python人脸识别训练模型_opencv+mtcnn+facenet+python+tensorflow 实现实时人脸识别
opencv+mtcnn+facenet+python+tensorflow 实现实时人脸识别
Abstract:本文记录了在学习深度学习过程中,使用opencv+mtcnn+facenet+python+tensorflow,开发环境为ubuntu18.04,实现局域网连接手机摄像头,对目标人员进行实时人脸识别,效果并非特别好,会继续改进
这里是
如果各位老爷看完觉得对你有帮助的话,请给个小星星,3q
Instruction
当前时间距facenet论文发布已有三年,网上对于facenet的解读也有许多,但却也找不到什么能修修改改就能用的代码,所以本文就此而生,将会系统的介绍在CNN在图像识别方向-人脸识别,我会把我遇到的一切问题以及见解都陆续的补充在本文中,并会附上项目地址,保证各位官人看的开心。
所用工具简介
opencv很有名了,在本次项目中用到的当然是它的强大的图片处理能力了,大概就是读取、写入、连接手机摄像头一些了
mtcnn是一个用来检测图片中人脸位置(人脸检测)的深度学习模型,其使用了三个卷积网络实现了对图像中人脸的检测,在文章后面再具体的介绍其实现的细节
facenet是谷歌的一篇很有名的论文和开源项目,其实现了将输入的人像最终转换为shape为1*128的向量,然后通过计算不同照片之间的欧几里得距离来判断他们的相似度,当然其中还包含许多技巧以及创新的想法,最终的在lfw(一个很有名的人脸数据库)准确率达到99%+++,在文章的后面我会尽可能的解读其论文和代码中的有意思的想法
tensorflow应该很熟悉了(不然你是怎么搜到我的这篇文章的?) 学习深度学习的应该都知道存在各种各样的方便于搭建网络的框架,tensorflow就是其中很有名的一个,由google开源,功能强大
正式开始前的一些废话,防止看官老爷在后面麋鹿~
你肯定已经或多或许对机器学习或者是深度学习有些了解,所以你应该知道整个项目的过程无非就是
使用现有的几大框架搭建网络(当然不排除是使用matlab自己手动实现)
喂数据并且调参,最终得到心仪的模型
保存模型,部署模型使用
因为现在我还处于菜鸟阶段,有幸搭建过的几个网络无非是吴恩达老师课程中的几个浅层网络,实现了一些非主流功能,还有的就是google官方的一些教学例子,总之都是些帮助巩固知识,但是没什么luan用的,如果想要作出比较吊的东西还是需要使用大公司和大神开源的一些模型,“嫁接”过来,改改,又不能不能用......真香
github上开源的一些项目以及一些大公司开源的项目,其项目文件一般包含 网络的搭建 网络的测试等文件,其训练好的模型往往比较大,需要另到他出下载,当我们有了一个项目的想法以后,并确定了要用哪些项目时候,切记几件事,不然后面会很影响效率
对模型的实现原理有一定的了解
对其输入输出的数据格式有很完善的了解
自己要有自己的思考,不然全是单纯的接受会让你丧失了对整个项目全貌的认识,如果这样,接下来就是痛苦时间了(想想初高中古诗、文言文、散文、诗歌为啥那么熬人,现在偶尔看到的时候,都是woc,这文章写的牛逼,可是为啥当时我咋那么痛苦呢?),这都是被动接受,在学习之前不愿意全局掌控的过,如果有看过这篇文章,后来没有这样做遇到头疼问题的同志,问你个问题,知道大鹅仲么叫咩?GAI!!!
ok,废话说完,开工
opencv
连接手机摄像头,并通过其一些小函数,对图片进行一些简单的处理,手机上要下载一个appip摄像头
import cv2
video="http://admin:[email protected]:8081/" #此处@后的ipv4 地址需要修改为自己的地址
# 参数为0表示打开内置摄像头,参数是视频文件路径则打开视频
capture =cv2.VideoCapture(video)
# 建个窗口并命名
cv2.namedWindow("camera",1)
# 用于循环显示图片,达到显示视频的效果
while True:
ret, frame = capture.read()
# 在frame上显示test字符
image1=cv2.putText(frame,'test', (50,100),
cv2.FONT_HERSHEY_COMPLEX_SMALL, 2, (255, 0 ,0),
thickness = 2, lineType = 2)
cv2.imshow('camera',frame)
# 不加waitkey() 则会图片显示后窗口直接关掉
key = cv2.waitKey(3)
if key == 27:
#esc键退出
print("esc break...")
break
if key == ord(' '):
# 保存一张图像
num = num+1
filename = "frames_%s.jpg" % num
cv2.imwrite(filename,frame)
mtcnn
github上的facenet工程在实现facent的时候,为了便于测试,mtcnn也一放在了工程文件中,在工程中的位置是align/detect_face.py ,它的参数模型也保存在align文件夹下,分别是det1.npy,det2.npy,det3.npy,它的用法便是先将网络搭建出来,定位input中的人脸的位置,然后返回自己设置的固定大小的脸部crop,然后再将其输入facenet就ok了(作用就是人脸检测+定位+对齐,因为我们首要目的是让工程能跑起来,并且对其有一个大体的认识,这才方便后面的学习,具体的实现原理和代码解读,以及物体的检测发展历史,目前的发展方向,各种检测的算法,我会在文章的后面细说)
facenet
facenet.py直接放在主目录下了,其主实现的功能是搭建网络,然后从模型中加载参数,接收固定大小的剪裁好的人脸照片,最终经过embeding层输出1*128的脸部特征向量,计算不同脸部照片的相似度时候直接计算向量的欧式距离就ok了,同一个人的照片,它们的差值比较小,不同的人差值会比较大,其中facenet最后使用的是triplet loss方法来微调embeding(具体的论文算法,网络搭建,各种算法,以及代码解读我都放在文章的最后再说)
工程文件说明(readme)
### 目录结构

20170512-110547文件夹是facent的模型,官方存放在google网盘上了(而且现在出来2018的预训练模型了),不方便下载的我一会儿会把用到的大文件打包放在坚果云上
align文件中包含三个mtcnn要用到的模型,以及搭建mtcnn网络的文件 detect_face.py,这里面的东西在facenet的项目中的都可以找到
models中存放的是训练好的knn模型,用于测试使用的简单模型,一会儿展示的效果也是由其完成
train_dir 顾名思义,就不解释了
facenet.py就是一直在谈的东西,其中包含了如何搭建facenet网络,以及计算的内容
test.py train_knn.py temp_test.py imageconvert.py这几个文件分别人脸识别测试 、 训练knn模型 、 遇到问题是精简代码调试使用 、 图像批量转化 用于准备数据集 其他的没有谈及的文件都没有使用到,应该是以前测试时候忘记删除的
运行效果
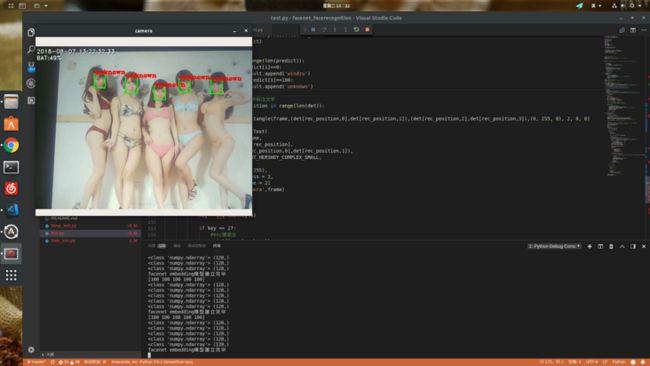
这是使用手机摄像头拍摄ipad从网上随便搜来的合照进行测试(也许也不是随便搜的...),能够准确将人脸框出,并进行识别,因为我使用的是knn训练的,而这几个人是未经过特殊训练的,所以将其归结为未知人群,再接下来一段时间会对其进行改进,最终效果应该是可以实现单张图片数据库比对,这样就不用对需要识别的目标每一个都训练一遍了,这也是人脸识别要达到的效果,上面所说的triplet loss就是一种很好的方法
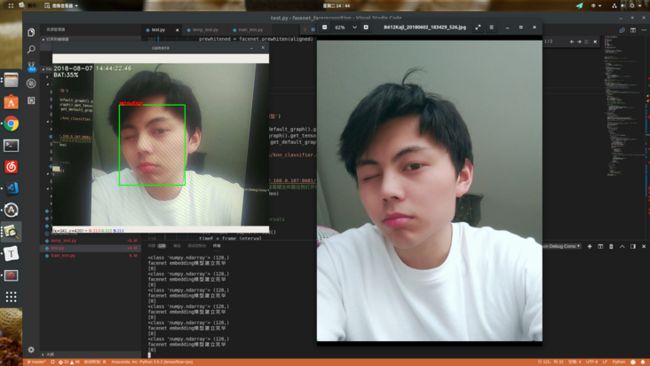
因为房间光线比较暗,用手机摄像头拍摄以前的自拍,识别成功
运行环境和运行说明
推荐使用Anaconda配置tensorflow环境(因为本项目就是基于tensorflow框架的),是cpu版本(等新卡,其实就是穷...)网上教程很多,也很简单,本环境的python版本是3.6的,如果你的是2.7的话,那就要改很多东西了(跟着报错改就ok),但何不如再安装个3.6的呢,在anaconda下真的是超级方便
编辑器用的是vscode,从windows转来,习惯使用vscode,真的很好用,在安装anaconda的时候会提示你是否装个vscode的,当然使用其他的也很好
一些依赖库当然是必备的,提示少啥装啥吧,我也忘了,反正那些基本的是要装的,比如numpy maplotlib jupyter scikit-image librosa kersa 这些,安装也很简单,在anaconda里安装 使用conda命令 或者如果你的linux的默认python就是anaconda里的,直接使用pip安装就好了
本项目里的几个运行的代码,我都写好了参数,直接运行即可(当然制定文件要在指定位置) 运行顺序是
准备好自己的训练集 几十张自己照片即可(尺寸要小一点的,最好500*500以下,不然速度慢,精度低),放到train_dir/pic_me 文件夹下面,把我打包文件里的pic_others文件夹中的放到指定train_dir/pic_others下面(这部分数据也可以自己准备,我的数据是来自lfw中的前几百张图片)
运行train_knn.py 得到自己的knn模型
运行test.py (记得要把手机上的ip摄像头app打开,点击下面打开IP摄像头服务器 ,并检查下显示的局域网ip和test.py 中的是否相同,如不相同,改一下)
启动的时候会比较慢,30s到一分钟左右,取决于电脑性能
至此你应该已经成功跑起来这个项目了,在此感谢开源的伟大,让我们能感受到这些神奇的算法
阅读代码和重构项目建议
好学的各位爷肯定是要将代码好好看一通的,因为我也是菜鸡,看到拙劣之处,请会心一笑...
代码思路
使用mtcnn截取视频帧中人像的人脸,并拉伸为固定大小(这里为160*160,由使用的facenet网络所受限)
将上一步骤得到的人脸输入facenet,得到embedding层的输出,一个人像对应一个1*128数据,然后将其输入knn网络,得到预测结果
学习思路
一定一定要搞清楚其中的数据流是以什么样的格式和形式在传递,其中大多数使用的都是numpy.ndarray数据类型,此外便要掌握一些基本的此类数据类型的格式转换函数,并熟记,很常用的,还有就是和list 的转换
掌握一点点opcv的读写函数
掌握一些对文件操作的函数
至此,你应该已经很容易的就能够吃透本项目的内容了,读完下面的论文和各种算法的衍生,相信你一定对计算机视觉会有更加深刻的认识,并且会觉得豁然开朗~
接下来的暑假时间我要去玩玩其他的方向了,比如NLP啥的,好像很火,找工作简历里还是有几个项目好,之前说好的解读,我会在晚上打完游戏的时候写,毕竟一天沉淀的时间,我保证肯定会写的,各位爷,白了个白
mtcnn
关于物体检测的牛逼好文 基于深度学习的目标检测
Selective Search中如何选择初始时Bounding Box区域合并原理
图文并茂详细介绍的目标检测重大发展的paper原理基于深度学习的目标检测技术演进
facenet
参考文章