Dataset and DataLoader 加载数据集
文章目录
-
- 7、Dataset and DataLoader 加载数据集
-
- 7.1 Revision
-
- 7.1.1 Manual data feed 手动数据输入
- 7.1.2 Epoch, Batch-Size, Iterations
- 7.2 DataLoader 数据加载器
- 7.3 Dataset 数据集
-
- 7.3.1 import
- 7.3.2 class
- 7.3.3 DataLoader
- 7.4 Example: Diabetes Dataset
-
- 7.4.1 Prepare dataset
- 7.4.2 Design model
- 7.4.3 Construct loss and optimizer
- 7.4.4 Training cycle
- 7.4.5 num_workers in Windows
- 7.4.6 代码
- 7.5 Datasets
-
- 7.5.1 MNIST Dataset
- 7.6 Kaggle Exercise
-
- 7.6.1 Prepare dataset
- 7.6.2 Design model
- 7.6.3 Construct loss and optimizer
- 7.6.4 Training cycle
- 7.6.5 Test and Output
- 7.6.6 完整代码
7、Dataset and DataLoader 加载数据集
B站视频教程传送门:PyTorch深度学习实践 - 加载数据集
7.1 Revision
我们就拿上节的糖尿病的例子来做个引入。
7.1.1 Manual data feed 手动数据输入
先回顾一下上一节的代码片段:
xy = np.loadtxt('../data/diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])
...
for epoch in range(100):
# Forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# Backward
optimizer.zero_grad()
loss.backward()
# Update
optimizer.step()
注意:在做前馈(Forward:model(x_data))时,是将所有数据全部送入模型中。在使用梯度下降有以下两种选择:
-
全部样本 Batch
- 可以最大化的利用向量计算的优势来提升计算速度。
- 性能上会有一点问题。
-
单个样本 随机梯度下降
-
会得到一个比较好的随机性,会跨越将来我们在优化当中遇到的鞍点,即克服鞍点问题,训练出的模型性能会较好。
-
会导致在优化过程中时间过长。
-
所以我们在深度学习中,会使用 Mini-Batch 的方法,来均衡我们在性能和训练时间上的需求。
7.1.2 Epoch, Batch-Size, Iterations

# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
嵌套循环:
- for:每一次循环是一个 epoch,即训练周期
- for:每一次迭代执行一次 Mini-Batch
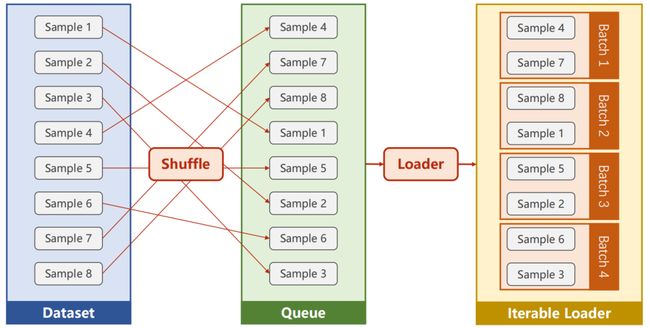
7.2 DataLoader 数据加载器
batch-size=2, shuffle=True
参数说明:
- batch_size:每2个为一组,即 I t e r a t i o n s = S a m p l e B a c t h − S i z e Iterations = \frac {Sample} {Bacth-Size} Iterations=Bacth−SizeSample
- shuffle:是否打乱顺序
7.3 Dataset 数据集
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
dataset = DiabetesDataset()
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
7.3.1 import
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
Dataset:抽象类,不能实例化,只能被其他子类继承
DataLoader:加载数据,可以实例化
7.3.2 class
class DiabetesDataset(Dataset):
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
(Dataset):表示该类(DiabetesDataset)继承自 Dataset
__getitem__:实例化类之后,该类支持下标操作,可以通过索引 dataset[index] 拿出数据
__len__:返回数据条数
7.3.3 DataLoader
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
num_workers:并行线程数
7.4 Example: Diabetes Dataset
# 导入需要的包
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
7.4.1 Prepare dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('../data/diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
7.4.2 Design model
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
7.4.3 Construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
7.4.4 Training cycle
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
7.4.5 num_workers in Windows
当我们在PyCharm执行上述代码时,会报出如下错误:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
在不同操作系统中,多进程的实现方式也不同,Linux 或 Mac OS 使用的是fork,而 Windows 则使用spawn。
所以我们需在training cycle前添加如下代码:
if __name__ == '__main__':
7.4.6 代码
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('../data/diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
epoch_list = []
loss_list = []
if __name__ == '__main__':
for epoch in range(100):
epoch_list.append(epoch)
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
loss_list.append(loss.item())
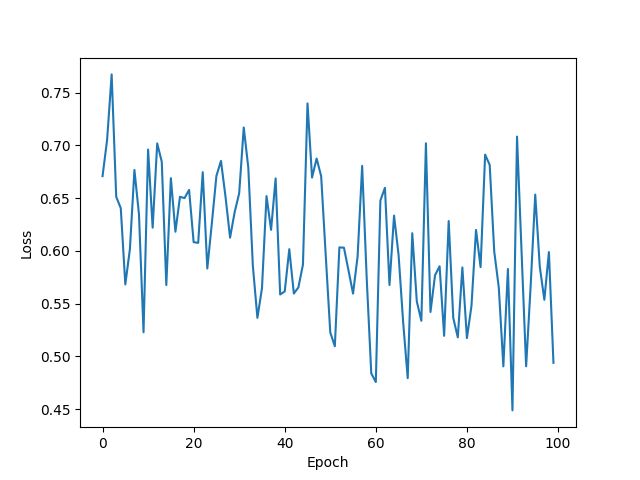
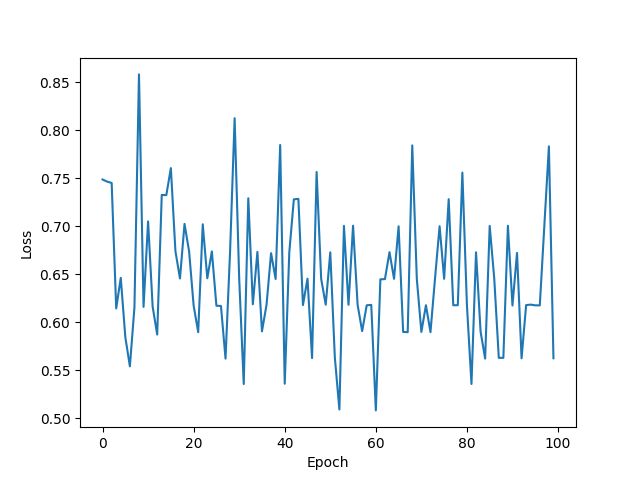
plt.plot(epoch_list, loss_list)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
训练次数:100
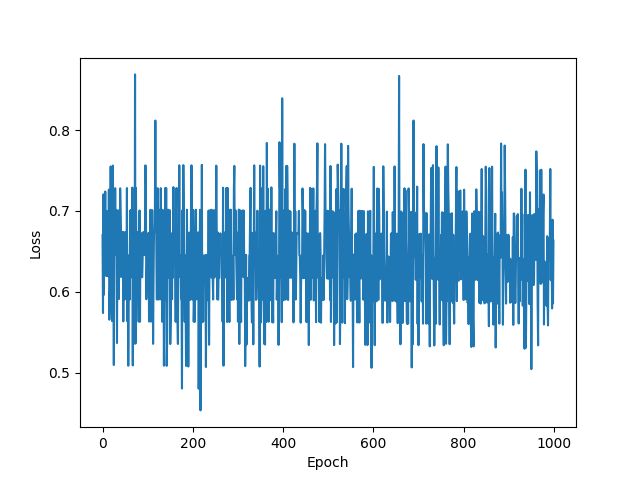
训练次数:1000
7.5 Datasets
The following dataset loaders are available:https://pytorch.org/vision/stable/datasets.html
All datasets are subclasses of torch.utils.data.Dataset i.e, they have __getitem__ and __len__ methods implemented. Hence, they can all be passed to a torch.utils.data.DataLoader which can load multiple samples in parallel using torch.multiprocessing workers. For example:
imagenet_data = torchvision.datasets.ImageNet('path/to/imagenet_root/')
data_loader = torch.utils.data.DataLoader(imagenet_data, batch_size=4, shuffle=True, num_workers=args.nThreads)
All the datasets have almost similar API. They all have two common arguments: transform and target_transform to transform the input and target respectively. You can also create your own datasets using the provided base classes.
7.5.1 MNIST Dataset
以下列 MNIST 数据集为例:

import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
train_dataset = datasets.MNIST(root='../dataset/mnist', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='../dataset/mnist', train=False, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=32, shuffle=False)
for batch_idx, (inputs, target) in enumerate(train_loader):
......
7.6 Kaggle Exercise
- 注册并登录 Kaggle
- 进入 Titanic 竞赛,下载
test.csv和train.csv

7.6.1 Prepare dataset
class TitanicDataset(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
self.len = xy.shape[0]
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature])))
self.y_data = torch.from_numpy(np.array(xy["Survived"]))
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = TitanicDataset('../data/train.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0)
7.6.2 Design model
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(6, 3)
self.linear2 = torch.nn.Linear(3, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
def test(self, x):
with torch.no_grad():
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
for i in x:
if i > 0.5:
y.append(1)
else:
y.append(0)
return y
model = Model()
7.6.3 Construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
7.6.4 Training cycle
if __name__ == '__main__':
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader, 0):
inputs = inputs.float()
labels = labels.float()
y_pred = model(inputs)
y_pred = y_pred.squeeze(-1)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
7.6.5 Test and Output
test_data = pd.read_csv('../data/test.csv')
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[feature])))
y = model.test(test.float())
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
output.to_csv('../data/my_predict.csv', index=False)
7.6.6 完整代码
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
class TitanicDataset(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
self.len = xy.shape[0] # xy.shape()可以得到xy的行列数
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"] # 选取相关的数据特征
# 要先进行独热表示,然后转化成ndarray,最后再转换成tensor矩阵
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature])))
self.y_data = torch.from_numpy(np.array(xy["Survived"]))
# 使用索引拿到数据
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 返回数据的条数/长度
def __len__(self):
return self.len
# 实例化自定义类,并传入数据地址
dataset = TitanicDataset('../data/train.csv')
# 采用Mini-Batch的训练方法
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0) # num_workers是否要进行多线程服务
# 定义模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(6, 3)
self.linear2 = torch.nn.Linear(3, 1)
self.sigmoid = torch.nn.Sigmoid()
# 前馈
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
# 测试
def test(self, x):
with torch.no_grad():
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
# 根据二分法原理,划分y的值
for i in x:
if i > 0.5:
y.append(1)
else:
y.append(0)
return y
# 实例化模型
model = Model()
# 定义损失函数
criterion = torch.nn.BCELoss(reduction='mean')
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 防止windows系统报错
if __name__ == '__main__':
loss_list = []
# 采用Mini-Batch的方法训练要采用多层嵌套循环
# 所有数据都跑100遍
for epoch in range(100):
# data从train_loader中取出数据(取出的是一个元组数据):(x,y)
# enumerate可以获得当前是第几次迭代,内部迭代每一次跑一个Mini-Batch
for i, (inputs, labels) in enumerate(train_loader, 0):
# inputs获取到data中的x的值,labels获取到data中的y值
inputs = inputs.float()
labels = labels.float()
y_pred = model(inputs)
y_pred = y_pred.squeeze(-1)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss.item())
plt.plot(range(100), loss_list)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
# 测试
test_data = pd.read_csv('../data/test.csv')
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[feature])))
y = model.test(test.float())
# 输出预测结果
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
output.to_csv('../data/my_predict.csv', index=False)
0 0 0.756897509098053
0 1 0.7051487565040588
0 2 0.6766899228096008
0 3 0.658218502998352
0 4 0.6307331919670105
0 5 0.7304965257644653
0 6 0.644881010055542
0 7 0.6831851601600647
0 8 0.8197712302207947
0 9 0.7180750966072083
0 10 0.7203354835510254
0 11 0.6558003425598145
0 12 0.6053438782691956
0 13 0.5872318744659424
0 14 0.7021993398666382
0 15 0.705322265625
0 16 0.8232700824737549
0 17 0.651711642742157
0 18 0.674558162689209
0 19 0.6497538685798645
0 20 0.6709573864936829
0 21 0.6553310751914978
0 22 0.6533945798873901
0 23 0.6815280318260193
0 24 0.6963645815849304
0 25 0.727899968624115
0 26 0.6275196075439453
0 27 0.6709432005882263
...
99 0 0.6080023050308228
99 1 0.4668632447719574
99 2 0.544707179069519
99 3 0.5396970510482788
99 4 0.616457462310791
99 5 0.536240816116333
99 6 0.5226209163665771
99 7 0.595719575881958
99 8 0.5522709488868713
99 9 0.5529608726501465
99 10 0.6031484603881836
99 11 0.6390214562416077
99 12 0.5860381126403809
99 13 0.5921188592910767
99 14 0.6553858518600464
99 15 0.4729886054992676
99 16 0.6547493934631348
99 17 0.5085688829421997
99 18 0.5744019746780396
99 19 0.5622053146362305
99 20 0.49595993757247925
99 21 0.4467465877532959
99 22 0.5766837000846863
99 23 0.6239879131317139
99 24 0.6590874195098877
99 25 0.6569676995277405
99 26 0.516386866569519
99 27 0.49393993616104126