前沿|PaddlePaddle开源项目DeepNav“无人船”炼成记(一)
前言:本系列将集中展示PaddlePaddle的开源项目,即PaddlePaddle研发团队在深度学习领域的前沿研究成果。首先展示DeepNav自动驾驶船项目,本次呈现背景以及支撑理论,后续将逐步呈现项目从设计到落地的全过程。文章素材来源于百度美国研究院王益老师的知乎专栏,希望能够给大家带来新启发。
自动驾驶船的诞生背景
DeepNav 是百度美国研究院最近开始的一个自动驾驶船的研究项目。和 Google、Baidu 的无人车技术以及很多远洋货轮的自动驾驶系统采用 rule-based 的知识库不同,DeepNav 意在探索用 deep imitation learning 来让船(和车)学习人类的驾驶技法,同时做一些人类划定的安全范围之内的探索 —— 如果在自主探索中,船和车发现自己面对窘境且无法自拔,会求助人类教练的指导。
DeepNav 目前还处在刚开始的阶段。我们开设这个专栏,是为了记录下我们的点滴足迹,一方面方便和行内专家交流,一方面也便于我们自己回顾过程、总结经验教训。
DeepNav 是一个开源项目。设计文档、硬件设计和规格、以及软件的源码都放在 DeepNav/DeepNav
(https://github.com/deepnav/deepnav)中。欢迎大家多提宝贵意见。
理论基础
深度学习
深度学习系统(包括 TenosrFlow、Caffe2、MxNet、PyTorch、PaddlePaddle 等)是为了方便深度学习者(人称 deep learners)们写人工智能程序的开发工具。要做好一个开发工具,得先了解客户的需求。而 deep learners 的需求和 deep learning 解决的问题密切相关。
深度学习发展到今天,解决了很多统计学多年来没能解决好的问题。每一类问题的解决,背后往往是一种深度学习技术的发明;而深度学习工具往往随着这些技术进化,以方便 deep learners 们使用这些技术来创作新的模型。到目前为止,一系列重要发明大致可用如表格所示
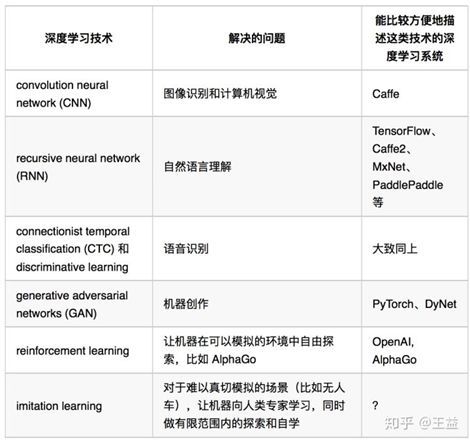
上表中,自主探索(reinforcement learning) 一栏中的工具(OpenAI 和 AlphaGo)已经不是一般大家理解中的深度学习系统了。而学习加探索(imitation learning) 更是没有广为接受的工具。这是因为自主探索 和学习加探索 不再有明显的“训练”(training)和“推演”(inference)的划分;而是在学习过程中,机器既要不断更新自己的知识(所谓的训练)也要利用现有的知识做尝试(所谓的推演)。
在无人车/船/飞机等应用中,这样复杂的计算则是
1. 和传感器以及人类教练实时结合、并且运行在嵌入式系统里(而不是服务器上)的;
2. 控制代码和机器学习代码交织。
PaddlePaddle 的发展方向,希望是面向未来的。那么先得弄明白这个问号所在的格子里的工具,应该解决什么样子的问题。这里需要了解 immitation learning,并同步了解reinforcement learning—— 这是大名鼎鼎的 AlphaGo 背后使用的技术。
自主探索(Reinforcement Learning)
自主探索要解决的问题是学习一个函数(人称策略函数)a=π(s);其中 s 表示当前状态,π 应该根据当前状态返回应该做的操作 a。
拿围棋举例:s 是当前棋局,有19x19个落子位置,每个位置可以有黑子、白子、或者无子三种状态。所以 π 要能处理 (19x19)³ 种状态。在每种状态下,π 返回的选择应该是在某个无子的位置落子。所谓的“学习”,就是把 π 表示为一个神经元网络时,估计其参数,从而确定 π 的函数形式。
我们可以很容易地写一个程序,来记录棋局。如果局面上已经没有可以落子的地方了,这个程序就数数双方谁的地盘大,从而判断输赢。这个程序就是围棋的模拟器。
有了模拟器,自主探索算法可以自己跟自己下棋 —— 如果一系列的决定导致某一方赢了(或者吃掉了对方一片地盘),那么这一系列的决定可能都是不错的选择;否则,则可能是下次应该避免的。这个过程的核心思想是“探索” —— 有了模拟器,机器可以尝试在任何地方落子 —— 最不济就是输一盘。通过利用超级计算机,AlphaGo 的探索超过了整个人类几千年来的探索!
在和人类棋手对弈的时候,AlphaGo 下了一招“臭棋”。所谓臭棋,就是人类曾经多次试着这么下,结果发现接下来“很容易输”,以至于师傅会告诫徒弟,甚至大家都会注意避免。但是请注意,臭棋只是意味着接下来“很可能输”。而 AlphaGo 在探索过程中发现其实有一种“接下来”的策略,可以翻转局面,并且利用了它发现的这样的知识,击败了重量级人类棋手。这是探索的力量。
AlphaGo 的成功应用自主探索,借助了两个要素:
1. 围棋可以有模拟器,所以可以让 AlphaGo 无尽地探索
2. 现代计算能力(大机群和GPU等计算加速硬件)
以至于它不需要向人类棋手学习,而是可以自主探索。
学习加探索(Imitation Learning)
但是无人车/船/飞机这类更“有用“的应用是没法写一个真切的模拟器的,因为其中物理过程太过复杂,以至于写一个真切的模拟器比机器学习本身更难。所以对这类应用,大家只好用真的车/船/飞机。
当我们依赖物理设备的时候,机器学习算法就不能“任意尝试”了。在围棋模拟器里,机器可以任意落子,看看后果 —— 最不济就是输一盘。而如果让机器任意尝试开车,那可能就会车毁人亡。
为了限制“任意探索”,最好就是让机器先学习人类的驾驶技法,然后在学到的知识基础上,做有限的自主尝试。这就是 学习加探索。
要不是有“有限的自主尝试”,这个主意听上去就完全是 supervised learning 了。可是如果只做 supervised learning,那是不够的。因为人类的示范,出于安全性的考虑,是会让船保持在“正常”状态的。所以机器学习不到如何应付不正常的、危险状态。那么在实际运行中,一旦进入到不正常状态,就几乎一定车毁人亡了。
为了学习和理解学习加探索如何即向人类学习又能做有限度自主探索,笔者和同事王鹤麟一起请教了百度 IDL 在美国研究院的几位做 自主探索和学习加探索的同事:余昊男、张海超和连晓晨。从这篇论文 Imitation Learning: A Survey of Learning Methods的调研部分开始学习各种算法,并选定了 Dagger([1011.0686] A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning )。
Dagger 算法要求我们知道在给定一系列状态下的最优策略 π*。在不少论文里,这个最优策略是通过写一个模拟器来实现的 —— 但是如上文所述,很多真实应用是没法写真切的模拟器的。另外一些论文里假设可以有人类专家来标注状态对应的策略 —— 这也不切实际。
参考文献链接
1.Hussein A, Gaber MM, Elyan E, Imitation Learning: A Survey of Learning Methods[J].2017.
(https://dl.acm.org/citation.cfm?id=3054912)
*为了方便大家使用PaddlePaddle,遇到问题可在中文社区提问,值班同学将在24小时内响应!更有精品案例、课程提供,让大家学习使用框架,轻松无忧!直达链接:
https://ai.baidu.com/forum/topic/list/168
