BiSeNet V3: Bilateral Segmentation Network with Coordinate Attention for Real-time Semantic Segment
代码暂未公布。
Bisenet有四个系列,分别是bisenetv1,bisenetv2,bisenetv3,和rethink bisenet(STDC)。今天直接V3是着重想看一下边缘提取部分。
摘要:
空间信息和感受野对语义分割是非常重要的,具体体现在,空间信息每个像素和邻近的像素组成一个物体,每个像素和整张图片其他所有像素的关系组成图片的语义信息,而感受野则是模型可以覆盖到整张图片,这样有利于语义信息的提取。
现在的大多方法都在分辨率和低层细节信息做了妥协。作者提出了bisenetv3,引入特征完善和特征融合模块,有效的结合特征。同时使用注意力机制帮助模型捕捉上下文信息。同时引入边缘检测技术增强特征的边界。SOTA。
引言:
ICNet:降低输入图像的分辨率,简单高效,损失空间细节,导致精度下降。
ENet:移除模型最后几个stage,减少冗余性,导致感受野不足以覆盖整张图片。
实时语义分割需要快速推理并且不损失精确性。
为了减少空间细节的丢失:
U-shape结构:backbone在imagenet上预训练,然后不断下采样。
SFNet:提出FAM模块,对齐相同stage的特征图,用于更高效的融合。
对于实时语义分割:
Bisenet提出空间分支和context分支,空间分支减少空间信息的损耗,保持细节信息,context增加感受野。
STDCNet重新提出了backbone,提取感受野和多尺度信息。同时移除了冗余的路径,加入细节引导模块。
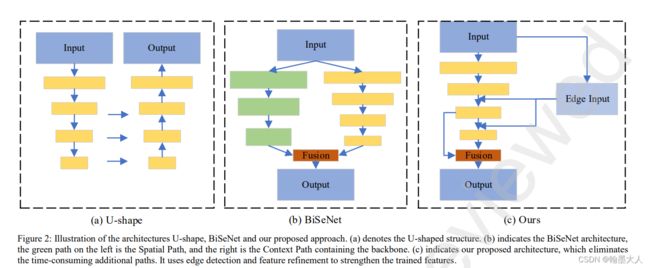
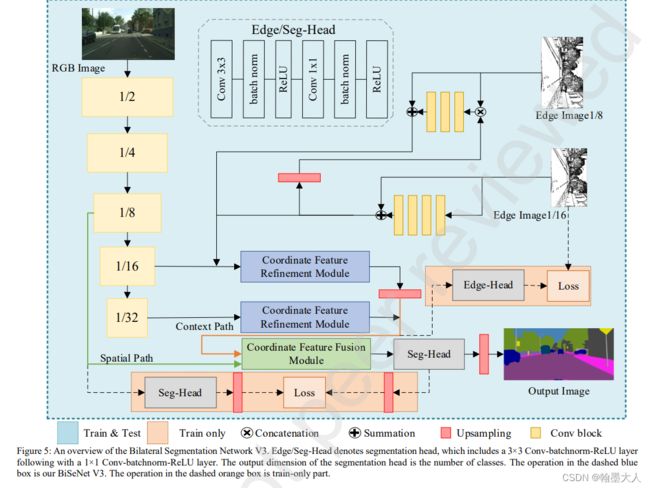
本文Bisenetv3使用STDCNet的backbone,移除消耗时间的空间分支,和注意力模块ARM,和特征融合模块FFM,加入了传统的边界检测模块和两个新模块。encoder已经处理的很好了,作者更关注于decoder部分。提出了CFRM和SFFM。同时语义分割对于边界检测有很强的任务相关性。使用了传统的边界检测算法增强CFRM模块。
相关工作:
1:有效backbone设计:
squeezenet,squeezenext,shufflenet v2,densenet,moboilenet v2,efficientnet,ghostnet。
2:传统语义分割:
fcn,segnet,pspnet,deeplabv3。
3:即时语义分割:
dfanet,bisenet v2,harnet。
本文提出的方法:
两个注意力模块,一个增强特征的边界提取。
1:两个注意力模块
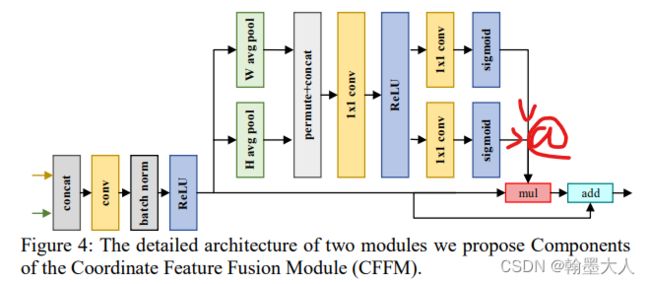
bisenet提出的arm模块,使用平均池化捕捉背景,特征变为cx1x1,这个模块只测量了每个通道的相关性,忽略了空间信息。空间信息对于生成attention map十分重要。因此提出了CFRM模块。

CFRM将图片划分为CXHX1,和CX1XW ,相当于在横轴和纵轴进行平均池化,这种操作也类似于sobel算子的操作。

最后通过sigmoid进行注意力向量的计算进行特征学习。
如何计算attention map:
(CXHX1)@(CX1XW)=CXHXW
与原始图片相乘:
CXHXW * CXHXW=CXHXW
然后将backbone捕捉的全局上下文信息和上下文信息进行结合,即concat。

CFFM模块,在bisenet中宣称,不同stage的特征有不同的层次表示,因此不能直接相加。
decoder的特征具有丰富的语义信息,并且CFRM的模块保持了丰富的语义信息。沿着H和W方向进行平均池化,将特征图划分为CXHX1和CX1XW。CFFM是为了融合特征,接着维度变为CX1X(H+W)。然后使用SEnet减少通道的占比。最后通过sigmoid产生注意力向量,再和原始的图片相乘,再来一个残差连接。这意味着我们考虑了图片中重要和不重要的像素。
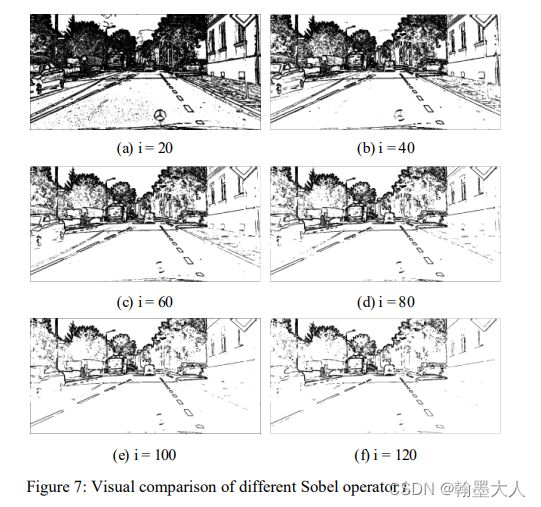
边界检测:边界检测是为了用来捕捉和学习边界信息,来获得细节信息。为了帮助CFRM完善特征,作者加入了sobel操作。去面向目标边缘中模糊和不准确的分割区域。边缘检测方法是用于提取输入特征的边界特征。他和backbone提取的语义分割特征connect在一起。sobel使用梯度向量作为操作。如果阈值设置的过高,将会产生非常多特征。如果太低边界就会看不到或者无效。
注:这个地方应该是提取完特征进行二值化处理,即大于阈值设置为1,反之为0。
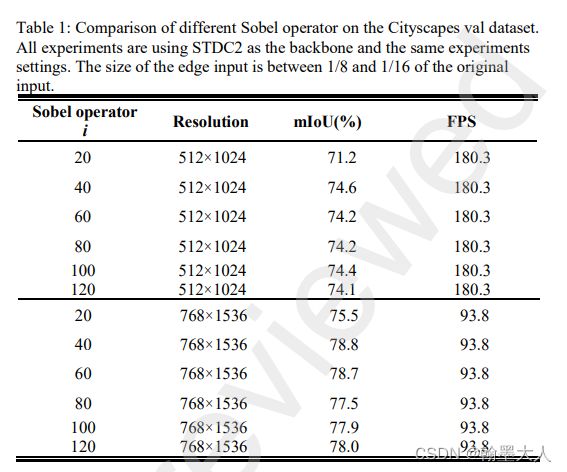
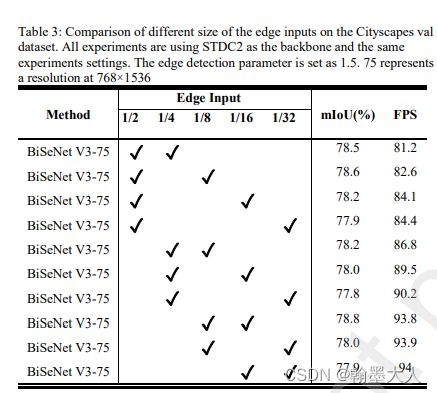
经过试验发现1/8和1/16最合适,阈值设置为40。
边切提取作用就相当于注意力机制,最终输出的边界图是双分类,(binary classfication)。通过检测不同尺度的边界,效果更好。

因为边界的像素总是少于非边界像素,因此需要解决分类平衡问题。因此作者使用binary 交叉熵和dice loss。dice loss对前景和背景不敏感,所以可以缓解分类不平衡问题。

整体网络架构:
实验:
实验细节:
数据增强:

消融实验:
sobel参数设置:i=40最合适。
边缘检测的位置设置:
有效性设置:
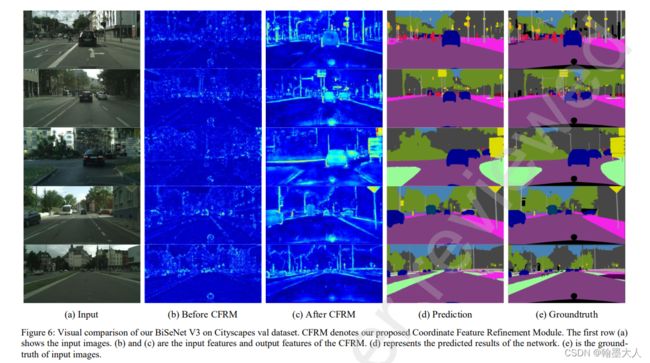
CFRM:效果
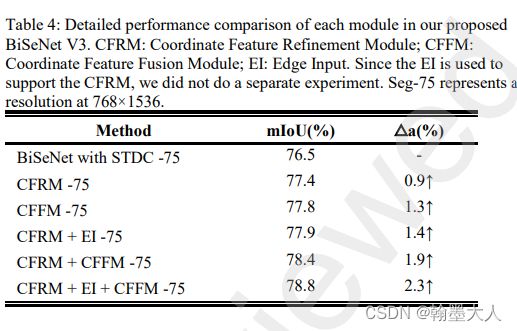
CFFM:
同上。
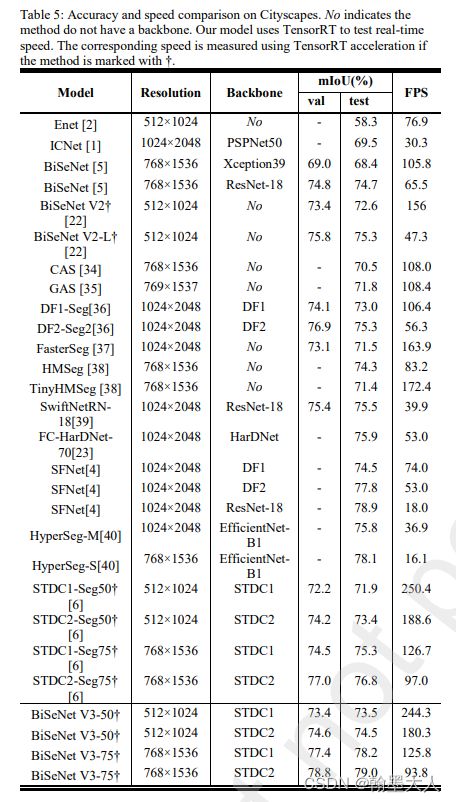
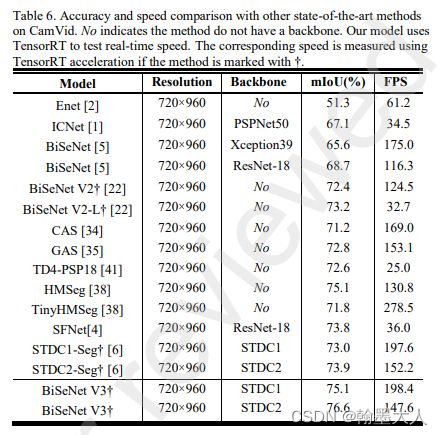
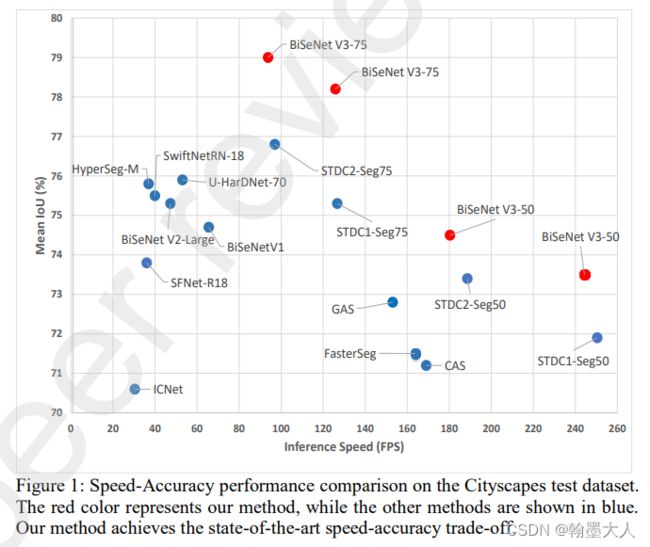
和其他结果比:
在两个数据集上: