DeepMind 提出 Perceiver:使用RNN的方式进行注意力,通过交叉注意力节省计算量,附使用方法
今天要解读的论文来自 DeepMind ,论文名为《Perceiver: General Perception with Iterative Attention》,文中介绍了一种基于 Transformer 的结构,不对数据做任何假设,不需要修改网络结构,就可以利用于各种模态的数据。

我们人在感知世界的时候,是通过同时处理各个模态的高维数据,而现在深度学习中使用的方法,都会引入很多领域内的知识,比如现在几乎所有的视觉方法,都引入了”局部性“的假设,即在一张图像内,局部的特征是有用的,这也是 CNN 有用的基本原理。引入这些有帮助信息的同时,也将模型的作用范围限制在了某一个模态以内。
在这篇论文中,作者提出了 Perceiver,它是一个基于 Transformer 的模型,几乎没有做任何关于输入数据之间关系的结构性假设,但是也与 ConvNets 一样,可以扩展到数十万的输入上。
In this paper we introduce the Perceiver - a model that builds upon Transformers and hence makes few architectural assumptions about the relationship between its inputs, but that also scales to hundreds of thousands of inputs, like ConvNets.
作者提出的结构,达到甚至超过了精心设计用于某一个模态的模型的效果。在实验中,作者用了 ImageNet 的图像数据,AudioSet 的视频和音频数据,以及 3D 点云数据。

方法

使用了两个部分来构建网络:
- 使用交叉注意力机制(cross attention)来将一个输入向量(文中叫做 byte array)与一个隐向量映射为一个隐向量
- 使用 transformer 塔将一个隐向量映射为另一个同样大小的隐向量
输入向量的大小被输入数据所决定,这个一般会很大,例如一张 ImageNet 中的图像,有 224*224 维,也就是 50176 维。而隐向量是模型中的一个超参数,可以人为控制,这个一般很小,作者在 ImageNet 中使用了 1024 维。
所提方法的关键在于:通过一个低维的注意力瓶颈层,将输入的高维数据,映射到低维,再将它送入深度的 transformer 中。
这样做的好处是,如果仅直接使用 transformer 层,那么面临最大的问题是,训练太耗费时间,以及需要非常大的显存。作者在文中分析,transformer 的时间复杂度为序列长度的二次关系,即 O(M^2),这里 M 指序列长度。使用文中提出的交叉注意力机制,变成了 O(MN),而一般可以设置 N 远小于 M。
接下来是一些我的理解:
熟悉注意力机制的都知道,它包括三个部分,分别是Q、K和V。一般的作用方式是,序列长度是多少,那么Q、K 和 V的长度就是多少。但这一点其实是没有必要的。对于一张图,我们不需要每一个位置,都需要一个查询向量(Q)。这样就容易理解,作者提出的结构。对于长度为 M 的序列中的每一个元素,我们会有 N 个查询向量作用于它,所以时间复杂度就变为了 O(MN)。当有了这样 N 个结果以后,再送入传统的 Transformer 结构,这样就极大程度上减少了运算量和显存的占用。
迭代式的注意力机制
瓶颈层可能会限制网络捕捉必要信息的能力,为了缓解这个现象,Perceiver 使用多个 byte-attend 层,也就是交叉注意力层,当网络需要详细的输入信息时候,它就能够获得到这些信息。
最后,借助这样的迭代的注意力机制,可以将网络设计成权值共享的形式(最终的网络结构非常类似于RNN)。权值共享使得参数量减少约 10 倍,减少了网络的过拟合,提高了验证集上的性能。
实验部分
在 ImageNet 上的实验
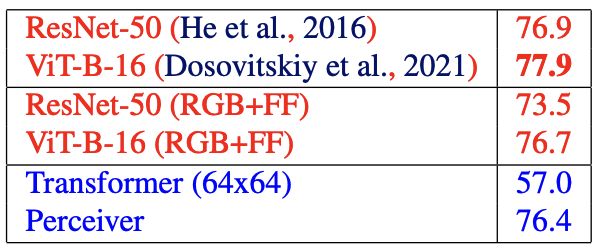
在 ImageNet 上的实验结果。红色的方法代表设计模型时引入了一些特定知识,蓝色的方法代表没有引入。可以看到 Perceiver 达到了非常有竞争力的效果。
将图像像素随机打乱

这里作者将图像中的像素随机打乱,Fixed 代表所有图像都是用同一个打乱的方式,Random 代表每张图都是随机打乱,可以看到,当进行随机打乱时,其余方法的性能大幅下降。
后面一列是每个模型输入单元的感受野。
这里可能会有一个问题,就是,既然我们知道图像中局部的信息是有用的,为什么不利用它呢?作者的考虑主要是,这样可以得到一个应用范围更广的模型,因为如果面临的是多模态任务,比如视频、音频、嗅觉传感器和触摸传感器等等数据,再去手动设计输入数据的交互形式是非常困难的。
注意力可视化
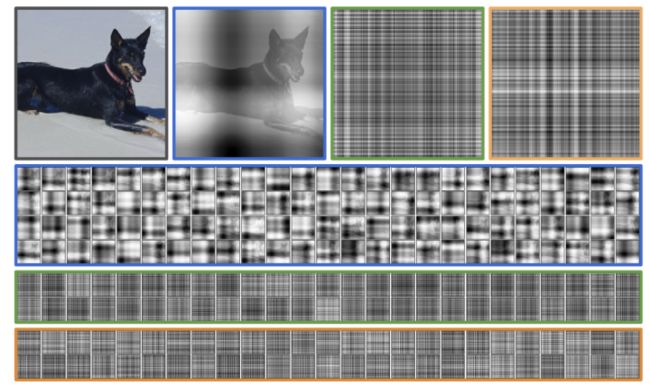
这里展示的是交叉注意力可视化的结果。
其中,蓝色代表是第一层网络的可视化结果,绿色代表第2-7层网络的结果,橙色代表第八层网络的可视化结果。第一行是每层抽了一个注意力图作为特写。
从图中可以看到,所提方法没有取局部的信息,而是以一种类似格网的形式扫描整张图。
视频音频的结果

使用了 AudioSet 数据集,单独使用视频或音频,或者两者结合使用,都达到了最好的结果。
点云数据
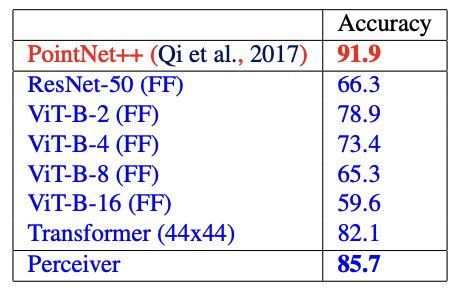
在点云数据的结果中,PointNet ++ 使用了额外的几何特征,以及更多的增强技术。蓝色的方法都没有使用这些技术。在蓝色的里面,效果是最好的。
使用方法
安装
pip install perceiver-pytorch
使用
import torch
from perceiver_pytorch import Perceiver
model = Perceiver(
input_channels = 3, # 序列中每一个元素的维度
input_axis = 2, # 输入数据的坐标数(用于构建位置编码,图像的话就是2:x和y)
num_freq_bands = 6, # number of freq bands, with original value (2 * K + 1)
max_freq = 10., # maximum frequency, hyperparameter depending on how fine the data is
depth = 6, # 网络深度
num_latents = 256, # 隐向量的个数
cross_dim = 512, # 交叉注意力的维度
latent_dim = 512, # 隐向量的维度
cross_heads = 1, # 交叉注意力的头数
latent_heads = 8, # 隐自注意力的头数
cross_dim_head = 64,
latent_dim_head = 64,
num_classes = 1000, # 最终输出类别数
attn_dropout = 0.,
ff_dropout = 0.,
)
img = torch.randn(1, 224, 224, 3) # imagenet 图像数据
model(img) # (1, 1000)
参考资料
- 论文链接:https://arxiv.org/pdf/2103.03206.pdf
- 代码:https://github.com/lucidrains/perceiver-pytorch(非官方实现)
推荐阅读:
- Chris:将注意力机制引入ResNet,视觉领域涨点技巧来了!附使用方法
- Chris:Facebook AI 提出 TimeSformer:完全基于 Transformer 的视频理解框架