外表(推荐使用的方式)。
CREATE EXTERNAL RESOURCE `oracle_odbc`
PROPERTIES (
"type" = "odbc_catalog",
"host" = "192.168.0.1",
"port" = "8086",
"user" = "test",
"password" = "test",
"database" = "test",
"odbc_type" = "oracle",
"driver" = "Oracle 19 ODBC driver"
);
CREATE EXTERNAL TABLE `baseall_oracle` (
`k1` decimal(9, 3) NOT NULL COMMENT "",
`k2` char(10) NOT NULL COMMENT "",
`k3` datetime NOT NULL COMMENT "",
`k5` varchar(20) NOT NULL COMMENT "",
`k6` double NOT NULL COMMENT ""
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"odbc_catalog_resource" = "oracle_odbc",
"database" = "test",
"table" = "baseall"
);
参数说明:
| 参数 | 说明 |
|---|---|
| hosts | 外表数据库的 IP 地址 |
| driver | ODBC 外表 Driver 名,需要和 be/conf/odbcinst.ini 中的 Driver 名一致。 |
| odbc_type | 外表数据库的类型,当前支持 oracle, mysql, postgresql |
| user | 外表数据库的用户名 |
| password | 对应用户的密码信息 |
2)ODBC Driver 的安装和配置
各大主流数据库都会提供 ODBC 的访问 Driver,用户可以执行参照各数据库官方推荐
的方式安装对应的 ODBC Driver LiB 库。
安装完成之后,查找对应的数据库的 Driver Lib 库的路径,并且修改 be/conf/odbcinst.ini
的配置:
[MySQL Driver]
Description = ODBC for MySQL
Driver = /usr/lib64/libmyodbc8w.so
FileUsage = 1
上述配置[]里的对应的是 Driver 名,在建立外部表时需要保持外部表的 Driver 名和配置
文件之中的一致。
Driver= 这个要根据实际 BE 安装 Driver 的路径来填写,本质上就是一个动态库的路径,
这里需要保证该动态库的前置依赖都被满足。
切记,这里要求所有的 BE 节点都安装上相同的 Driver,并且安装路径相同,同时有相
同的 be/conf/odbcinst.ini 的配置
4.2 使用 ODBC 的 MySQL 外表
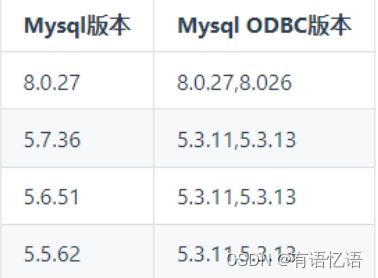
CentOS 数据库 ODBC 版本对应关系:
MySQL 与 Doris 的数据类型匹配:

1)安装 unixODBC
安装
yum install -y unixODBC unixODBC-devel libtool-ltdl libtool-ltdl-devel
查看是否安装成功
odbcinst -j
2)安装 MySQL 对应版本的 ODBC(每个 BE 节点都要)
下载
wget https://downloads.mysql.com/archives/get/p/10/file/mysqlconnector-odbc-5.3.11-1.el7.x86_64.rpm
安装
yum install -y mysql-connector-odbc-5.3.11-1.el7.x86_64.rpm
查看是否安装成功
myodbc-installer -d -l
3)配置 unixODBC,验证通过 ODBC 访问 Mysql
编辑 ODBC 配置文件
vim /etc/odbc.ini
[mysql]
Description = Data source MySQL
Driver = MySQL ODBC 5.3 Unicode Driver
Server = hadoop1
Host = hadoop1
Database = test
Port = 3306
User = root
Password = 000000
测试链接
isql -v mysql
4)准备 MySQL 表
CREATE TABLE `test_cdc` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=91234 DEFAULT CHARSET=utf8mb4;
INSERT INTO `test_cdc` VALUES (123, 'this is a update');
INSERT INTO `test_cdc` VALUES (1212, '测试 flink CDC');
INSERT INTO `test_cdc` VALUES (1234, '这是测试');
INSERT INTO `test_cdc` VALUES (11233, 'zhangfeng_1');
INSERT INTO `test_cdc` VALUES (21233, 'zhangfeng_2');
INSERT INTO `test_cdc` VALUES (31233, 'zhangfeng_3');
INSERT INTO `test_cdc` VALUES (41233, 'zhangfeng_4');
INSERT INTO `test_cdc` VALUES (51233, 'zhangfeng_5');
INSERT INTO `test_cdc` VALUES (61233, 'zhangfeng_6');
INSERT INTO `test_cdc` VALUES (71233, 'zhangfeng_7');
INSERT INTO `test_cdc` VALUES (81233, 'zhangfeng_8');
INSERT INTO `test_cdc` VALUES (91233, 'zhangfeng_9');
5)修改 Doris 的配置文件(每个 BE 节点都要,不用重启 BE)
在 BE 节点的 conf/odbcinst.ini,添加我们的刚才注册的的 ODBC 驱动([MySQL ODBC
5.3.11]这部分)。
# Driver from the postgresql-odbc package
# Setup from the unixODBC package
[PostgreSQL]
Description = ODBC for PostgreSQL
Driver = /usr/lib/psqlodbc.so
Setup = /usr/lib/libodbcpsqlS.so
FileUsage = 1
# Driver from the mysql-connector-odbc package
# Setup from the unixODBC package
[MySQL ODBC 5.3.11]
Description = ODBC for MySQL
Driver= /usr/lib64/libmyodbc5w.so
FileUsage = 1
# Driver from the oracle-connector-odbc package
# Setup from the unixODBC package
[Oracle 19 ODBC driver]
Description=Oracle ODBC driver for Oracle 19
Driver=/usr/lib/libsqora.so.19.1
6)Doris 建 Resource
通过 ODBC_Resource 来创建 ODBC 外表,这是推荐的方式,这样 resource 可以复用。
CREATE EXTERNAL RESOURCE `mysql_5_3_11`
PROPERTIES (
"host" = "hadoop1",
"port" = "3306",
"user" = "root",
"password" = "000000",
"database" = "test",
"table" = "test_cdc",
"driver" = "MySQL ODBC 5.3.11", --名称要和上面[]里的名称一致
"odbc_type" = "mysql",
"type" = "odbc_catalog")
7)基于 Resource 创建 Doris 外表
CREATE EXTERNAL TABLE `test_odbc_5_3_11` (
`id` int NOT NULL ,
`name` varchar(255) null
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"odbc_catalog_resource" = "mysql_5_3_11", --名称就是 resource 的名称
"database" = "test",
"table" = "test_cdc"
);
8)查询 Doris 外表
select * from `test_odbc_5_3_11`;
4.3 使用ODBC的Oracle外表
CentOS 数据库 ODBC 版本对应关系:

与 Doris 的数据类型匹配:

1)安装 unixODBC
安装
yum install -y unixODBC unixODBC-devel libtool-ltdl libtool-ltdldevel
查看是否安装成功
odbcinst -j
2)安装 Oracle 对应版本的 ODBC(每个 BE 节点都要)
下载 4 个安装包
wget
https://download.oracle.com/otn_software/linux/instantclient/1913
000/oracle-instantclient19.13-sqlplus-19.13.0.0.0-2.x86_64.rpm
wget
https://download.oracle.com/otn_software/linux/instantclient/1913
000/oracle-instantclient19.13-devel-19.13.0.0.0-2.x86_64.rpm
wget
https://download.oracle.com/otn_software/linux/instantclient/1913
000/oracle-instantclient19.13-odbc-19.13.0.0.0-2.x86_64.rpm
wget
https://download.oracle.com/otn_software/linux/instantclient/1913
000/oracle-instantclient19.13-basic-19.13.0.0.0-2.x86_64.rpm
安装 4 个安装包
rpm -ivh oracle-instantclient19.13-basic-19.13.0.0.0-2.x86_64.rpm
rpm -ivh oracle-instantclient19.13-devel-19.13.0.0.0-2.x86_64.rpm
rpm -ivh oracle-instantclient19.13-odbc-19.13.0.0.0-2.x86_64.rpm
rpm -ivh oracle-instantclient19.13-sqlplus-19.13.0.0.0-
2.x86_64.rpm
3)验证 ODBC 驱动动态链接库是否正确
ldd /usr/lib/oracle/19.13/client64/lib/libsqora.so.19.1
4)配置 unixODBC,验证通过 ODBC 连接 Oracle
vim /etc/odbcinst.ini
添加如下内容:
[Oracle 19 ODBC driver]
Description = Oracle ODBC driver for Oracle 19
Driver =
/usr/lib/oracle/19.13/client64/lib/libsqora.so.19.1
vim /etc/odbc.ini
添加如下内容:
[oracle]
Driver = Oracle 19 ODBC driver ---名称是上面 oracle 部分用[]括起来的内容
ServerName =hadoop2:1521/orcl --oracle 数据 ip 地址,端口及 SID
UserID = atguigu
Password = 000000
验证
isql oracle
5)修改 Doris 的配置(每个 BE 节点都要,不用重启)
修改 BE 节点 conf/odbcinst.ini 文件,加入刚才/etc/odbcinst.ini 添加的一样内容,并删除原先的 Oracle 配置。
[Oracle 19 ODBC driver]
Description = Oracle ODBC driver for Oracle 19
Driver =
/usr/lib/oracle/19.13/client64/lib/libsqora.so.19.1
6)创建 Resource
CREATE EXTERNAL RESOURCE `oracle_19`
PROPERTIES (
"host" = "hadoop2",
"port" = "1521",
"user" = "atguigu",
"password" = "000000",
"database" = "orcl", --数据库示例名称,也就是 ORACLE_SID
"driver" = "Oracle 19 ODBC driver", --名称一定和 be odbcinst.ini
里的 oracle 部分的[]里的内容一样
"odbc_type" = "oracle",
"type" = "odbc_catalog"
);
7)基于 Resource 创建 Doris 外表
CREATE EXTERNAL TABLE `oracle_odbc` (
id int,
name VARCHAR(20) NOT NULL
) ENGINE=ODBC
COMMENT "ODBC"
PROPERTIES (
"odbc_catalog_resource" = "oracle_19",
"database" = "orcl",
"table" = "student"
);
8)查询 Doris 外表
select * from oracle_odbc;
5 Doris On ES
Doris-On-ES 将 Doris 的分布式查询规划能力和 ES(Elasticsearch)的全文检索能力相结合,提供更完善的 OLAP 分析场景解决方案:
(1)ES 中的多 index 分布式 Join 查询
(2)Doris 和 ES 中的表联合查询,更复杂的全文检索过滤
5.1 原理

(1)创建 ES 外表后,FE 会请求建表指定的主机,获取所有节点的 HTTP 端口信息以
及 index 的 shard 分布信息等,如果请求失败会顺序遍历 host 列表直至成功或完全失败
(2)查询时会根据 FE 得到的一些节点信息和 index 的元数据信息,生成查询计划并发
给对应的 BE 节点
(3)BE 节点会根据就近原则即优先请求本地部署的 ES 节点,BE 通过 HTTP Scroll 方
式流式的从 ES index 的每个分片中并发的从_source 或 docvalue 中获取数据
(4)Doris 计算完结果后,返回给用户
5.2 使用方式
5.2.1 Doris 中创建 ES 外表
1)创建 ES 索引
PUT test
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"doc": { // ES 7.x 版本之后创建索引时不需要指定 type,会有一个默认且唯
一的`_doc` type
"properties": {
"k1": {
"type": "long"
},
"k2": {
"type": "date"
},
"k3": {
"type": "keyword"
},
"k4": {
"type": "text",
"analyzer": "standard"
},
"k5": {
"type": "float"
}
}
}
}
}
2)ES 索引导入数据
POST /_bulk
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Trying out Elasticsearch",
"k4": "Trying out Elasticsearch", "k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Trying out Doris", "k4":
"Trying out Doris", "k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Doris On ES", "k4": "Doris
On ES", "k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "Doris", "k4": "Doris",
"k5": 10.0}
{"index":{"_index":"test","_type":"doc"}}
{ "k1" : 100, "k2": "2020-01-01", "k3": "ES", "k4": "ES", "k5":
10.0}
3)Doris 中创建 ES 外表
CREATE EXTERNAL TABLE `es_test` (
`k1` bigint(20) COMMENT "",
`k2` datetime COMMENT "",
`k3` varchar(20) COMMENT "",
`k4` varchar(100) COMMENT "",
`k5` float COMMENT ""
) ENGINE=ELASTICSEARCH // ENGINE 必须是 Elasticsearch
PROPERTIES (
"hosts" =
"http://hadoop1:9200,http://hadoop2:9200,http://hadoop3:9200",
"index" = "test",
"type" = "doc",
"user" = "",
"password" = ""
);
参数说明:
| 参数 | 说明 |
|---|---|
| hosts | ES 集群地址,可以是一个或多个,也可以是 ES 前端的负载均衡地址 |
| index | 对应的 ES 的 index 名字,支持 alias,如果使用 doc_value,需要使用真实的名称 |
| type | index 的 type,不指定的情况会使用_doc |
| user | ES 集群用户名 |
| password | 对应用户的密码信息 |
➢ ES 7.x 之前的集群请注意在建表的时候选择正确的索引类型 type
➢ 认证方式目前仅支持 Http Basic 认证,并且需要确保该用户有访问: /_cluster/state/、
_nodes/http 等路径和 index 的读权限; 集群未开启安全认证,用户名和密码不需要
设置
➢ Doris 表中的列名需要和 ES 中的字段名完全匹配,字段类型应该保持一致
➢ ENGINE 必须是 Elasticsearch
Doris On ES 一个重要的功能就是过滤条件的下推: 过滤条件下推给 ES,这样只有真正
满足条件的数据才会被返回,能够显著的提高查询性能和降低 Doris 和 Elasticsearch 的 CPU、memory、IO 使用量
下面的操作符(Operators)会被优化成如下 ES Query:
| SQL syntax | ES 5.x+ syntax |
|---|---|
| = | term query |
| in | terms query |
, < , >= , ⇐ | range query
and | bool.filter
or | bool.should
not | bool.must_not
not in | bool.must_not + terms query
is_not_null | exists query
is_null | bool.must_not + exists query
esquery | ES 原生 json 形式的 QueryDSL
数据类型映射:

5.2.2 启用列式扫描优化查询速度
"enable_docvalue_scan" = "true"
1)参数说明
是否开启通过 ES/Lucene 列式存储获取查询字段的值,默认为 false。开启后 Doris 从 ES中获取数据会遵循以下两个原则:
(1)尽力而为: 自动探测要读取的字段是否开启列式存储(doc_value: true),如果获取的
字段全部有列存,Doris 会从列式存储中获取所有字段的值
(2)自动降级: 如果要获取的字段只要有一个字段没有列存,所有字段的值都会从行
存_source 中解析获取
2)优势:
默认情况下,Doris On ES 会从行存也就是_source 中获取所需的所有列,_source 的存
储采用的行式+json 的形式存储,在批量读取性能上要劣于列式存储,尤其在只需要少数列的情况下尤为明显,只获取少数列的情况下,docvalue 的性能大约是_source 性能的十几倍。
3)注意
text 类型的字段在 ES 中是没有列式存储,因此如果要获取的字段值有 text 类型字段会
自动降级为从_source 中获取.
在获取的字段数量过多的情况下(>= 25),从 docvalue中获取字段值的性能会和从_source中获取字段值基本一样。
5.2.3 探测 keyword 类型字段
"enable_keyword_sniff" = "true"
参数说明:
是否对 ES 中字符串类型分词类型(text) fields 进行探测,获取额外的未分词(keyword)字
段名(multi-fields 机制)
在 ES 中可以不建立 index 直接进行数据导入,这时候 ES 会自动创建一个新的索引,
针对字符串类型的字段 ES 会创建一个既有 text 类型的字段又有 keyword 类型的字段,这就是 ES 的 multi fields 特性,mapping 如下:
"k4": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
对 k4 进行条件过滤时比如=,Doris On ES 会将查询转换为 ES 的 TermQuery。
SQL 过滤条件:
k4 = "Doris On ES"
转换成 ES 的 query DSL 为:
"term" : {
"k4": "Doris On ES"
}
因为 k4 的第一字段类型为 text,在数据导入的时候就会根据 k4 设置的分词器(如果没
有设置,就是 standard 分词器)进行分词处理得到 doris、on、es 三个 Term,如下 ES analyze
API 分析:
POST /_analyze
{
"analyzer": "standard",
"text": "Doris On ES"
}
分词的结果是:
{
"tokens": [
{
"token": "doris",
"start_offset": 0,
"end_offset": 5,
"type": "" ,
"position": 0
},
{
"token": "on",
"start_offset": 6,
"end_offset": 8,
"type": "" ,
"position": 1
},
{
"token": "es",
"start_offset": 9,
"end_offset": 11,
"type": "" ,
"position": 2
}
]
}
查询时使用的是:
"term" : {
"k4": "Doris On ES"
}
Doris On ES 这个 term 匹配不到词典中的任何 term,不会返回任何结果,而启用
enable_keyword_sniff: true 会自动将 k4 = "Doris On ES"转换成 k4.keyword = "Doris On ES"来完全匹配 SQL 语义,转换后的 ES query DSL 为:
"term" : {
"k4.keyword": "Doris On ES"
}
k4.keyword 的类型是 keyword,数据写入 ES 中是一个完整的 term,所以可以匹配。
5.2.4 开启节点自动发现,
"nodes_discovery" = "true"
参数说明:
是否开启 es 节点发现,默认为 true。
当配置为 true 时,Doris 将从 ES 找到所有可用的相关数据节点(在上面分配的分片)。
如果 ES 数据节点的地址没有被 Doris BE 访问,则设置为 false。ES 集群部署在与公共 Internet隔离的内网,用户通过代理访问。
5.2.5 配置 https 访问模式
"http_ssl_enabled" = "true"
参数说明:
ES 集群是否开启 https 访问模式。
目前 fe/be 实现方式为信任所有,这是临时解决方案,后续会使用真实的用户配置证书。
5.2.6 查询用法
完成在 Doris 中建立 ES 外表后,除了无法使用 Doris 中的数据模型(rollup、预聚合、
物化视图等)外并无区别。
1)基本查询
select * from es_table where k1 > 1000 and k3 ='term' or k4 like
'fu*z_'
2)扩展的 esquery(field, QueryDSL)
通过 esquery(field, QueryDSL)函数将一些无法用 sql 表述的 query 如 match_phrase、geoshape 等下推给 ES 进行过滤处理,esquery 的第一个列名参数用于关联 index,第二个参数是 ES 的基本 Query DSL 的 json 表述,使用花括号{}包含,json 的 root key 有且只能有一个,如 match_phrase、geo_shape、bool 等。
(1)match_phrase 查询:
select * from es_table where esquery(k4, '{
"match_phrase": {
"k4": "doris on es"
}
}');
(2)geo 相关查询:
select * from es_table where esquery(k4, '{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
13,
53
],
[
14,
52
]
]
},
"relation": "within"
}
}
}');
(3)bool 查询:
select * from es_table where esquery(k4, ' {
"bool": {
"must": [
{
"terms": {
"k1": [
11,
12
]
}
},
{
"terms": {
"k2": [
100
]
}
}
]
}
}');
5.3 最佳实践
5.3.1 时间类型字段使用建议
在 ES 中,时间类型的字段使用十分灵活,但是在 Doris On ES 中如果对时间类型字段
的类型设置不当,则会造成过滤条件无法下推。
创建索引时对时间类型格式的设置做最大程度的格式兼容:
"dt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
在 Doris 中建立该字段时建议设置为 date 或 datetime,也可以设置为 varchar 类型, 使用
如下 SQL 语句都可以直接将过滤条件下推至 ES:
select * from doe where k2 > '2020-06-21';
select * from doe where k2 < '2020-06-21 12:00:00';
select * from doe where k2 < 1593497011;
select * from doe where k2 < now();
select * from doe where k2 < date_format(now(), '%Y-%m-%d');
注意:
(1)在 ES 中如果不对时间类型的字段设置 format, 默认的时间类型字段格式为
strict_date_optional_time||epoch_millis
(2)导入到 ES 的日期字段如果是时间戳需要转换成 ms, ES 内部处理时间戳都是按照
ms 进行处理的, 否则 Doris On ES 会出现显示错误。
5.3.2 获取 ES 元数据字段_id
导入文档在不指定_id 的情况下 ES 会给每个文档分配一个全局唯一的_id 即主键, 用户
也可以在导入时为文档指定一个含有特殊业务意义的_id; 如果需要在 Doris On ES 中获取该字段值,建表时可以增加类型为 varchar 的_id 字段:
CREATE EXTERNAL TABLE `doe` (
`_id` varchar COMMENT "",
`city` varchar COMMENT ""
) ENGINE=ELASTICSEARCH
PROPERTIES (
"hosts" = "http://127.0.0.1:8200",
"user" = "root",
"password" = "root",
"index" = "doe",
"type" = "doc"
}
注意:
(1)_id 字段的过滤条件仅支持=和 in 两种
(2)_id 字段只能是 varchar 类型