总结:Prometheus之PromQL操作符
一、介绍
使用PromQL除了能够方便的按照查询和过滤时间序列以外,PromQL还支持丰富的操作符,这些操作符包括:数学运算符,逻辑运算符,布尔运算符等等。
二、数学运算
+(加法)-(减法)*(乘法)/(除法)%(求余)^(幂运算)
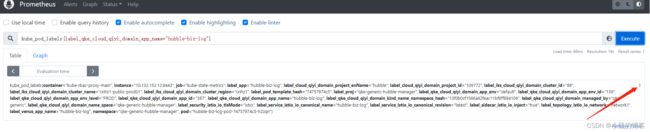
案例:如下PromQL使用了*,即乘法
sum by (label_qke_cloud_qiyi_domain_app_id, label_qke_cloud_qiyi_domain_app_name) (rate(http_server_requests_seconds_count{}[5m]) * on (pod) group_left(label_qke_cloud_qiyi_domain_app_id, label_qke_cloud_qiyi_domain_app_name) kube_pod_labels{label_qke_cloud_qiyi_domain_app_name=\"hubble-biz-log\"})
为啥使用*呢?
目的:让左边的计算结果不变。
因为kube_pod_labels{label_qke_cloud_qiyi_domain_app_name=\"hubble-biz-log\"}的结果值始终是1,任何数乘以1都是不变的
如果使用+,- 等,value值就会变化。但是改成 / 是可以的,效果是一样的,因为任何数除以1,还是不变
三、布尔运算
==(相等)!=(不相等)>(大于)<(小于)>=(大于等于)<=(小于等于)
四、集合运算符
使用瞬时向量表达式能够获取到一个包含多个时间序列的集合,我们称为瞬时向量。 通过集合运算,可以在两个瞬时向量与瞬时向量之间进行相应的集合操作。目前,Prometheus支持以下集合运算符:
and(并且)or(或者)unless(排除)
*vector1 and vector2* 会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配vector2中的元素组成。
*vector1 or vector2* 会产生一个新的向量,该向量包含vector1中所有的样本数据,以及vector2中没有与vector1匹配到的样本数据。
*vector1 unless vector2* 会产生一个新的向量,新向量中的元素由vector1中没有与vector2匹配的元素组成。
五、操作符优先级
对于复杂类型的表达式,需要了解运算操作的运行优先级
例如,查询主机的CPU使用率,可以使用表达式:
100 * (1 - avg (irate(node_cpu{mode='idle'}[5m])) by(job) )
其中irate是PromQL中的内置函数,用于计算区间向量中时间序列每秒的即时增长率。关于内置函数的部分,会在下一节详细介绍。
在PromQL操作符中优先级由高到低依次为:
^*, /, %+, -==, !=, <=, <, >=, >and, unlessor
六、匹配模式
向量与向量之间进行运算操作时会基于默认的匹配规则:依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行运算,如果没找到匹配元素,则直接丢弃。
接下来将介绍在PromQL中有两种典型的匹配模式:一对一(one-to-one),多对一(many-to-one)或一对多(one-to-many)。
一对一匹配
一对一匹配模式会从操作符两边表达式获取的瞬时向量依次比较并找到唯一匹配(标签完全一致)的样本值。默认情况下,使用表达式:
vector1 vector2
在操作符两边表达式标签不一致的情况下,可以使用on(label list)或者ignoring(label list)来修改便签的匹配行为。使用ignoreing可以在匹配时忽略某些便签。而on则用于将匹配行为限定在某些便签之内。
ignoring( 例如当存在样本:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21
method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
使用PromQL表达式:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
该表达式会返回在过去5分钟内,HTTP请求状态码为500的在所有请求中的比例。如果没有使用ignoring(code),操作符两边表达式返回的瞬时向量中将找不到任何一个标签完全相同的匹配项。
因此结果如下:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
同时由于method为put和del的样本找不到匹配项,因此不会出现在结果当中。
多对一和一对多
多对一和一对多两种匹配模式指的是“一”侧的每一个向量元素可以与"多"侧的多个元素匹配的情况。在这种情况下,必须使用group修饰符:group_left或者group_right来确定哪一个向量具有更高的基数(充当“多”的角色)。
ignoring( 多对一和一对多两种模式一定是出现在操作符两侧表达式返回的向量标签不一致的情况。因此需要使用ignoring和on修饰符来排除或者限定匹配的标签列表。
例如,使用表达式:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
该表达式中,左向量method_code:http_errors:rate5m包含两个标签method和code。而右向量method:http_requests:rate5m中只包含一个标签method,因此匹配时需要使用ignoring限定匹配的标签为code。 在限定匹配标签后,右向量中的元素可能匹配到多个左向量中的元素 因此该表达式的匹配模式为多对一,需要使用group修饰符group_left指定左向量具有更好的基数。
最终的运算结果如下:
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
提醒:group修饰符只能在比较和数学运算符中使用。在逻辑运算and,unless和or才注意操作中默认与右向量中的所有元素进行匹配。
参考:
Prometheus之PromQL-操作符 - 南风丶轻语 - 博客园