使用pytorch进行语义分割模型训练
这篇文章我主要介绍一下我搭建的语义分割任务框架,这个框架可以训练很多语义分割模型。
我主要是在PASCAL VOC上训练了FCN网络,希望对大家能有所帮助。
项目架构
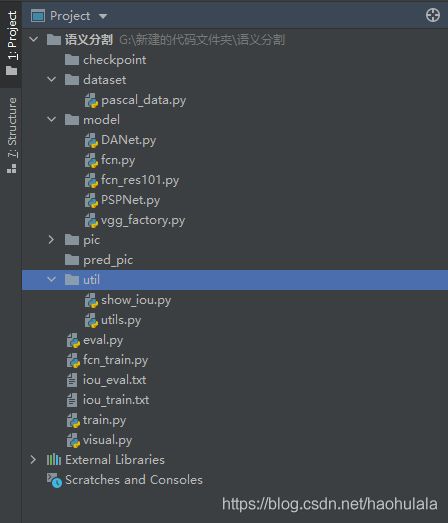
上图就是项目架构了,我介绍几个主要的东西
checkpoint:用来存放中间的结果文件
dataset:用来存放加载数据集的文件
model:用来存放网络模型
pic:存放混淆矩阵可视化图片
util:用来保存工具脚本
eval.py:计算测试集性能指标的代码
train.py:训练代码
下面上代码
dataset/pascal_data.py
import torch
import torchvision.transforms as tfs
import os
import scipy.io as scio
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import random
# PASCAL VOC语义分割增强数据集
prefix = "G:/data/VOCBSD/"
# 超参数,设置裁剪的尺寸
CROP = 256
class PASCAL_BSD(object):
def __init__(self, mode="train", change=False):
super(PASCAL_BSD, self).__init__()
# 读取数据的模式
self.mode = mode
# 类别标签,一共有20+1个类
self.classes = ['background','aeroplane','bicycle','bird','boat',
'bottle','bus','car','cat','chair','cow','diningtable',
'dog','horse','motorbike','person','potted plant',
'sheep','sofa','train','tv/monitor']
# 颜色标签,分别对应21个类别
self.colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128],
[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],
[64,128,0],[192,128,0],[64,0,128],[192,0,128],
[64,128,128],[192,128,128],[0,64,0],[128,64,0],
[0,192,0],[128,192,0],[0,64,128]]
self.im_tfs = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 将mat格式的数据转换成png格式
if (change == True):
self.mat2png()
self.image_name = []
self.label_name = []
self.readImage()
print("%s->成功加载%d张图片"%(self.mode, len(self.image_name)))
# 读取图像和标签信息
def readImage(self):
img_root = prefix + "JPEGImage/"
label_root = prefix + "SegmentationClass/"
if(self.mode == "train"):
with open(prefix+"train.txt", "r") as f:
list_dir = f.readlines()
elif(self.mode == "val"):
with open(prefix + "val.txt", "r") as f:
list_dir = f.readlines()
for item in list_dir:
self.image_name.append(img_root + item.split("\n")[0] + ".jpg")
self.label_name.append(label_root + item.split("\n")[0] + ".png")
# 数据处理,输入Image对象,返回tensor对象
def data_process(self, img, img_gt):
if(self.mode == "train"):
# 以50%的概率左右翻转
a = random.random()
if(a > 0.5):
img = img.transpose(Image.FLIP_LEFT_RIGHT)
img_gt = img_gt.transpose(Image.FLIP_LEFT_RIGHT)
# 以50%的概率上下翻转
a = random.random()
if(a > 0.5):
img = img.transpose(Image.FLIP_TOP_BOTTOM)
img_gt = img_gt.transpose(Image.FLIP_TOP_BOTTOM)
# 以50%的概率像素矩阵转置
a = random.random()
if (a > 0.5):
img = img.transpose(Image.TRANSPOSE)
img_gt = img_gt.transpose(Image.TRANSPOSE)
a = random.random()
# 进行随机裁剪
width, height = img.size
st = random.randint(0,20)
box = (st, st, width-1, height-1)
img = img.crop(box)
img_gt = img_gt.crop(box)
img = img.resize((CROP, CROP))
img_gt = img_gt.resize((CROP, CROP))
img = self.im_tfs(img)
img_gt = np.array(img_gt)
img_gt = torch.from_numpy(img_gt)
"""
plt.subplot(1,2,1), plt.imshow(img.permute(1,2,0))
plt.subplot(1,2,2), plt.imshow(img_gt)
plt.show()
"""
return img, img_gt
def add_noise(self, img, gama=0.2):
noise = torch.randn(img.shape[0], img.shape[1], img.shape[2])
noise = noise * gama
img = img + noise
return img
def __getitem__(self, idx):
# idx = 100
img = Image.open(self.image_name[idx])
img_gt = Image.open(self.label_name[idx])
img, img_gt = self.data_process(img, img_gt)
# img = self.add_noise(img)
return img, img_gt
def __len__(self):
return len(self.image_name)
# 将mat数据转换成png
def mat2png(self, dataDir=None, outputDir=None):
if(dataDir == None):
dataroot = prefix + "cls/"
else:
dataroot = dataDir
if(outputDir == None):
outroot = prefix + "SegmentationClass/"
else:
outroot = outputDir
list_dir = os.listdir(dataroot)
for item in list_dir:
matimg = scio.loadmat(dataroot + item)
mattmp = matimg["GTcls"]["Segmentation"]
# 将mat转换成png
#print(mattmp[0][0])
new_im = Image.fromarray(mattmp[0][0])
print(outroot + item[:-4] + ".png")
new_im.save(outroot + item[:-4] + ".png")
"""
标签文件的使用方法,需要先转换成numpy再变成tensor
img = Image.open(outroot + item[:-4] + ".png")
img = np.array(img)
img = torch.from_numpy(img)
print(img.shape)
plt.imshow(img)
plt.colorbar()
plt.show()
"""
if __name__ == "__main__":
data_train = PASCAL_BSD("train")
data_val = PASCAL_BSD("val")
train_data = torch.utils.data.DataLoader(data_train, batch_size=16, shuffle=True)
val_data = torch.utils.data.DataLoader(data_val, batch_size=16, shuffle=False)
for item in val_data:
img, img_gt = item
print(img.shape)
print(img_gt.shape)model/fcn_res101.py
import torch
import torch.nn as nn
import torchvision.models as models
class FCN(nn.Module):
def __init__(self, out_channel=21):
super(FCN, self).__init__()
self.backbone = models.resnet101(pretrained=True)
# 4倍下采样 256
self.stage1 = nn.Sequential(*list(self.backbone.children())[:-5])
# 8倍下采样 512
self.stage2 = nn.Sequential(list(self.backbone.children())[-5])
# 16倍下采样 1024
self.stage3 = nn.Sequential(list(self.backbone.children())[-4])
# 32倍下采样 2048
self.stage4 = nn.Sequential(list(self.backbone.children())[-3])
self.conv2048_256 = nn.Conv2d(2048,256,1)
self.conv1024_256 = nn.Conv2d(1024,256,1)
self.conv512_256 = nn.Conv2d(512,256,1)
self.upsample2x = nn.Upsample(scale_factor=2)
self.upsample8x = nn.Upsample(scale_factor=8)
self.outconv = nn.Conv2d(256,out_channel,kernel_size=3,stride=1,padding=1)
def forward(self, input):
output = self.stage1(input)
output_s8 = self.stage2(output)
output_s16 = self.stage3(output_s8)
output_s32 = self.stage4(output_s16)
output_s8 = self.conv512_256(output_s8)
output_s16 = self.conv1024_256(output_s16)
output_s32 = self.conv2048_256(output_s32)
output_s32 = self.upsample2x(output_s32)
output_s16 = output_s16 + output_s32
output_s16 = self.upsample2x(output_s16)
output_s8 = output_s8 + output_s16
output_s8 = self.upsample8x(output_s8)
final_output = self.outconv(output_s8)
return final_output
if __name__ == "__main__":
img = torch.rand(1,3,256,256).cuda()
net = FCN().cuda()
output = net(img)
print(output.shape)util/utils.py
import torch
import numpy as np
import matplotlib.pyplot as plt
# 超参数,类别数量
class_num = 21
####################
# 计算各种评价指标 #
####################
def fast_hist(a, b, n):
"""
生成混淆矩阵
a 是形状为(HxW,)的预测值
b 是形状为(HxW,)的真实值
n 是类别数
"""
# 确保a和b在0~n-1的范围内,k是(HxW,)的True和False数列
a = torch.softmax(a, dim=1)
_, a = torch.max(a, dim=1)
a = a.cpu().numpy()
b = b.cpu().numpy()
k = (a >= 0) & (a < n)
# 横坐标是预测的类别,纵坐标是真实的类别
hist = np.bincount(a[k].astype(int) + n * b[k].astype(int), minlength=n ** 2).reshape(n, n)
# print(hist[20])
return hist
def per_class_iou(hist):
"""
hist传入混淆矩阵(n, n)
"""
# 因为下面有除法,防止分母为0的情况报错
#np.seterr(divide="ignore", invalid="ignore")
# 交集:np.diag取hist的对角线元素
# 并集:hist.sum(1)和hist.sum(0)分别按两个维度相加,而对角线元素加了两次,因此减一次
iou = np.diag(hist) / (hist.sum(1) + hist.sum(0) - np.diag(hist))
# 把报错设回来
#np.seterr(divide="warn", invalid="warn")
# 如果分母为0,结果是nan,会影响后续处理,因此把nan都置为0
#iou[np.isnan(iou)] = 0.
return iou
def per_class_acc(hist):
"""
:param hist: 混淆矩阵
:return: 没类的acc和平均的acc
"""
np.seterr(divide="ignore", invalid="ignore")
acc_cls = np.diag(hist) / hist.sum(1)
np.seterr(divide="warn", invalid="warn")
acc_cls[np.isnan(acc_cls)] = 0.
return acc_cls
# 使用这个函数计算模型的各种性能指标
# 输入网络的输出值和标签值,得到计算结果
def get_MIoU(pred, label, hist):
"""
:param pred: 预测向量
:param label: 真实标签值
:return: 准确率,每类的准确率,每类的iou, miou
"""
hist = hist + fast_hist(pred, label, class_num)
# print(hist[20])
# 准确率
acc = np.diag(hist).sum() / hist.sum()
# 每类的准确率
acc_cls = per_class_acc(hist)
# 每类的iou
iou = per_class_iou(hist)
miou = np.nanmean(iou[1:])
return acc, acc_cls, iou, miou, hist
# 更新学习率
def getNewLR(LR, net):
LR = LR / 2
print("更新学习率LR=%.6f"%LR)
optimizer = torch.optim.Adam(net.parameters(), lr=LR, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
return optimizer, LR
# 绘制hist矩阵的可视化图并保存
def drawHist(hist, path):
# print(hist)
hist_ = hist[1:]
hist_tmp = np.zeros((class_num-1, class_num-1))
for i in range(len(hist_)):
hist_tmp[i] = hist_[i][1:]
# print(hist_tmp)
hist = hist_tmp
plt.matshow(hist)
plt.xlabel("Predicted label")
plt.ylabel("True label")
plt.axis("off")
#plt.colorbar()
#plt.show()
if(path != None):
plt.savefig(path)
print("%s保存成功✿✿ヽ(°▽°)ノ✿"%path)
if __name__ == "__main__":
hist = np.random.randint(0,20,size=(21,21))
drawHist(hist, None)eval.py
import torch
import torch.nn as nn
import model.PSPNet as PSPNet
import model.DANet as DANet
import model.fcn as FCN
import model.fcn_res101 as fcn_res101
import util.utils as tools
import dataset.pascal_data as pascal_data
import dataset.cityspaces as cityspaces
import time
import os
import numpy as np
BATCH = 8
class_num = 21
# 对整个验证集进行计算
def eval_val(net, criterion=None, show_step=True, epoch=0):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_val = pascal_data.PASCAL_BSD("val")
# data_val = cityspaces.CITYSPACES("val")
val_data = torch.utils.data.DataLoader(data_val, batch_size=BATCH, shuffle=False)
net = net.to(device)
net = net.eval()
if(criterion == None):
criterion = nn.CrossEntropyLoss()
loss_all = 0
acc = 0
acc_cls = 0
iou = 0
miou = 0
hist = np.zeros((class_num, class_num))
st_epoch = time.time()
for step, data in enumerate(val_data):
st_step = time.time()
img, img_gt = data
img = img.to(device)
img_gt = img_gt.to(device)
with torch.no_grad():
output = net(img)
# 计算各项性能指标
acc, acc_cls, iou, miou, hist = tools.get_MIoU(pred=output, label=img_gt, hist=hist)
"""
label_true = img_gt.cpu().numpy()
label_pred = torch.argmax(torch.softmax(output, dim=1), dim=1)
for lbt, lbp in zip(label_true, label_pred):
acc, acc_cls, miou, fwavacc = tools.label_accuracy_score(lbt, lbp, 21)
"""
# 计算损失值
loss = criterion(output, img_gt.long())
loss_all = loss_all + loss.item()
if(show_step == True):
print("(val)step[%d/%d]->loss:%.4f acc:%.4f miou:%.4f time:%ds" %
(step + 1, len(val_data), loss.item(), acc, miou, time.time() - st_epoch))
epoch_loss = loss_all / len(val_data)
epoch_acc = acc
epoch_miou = miou
print("val->loss:%.4f acc:%.4f miou:%.4f time:%ds" %
(epoch_loss, epoch_acc, epoch_miou, time.time() - st_epoch))
with open("iou_eval.txt", "a") as f:
f.write("epoch%d->"%(epoch) + str(iou) + "\n\n")
# 保存hist矩阵
Hist_path = "./pic/epoch-%03d_val_hist.png"%(epoch)
tools.drawHist(hist, Hist_path)
return epoch_loss, epoch_acc, epoch_miou
# 将checkpoint文件夹中保存的模型都计算一遍
def eval_root():
list_dir = os.listdir("./checkpoint")
#net = PSPNet.PSPNet()
#net = FCN.FCN()
net = fcn_res101.FCN()
max_miou = -1
max_item = ""
for item in list_dir:
print(item)
net.load_state_dict(torch.load("./checkpoint/" + item))
epoch_loss, epoch_acc, epoch_miou = eval_val(net=net, show_step=False)
if(max_miou < epoch_miou):
max_miou = epoch_miou
max_item = item
print("max miou:%.4f item:%s"%(max_miou, max_item))
if __name__ == "__main__":
eval_root()
train.py
import torch
import torch.nn as nn
import model.PSPNet as PSPNet
import model.DANet as DANet
import model.fcn as FCN
import model.fcn_res101 as fcn_res101
import util.utils as tools
import dataset.pascal_data as pascal_data
import dataset.cityspaces as cityspaces
import eval
import time
import numpy as np
import matplotlib.pyplot as plt
# 各种标签所对应的颜色
colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128],
[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],
[64,128,0],[192,128,0],[64,0,128],[192,0,128],
[64,128,128],[192,128,128],[0,64,0],[128,64,0],
[0,192,0],[128,192,0],[0,64,128]]
cm = np.array(colormap).astype("uint8")
#############
# 超参数设置 #
#############
BATCH = 10
LR = 5e-6
EPOCHES = 50
class_num = 21
WEIGHT_DECAY = 1e-4
def train(offset, model,lr_update=False, show_img=False):
# 加载网络
# net = PSPNet.PSPNet()
# net = DANet.DANet()
# net = FCN.fcn()
net = fcn_res101.FCN()
if(model != None):
net.load_state_dict(torch.load(model))
print(model)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
# 加载数据
data_train = pascal_data.PASCAL_BSD("train")
# data_train = cityspaces.CITYSPACES("train")
# data_val = pascal_data.PASCAL_BSD("val")
train_data = torch.utils.data.DataLoader(data_train, batch_size=BATCH, shuffle=True)
# val_data = torch.utils.data.DataLoader(data_val, batch_size=BATCH, shuffle=False)
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(net.parameters(), lr=LR, betas=(0.9, 0.999), eps=1e-08, weight_decay=WEIGHT_DECAY)
#optimizer = torch.optim.SGD(net.parameters(), lr=LR, weight_decay=1e-4)
learning_rate = LR
# 开始训练
print("开始训练(〃'▽'〃)")
for epoch in range(EPOCHES):
# 总的损失值
loss_all = 0
# 评估的四个指标
acc = 0
acc_cls = 0
iou = 0
miou = 0
hist = np.zeros((class_num, class_num))
st_epoch = time.time()
net = net.train()
for step, data in enumerate(train_data):
st_step = time.time()
img, img_gt = data
img = img.to(device)
img_gt = img_gt.to(device)
# 前向传播
output = net(img)
# 计算各项性能指标
acc, acc_cls, iou, miou, hist = tools.get_MIoU(pred=output, label=img_gt, hist=hist)
# print(hist[20])
"""
label_true = img_gt.cpu().numpy()
label_pred = torch.argmax(torch.softmax(output, dim=1), dim=1)
for lbt, lbp in zip(label_true, label_pred):
acc, acc_cls, miou, fwavacc = tools.label_accuracy_score(lbt, lbp, 21)
"""
# 计算损失值
loss = criterion(output, img_gt.long())
loss_all = loss_all + loss.item()
# 反向传播更新网络
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (show_img == True):
plt.subplot(1,3, 1), plt.imshow(img.cpu().detach()[0].permute(1, 2, 0).numpy()), plt.axis("off")
plt.subplot(1, 3, 2), plt.imshow(cm[img_gt[0].detach().cpu().numpy()]), plt.axis("off")
plt.subplot(1, 3, 3)
_, idx = torch.max(torch.softmax(output, dim=1), dim=1)
plt.imshow(cm[idx[0].cpu().detach().numpy()]), plt.axis("off")
# plt.colorbar()
plt.show()
# 打印当前信息
print("step[%d/%d]->loss:%.4f acc:%.4f miou:%.4f lr:%.6f time:%ds"%
(step+1, len(train_data),loss.item(),acc, miou, learning_rate,time.time()-st_epoch))
print(iou)
# print(hist)
# 一个epoch训练完成,计算当前epoch数据
epoch_loss = loss_all / len(train_data)
epoch_acc = acc
epoch_miou = miou
print(np.diag(hist))
# 打印信息
print("epoch[%d/%d]->loss:%.4f acc:%.4f miou:%.4f lr:%.6f time:%ds" %
(epoch, len(train_data)-1, epoch_loss, epoch_acc, epoch_miou, learning_rate,time.time() - st_epoch))
# 在验证集上计算
val_loss, val_acc, val_miou = eval.eval_val(net=net, criterion=criterion, epoch=epoch+offset)
# 保存当前训练数据
path = "./checkpoint/epoch-%03d_loss-%.4f_loss(val)-%.4f_acc-%.4f_miou-%.4f_miou(val)-%.4f.pth"%\
(epoch+offset, epoch_loss,val_loss, epoch_acc, epoch_miou, val_miou)
torch.save(net.state_dict(), path)
print("成功保存模型%s✿✿ヽ(°▽°)ノ✿"%(path))
with open("iou_train.txt", "a") as f:
f.write("epoch%d->"%(epoch+offset) + str(iou) + "\n\n")
# 保存hist矩阵
Hist_path = "./pic/epoch-%03d_train_hist.png"%(epoch+offset)
tools.drawHist(hist, Hist_path)
# 更新学习率
if(lr_update == True):
# 每20个epoch就将学习率降低10倍
if (epoch+offset == 10):
learning_rate = 1e-5
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate, betas=(0.9, 0.999), eps=1e-08,
weight_decay=WEIGHT_DECAY)
print("当前学习率lr=%.8f" % (learning_rate))
if (epoch+offset == 20):
learning_rate = 5e-6
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate, betas=(0.9, 0.999), eps=1e-08,
weight_decay=WEIGHT_DECAY)
print("当前学习率lr=%.8f" % (learning_rate))
return 0
if __name__ == "__main__":
offset = 0
model = None
train(offset=offset, model=model,lr_update=False, show_img=False)上面就是主要代码了,这是个基本的架构,大家可以根据自己的需要修改或者添加代码
下面来看看我训练的结果
训练集可视化






训练集的混淆矩阵可视化

测试集的混淆矩阵可视化

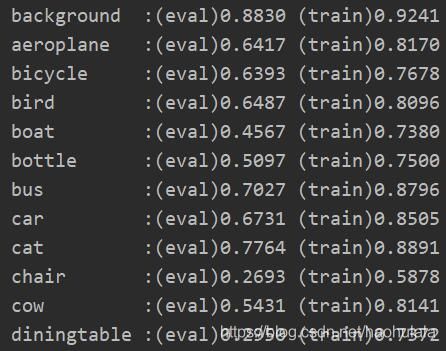
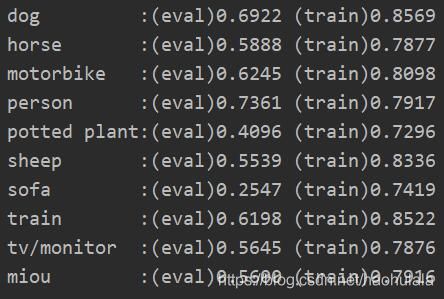
各个类别的IOU(计算miou的时候没有将背景算进去)