【模型加速】CUDA-Pointpillars项目解读(1)
本文主要是在官方给出的技术博客使用NVIDIA CUDA-Pointpillars检测点云中的对象的基础上结合自己的使用体验做一些扩展说明。在以往的模型部署操作中,我们习惯于将训练好的诸如Pytorch模型直接导出为onnx,再通过TensorRT API或者trtexe等工具将onnx序列化为TensorRT引擎文件。之后,加载引擎文件进行推理加速。但是,对于点云3D检测模型pointpillars而言,这样做存在若干障碍。首先,不同于图像这类结构化数据,点云在送入网络之前需要经过相对复杂的预处理过程,其中存在过多的小型操作。强行转换一方面是若干小型操作由onnx转TensorRT不一定支持,另一方面势必会影响推理的速度。其次,pointpillars中点云经过预处理(preprocess)和点云特征提取(pfn)后还要再经过Scatter操作,生成伪图像再送入骨干网络(backbone)。当前TensorRT并不直接支持Scatter操作。所以,也不能直接进行onnx到TensorRT的转换。
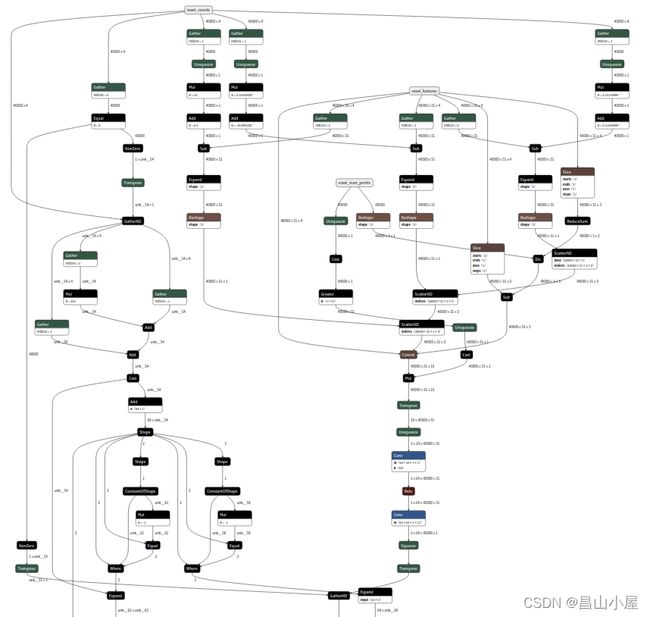
图:pointpillars点云预处理部分操作
综上所述,作者在处理pointpillars的加速时给出了如下方案。整体上分为基础预处理,预处理,TensorRT推理,后处理四个部分。

基础预处理
基础预处理将点云转化为基本特征图,该步骤由CUDA实现。
__global__ void generateBaseFeatures_kernel(unsigned int *mask, float *voxels,
int grid_y_size, int grid_x_size,
unsigned int *pillar_num,
float *voxel_features,
float *voxel_num_points,
float *coords)
{
int voxel_idx = blockIdx.x * blockDim.x + threadIdx.x;
int voxel_idy = blockIdx.y * blockDim.y + threadIdx.y;
if(voxel_idx >= grid_x_size ||voxel_idy >= grid_y_size) return;
unsigned int voxel_index = voxel_idy * grid_x_size
+ voxel_idx;
unsigned int count = mask[voxel_index];
if( !(count>0) ) return;
count = count>>
(mask, voxels, grid_y_size, grid_x_size,
pillar_num,
voxel_features,
voxel_num_points,
coords);
cudaError_t err = cudaGetLastError();
return err;
} 值得一提的时作者在组织CUDA核函数时使用了二维网格。其中threads的大小为{32,32},而blocks的大小为{(grid_x_size + threads.x -1)/threads.x,(grid_y_size + threads.y -1)/threads.y}。对应到默认的pointpillars设置的化就是{14,16}。这样一来核函数线程二维索引号正好对应pillar在x-y坐标系下的二维坐标。

预处理
预处理部分将基本特征图(4个通道)扩展为BEV特征图(10个通道)。同样,这一步骤也是由CUDA实现。generateFeatures_launch为预处理核函数的启动函数,它设定了一个一维的线程组织结构。blocks大小为 ((MAX_VOXELS+WARPS_PER_BLOCK-1)/WARPS_PER_BLOCK),threads的大小为(WARPS_PER_BLOCK*WARP_SIZE)。默认设置,MAX_VOXELS(40000),WARPS_PER_BLOCK(4),WARP_SIZE(32)。在GPU的SM中线程的执行是以线程束为单位的,这里将单个线程块的大小设置为WARPS_PER_BLOCK个WARP_SIZE也是合情合理的。同时,这里WARP_SIZE(32)的大小正好也是pointpillars默认设置中单个pillar可包含的最大点云的数量。综合来看,也就是一个线程块对应处理4个pillar,线程块中的线程分别对应处理4个pillar中的32个点云。又因为一个pillar中个点由基础特征(4通道)扩展出BEV特征(10通道)需要依赖当前pillar所有点的综合信息。所以,在核函数内部使用了共享内存方便进行pillar内的计算结果共享。
cudaError_t generateFeatures_launch(float* voxel_features,
float* voxel_num_points,
float* coords,
unsigned int *params,
float voxel_x, float voxel_y, float voxel_z,
float range_min_x, float range_min_y, float range_min_z,
float* features,
cudaStream_t stream)
{
dim3 blocks((MAX_VOXELS+WARPS_PER_BLOCK-1)/WARPS_PER_BLOCK);
dim3 threads(WARPS_PER_BLOCK*WARP_SIZE);
generateFeatures_kernel<<>>
(voxel_features,
voxel_num_points,
coords,
params,
voxel_x, voxel_y, voxel_z,
range_min_x, range_min_y, range_min_z,
features);
cudaError_t err = cudaGetLastError();
return err;
} 预处理部分的核函数作者非常注意整体性能的优化,由其是在共享内存的访问是刻意避免了bank冲突。
//< 10 channels
__global__ void generateFeatures_kernel(float* voxel_features,
float* voxel_num_points,
float* coords,
unsigned int *params,
float voxel_x, float voxel_y, float voxel_z,
float range_min_x, float range_min_y, float range_min_z,
float* features)
{
int pillar_idx = blockIdx.x * WARPS_PER_BLOCK + threadIdx.x/WARP_SIZE; //e.g. 0,1,2..(N-1)
int point_idx = threadIdx.x % WARP_SIZE; //e.g. 0,1,2...31
int pillar_idx_inBlock = threadIdx.x/32; //e.g 0,1,2,3
unsigned int num_pillars = params[4];
if (pillar_idx >= num_pillars) return;
//load src
__shared__ float4 pillarSM[WARPS_PER_BLOCK][WARP_SIZE]; //4*32*4
__shared__ float4 pillarSumSM[WARPS_PER_BLOCK]; //4*4
__shared__ float4 cordsSM[WARPS_PER_BLOCK]; //4*4
__shared__ int pointsNumSM[WARPS_PER_BLOCK]; //4
__shared__ float pillarOutSM[WARPS_PER_BLOCK][WARP_SIZE][FEATURES_SIZE]; //4*32*10
if (threadIdx.x < WARPS_PER_BLOCK) {
pointsNumSM[threadIdx.x] = voxel_num_points[blockIdx.x * WARPS_PER_BLOCK + threadIdx.x];
cordsSM[threadIdx.x] = ((float4*)coords)[blockIdx.x * WARPS_PER_BLOCK + threadIdx.x];
pillarSumSM[threadIdx.x] = {0,0,0,0};
}
pillarSM[pillar_idx_inBlock][point_idx] = ((float4*)voxel_features)[pillar_idx*WARP_SIZE + point_idx];
__syncthreads();
//calculate sm in a pillar
if (point_idx < pointsNumSM[pillar_idx_inBlock]) {
atomicAdd(&(pillarSumSM[pillar_idx_inBlock].x), pillarSM[pillar_idx_inBlock][point_idx].x);
atomicAdd(&(pillarSumSM[pillar_idx_inBlock].y), pillarSM[pillar_idx_inBlock][point_idx].y);
atomicAdd(&(pillarSumSM[pillar_idx_inBlock].z), pillarSM[pillar_idx_inBlock][point_idx].z);
}
__syncthreads();
//feature-mean
float4 mean;
float validPoints = pointsNumSM[pillar_idx_inBlock];
mean.x = pillarSumSM[pillar_idx_inBlock].x / validPoints;
mean.y = pillarSumSM[pillar_idx_inBlock].y / validPoints;
mean.z = pillarSumSM[pillar_idx_inBlock].z / validPoints;
mean.x = pillarSM[pillar_idx_inBlock][point_idx].x - mean.x;
mean.y = pillarSM[pillar_idx_inBlock][point_idx].y - mean.y;
mean.z = pillarSM[pillar_idx_inBlock][point_idx].z - mean.z;
//calculate offset
float x_offset = voxel_x / 2 + cordsSM[pillar_idx_inBlock].w * voxel_x + range_min_x;
float y_offset = voxel_y / 2 + cordsSM[pillar_idx_inBlock].z * voxel_y + range_min_y;
float z_offset = voxel_z / 2 + cordsSM[pillar_idx_inBlock].y * voxel_z + range_min_z;
//feature-offset
float4 center;
center.x = pillarSM[pillar_idx_inBlock][point_idx].x - x_offset;
center.y = pillarSM[pillar_idx_inBlock][point_idx].y - y_offset;
center.z = pillarSM[pillar_idx_inBlock][point_idx].z - z_offset;
//store output
if (point_idx < pointsNumSM[pillar_idx_inBlock]) {
pillarOutSM[pillar_idx_inBlock][point_idx][0] = pillarSM[pillar_idx_inBlock][point_idx].x;
pillarOutSM[pillar_idx_inBlock][point_idx][1] = pillarSM[pillar_idx_inBlock][point_idx].y;
pillarOutSM[pillar_idx_inBlock][point_idx][2] = pillarSM[pillar_idx_inBlock][point_idx].z;
pillarOutSM[pillar_idx_inBlock][point_idx][3] = pillarSM[pillar_idx_inBlock][point_idx].w;
pillarOutSM[pillar_idx_inBlock][point_idx][4] = mean.x;
pillarOutSM[pillar_idx_inBlock][point_idx][5] = mean.y;
pillarOutSM[pillar_idx_inBlock][point_idx][6] = mean.z;
pillarOutSM[pillar_idx_inBlock][point_idx][7] = center.x;
pillarOutSM[pillar_idx_inBlock][point_idx][8] = center.y;
pillarOutSM[pillar_idx_inBlock][point_idx][9] = center.z;
} else {
pillarOutSM[pillar_idx_inBlock][point_idx][0] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][1] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][2] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][3] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][4] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][5] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][6] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][7] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][8] = 0;
pillarOutSM[pillar_idx_inBlock][point_idx][9] = 0;
}
__syncthreads();
//避免bank冲突,按列访问
for(int i = 0; i < FEATURES_SIZE; i ++) {
int outputSMId = pillar_idx_inBlock*WARP_SIZE*FEATURES_SIZE + i* WARP_SIZE + point_idx;
int outputId = pillar_idx*WARP_SIZE*FEATURES_SIZE + i*WARP_SIZE + point_idx;
features[outputId] = ((float*)pillarOutSM)[outputSMId] ;
}
} 关于共享内存的bank冲突,这里做一下补充说明。为了获得很高的内存带宽,共享内存在物理上被分为32个(刚好等于一个线程束中的线程数目,即内存变量wapSize的值)同样宽度的,能被同时访问的内存bank。我们可以将32个bank从0-31编号。 在每一个bank中,又可以对其中的内存地址从0开始编号。为方便起见,我们将所有bank中编号为0的内存称为第一层内存,将所有bank中编号为1的内存称为第二层内存,依此类推。
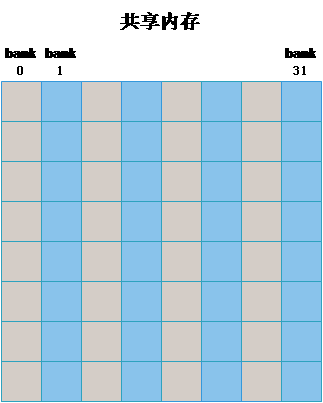
只要同一线程束内的多个线程不同时访问同一个bank中不同层的数据,该线程束对共享内存的访问就只需要一次内存事务(memory transaction)。而当同一个线程束内的多个线程试图访问同一个bank中的不同层的数据时,就会发生bank冲突。同一个线程束内对同一个bank中的n层数据同时访问将导致n次内存事物,称为发生了n路冲突。如果无视bank冲突,采取以下赋值策略,效率会受到多大的影响呢?
for (int i=0; i经过实际测算,大概会多出1.6ms左右。