车道线检测
近期阅读的几篇关于车道线检测的论文总结。
1. 任务需求分析
1.1 问题分析
针对车道线检测任务,需要明确的问题包括:
(1)如何对车道线建模,即用什么方式来表示车道线。
从应用的角度来说,最终需要的是车道线在世界坐标系下的方程。而神经网络更适合提取图像层面的特征,直接回归方程参数不是不可能,但限制太多。
由此,网络推理输出和最终结果之间存在一个Gap,需要相对复杂的后处理去解决。
(2)网络推理做到哪一步。
人在开车时观察车道线,会同时关注两方面信息:
绘制在路面上的车道线标识本身
通过车道线标识,表征的抽象的车道分隔边界线
1.2 方法概述
概括来说,基于CNN的车道线检测主流方法大致可以这么分类:
对画面上每一个像素是否属于地面标识,属于哪一类地面标识进行预测,即图像分割的思想,对全图每一个像素进行分类。典型的数据集如Apollo中的 Lane Segmentation 数据集。

对画面上每一个像素是否属于车道分界线进行预测,属于图像分割,还可以细分为前景/背景的二分类,以及判断车道线实例的多分类。典型的数据集如Tusimple和CULane。

不关心每一个像素的归属问题,而是直接提取更抽象层面的车道线属性。
方法1的推理目标最为确定,网络需要猜测的成分最少。根据获取的分割图,由后处理步骤来完成车道线信息的提取。
方法2需要网络具有一定的联想猜测能力,能够把不连续的车道线识别为连续的实体。
方法3需要网络具有最强的抽象能力,能够直接感知到车道线的空间结构。
1.3 面临挑战
针对车道线检测任务,面临的挑战主要有:
(1)车道线这种细长的形态结构,需要更加强大的高低层次特征融合,来同时获取全局的空间结构关系,和细节处的定位精度。
(2)车道线的形态有很多不确定性,比如被遮挡,磨损,以及道路变化时本身的不连续性。需要网络针对这些情况有较强的推测能力。
(3)在实际应用中,车辆稳定行驶在车道中央的工况最常见,但 车辆的偏离或换道过程才是关键工况 ,此时会产生自车所在车道的切换,车道线也会发生左/右线的切换。
据此,一些提前给车道线赋值固定序号的方法,在实际使用中是有巨大缺陷的,在换道过程中会产生歧义的情况。
这种方法在刷数据集指标的时候可能效果OK,但在应用中,从网络结构设计的角度,无法应对换道这种关键工况。
2. 论文要点解读
Paper - 1
《Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks》
论文链接
将车道线检测作为一个分割问题来处理,最后输出车道线前景和背景的2值分割图。
网络整体上使用了CNN+RNN的结构。
CNN的部分采用了常规的Encoder-Decoder结构。
在Encoder和Decoder之间插入 ConvLSTM 模块,通过 ConvLSTM 对Encoder部分提取的Feature-map进行处理,提取有用的隐含历史信息。如下图所示:
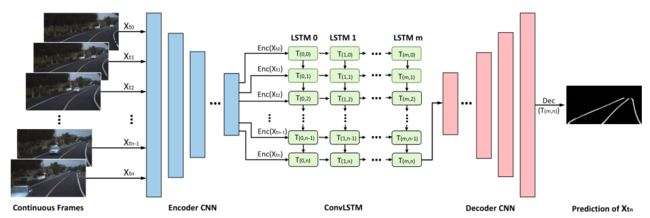
在 训练 阶段,针对Tusimple数据集,将连续5帧作为输入,并在带有标注的最后一帧计算Loss。
在 推理 阶段,连续帧图像持续输入,每一帧图像经过处理都会输出对应的推理结果。
Paper - 2
《Key Points Estimation and Point Instance Segmentation Approach for Lane Detection》
论文链接
这篇文章比较有意思,在一众图像分割路线的方法中比较特别,借鉴了目标检测的思路来解决。
将原图进行一定程度的降采样后,在获得的Feature-map上预测每一个点的结果,包括了Confidence、Offset、Feature三个输出。每一个点类似于目标检测中的Anchor概念。其中:
Confidence预测该点代表的区域是否存在车道线;
Offset预测车道线点相对Anchor中心点的偏移量;
Feature输出一个向量编码,用于区分不同车道线的点。这一点应该是借鉴了 LaneNet 这篇文章的思路。
在512x256输入的情况下,论文中尝试了64x32和32x16两种输出分辨率。

在后处理过程中,采用了一种从车道线的最近端开始逐渐向上匹配的机制,来排除一些错误点(outliers)。
Paper - 3
《Ultra Fast Structure-aware Deep Lane Detection》
论文链接
这篇文章从分类的角度来构思车道线检测这个问题。
它将问题转化为对图像中的特定行进行分类,每一个类别代表车道线所在的一个位置。
对原图进行一定降采样操作后,所获一个Feature-map,其中:
每一个channel代表一条特定的车道线;
每一行对应原图中某几行组成的一个Row anchor;
Row中的每一个col,对应了原图中某几列的位置,另外有一个额外的col,代表了无车道线,即背景类。

在Loss函数方面,除了分类Loss以外,还定义了一个structure-loss,主要从两方面进行衡量:
**similarity loss:**考虑同一个channel中,相邻row的分类结果的连续性
shape loss:考虑连续多个点的斜率变化趋势
这个方法能够达到很快的推理速度,因此以 Ultra Fast 命名,但我以为存在如下几个问题:
在目标构建过程中,需要提前定义好每一条车道线属于哪个channel,因此对于换道过程中处于临界状态的车道线的归属问题具有歧义性,原论文中也没有提及这方面的解决办法。此外这种方式对于可检测的车道线最大数量也有限制,即提前设定的channel数。这个问题目前没有想到特别合适的解决办法。
分类的目标是一个one-hot编码的多选一,而车道线在近处是有一定宽度的,很有可能会覆盖多个col。这个问题理论上可以通过label-smooth来缓解,或者引入类似CenterNet一样的Heatmap目标。
Paper - 4
《CurveLane-NAS: Unifying Lane-Sensitive Architecture Search and Adaptive Point Blending》
论文链接
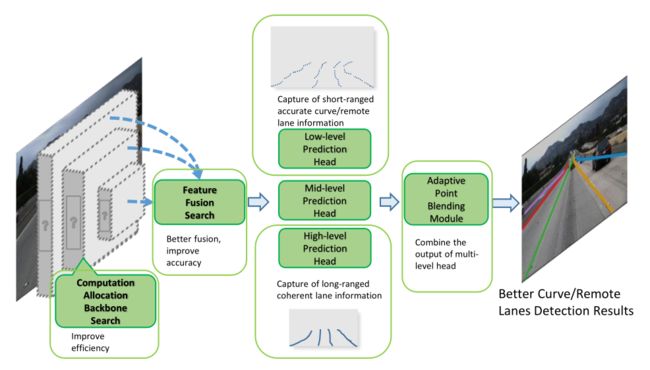
参考了 Dense Prediction Based (分割的思路)和 Proposal Based (检测的思路)两种车道线检测的框架,以后者为基础,采用了NAS的方法,获得了一个更适合车道线检测任务的网络结构。
网络整体上可以分为以下几个部分:
特征提取及多尺度融合,在这两个阶段均引入了NAS的方法;
多尺度检测输出,以充分获取大范围内的全局结构特征,以及小范围内的精确定位
结果融合,采用一种叫做 Adaptive Point Blending Search 的方法(类似于一种NMS方法,将低层输出中位置精度回归较高的点逐步向高层输出替换,得到最后融合优化的车道线点输出)
而这篇文章还有一个 重大的贡献 ,即发布了一个大规模的车道线检测公开数据集 Curvelanes 。在此之前,只有Tusimple和CULane,Curvelanes的体量跟CULane相当,场景更加多样化。
Paper - 5
《Heatmap-based Vanishing Point boosts Lane Detection》
论文链接
网络整体上同样采用Encoder-Decoder结构,在车道线的预测Head以外,增加了一个Head,用于消失点的预测。
将消失点看做一种特殊的关键点,采用Heatmap的方式来预测。
通过这种方式,将消失点预测任务作为一种限制和引导因素,来优化车道线检测的结果。
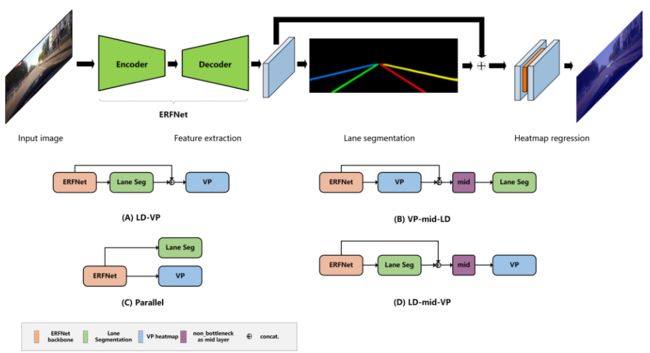
车道线检测和消失点检测,两个任务有多种组合方式。
经试验,LD-mid-VP的结构,在CULane数据集上能够获得最好的结果。这种结构将特征提取阶段的输出和车道线预测的输出进行信息融合,再经过一些卷积层(mid部分)的处理后,输出消失点的预测结果。
从直观层面理解,人根据视觉判断消失点,也是根据车道线的位置关系,来推测消失点位置,具有一定的因果关系。因此把消失点预测任务后置,反过来也能够促进前端的车道线预测任务更好地收敛。
在此之前,还有一篇较有代表性的文章 VPGNet ,同样是通过消失点来引导网络学习,以期获得更好的收敛效果。不同的是VPGNet是通过四象限分割的方式来定义消失点位置,感觉不如Heatmap的方式更加符合直觉。
Paper - 6
《Lane Detection Model Based on Spatio-Temporal Network with Double ConvGRUs》
论文链接
整体思路与 第一篇论文 比较类似。都是Encoder+RNN+Decoder。结构如下图所示:
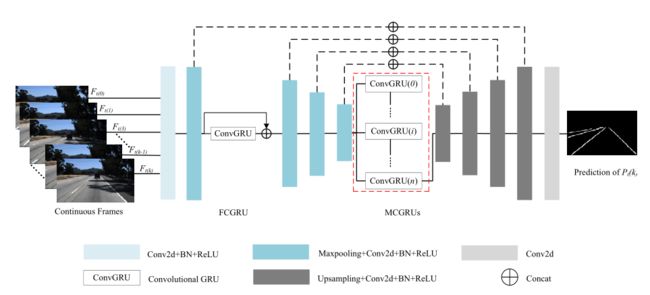
不同的是,它的RNN部分由两个ConvGRU组成, Front-ConvGRU 和 Middle-ConvGRUs 。
Front-ConvGRU 位于Encoder部分的第二个卷积模块之后。理论依据主要是认为视觉感知和记忆之间存在联系,因此在低层特征中引入RNN模块。
此处有一点没有理解,从文中给出的结构图看,FCGRU这个模块,并没有在前后帧的时序上产生联系(对比MCGRU的画法可以发现),连接关系类似一个普通的Conv模块,只有一个输入,一个输出。
我不确定是示意图画的问题,还是此处的GRU模块有什么特殊的用法。

按论文的说法,经FCGRU处理前后的Feature-map可视化结果。车道线特征更加明显突出。
Middle-ConvGRUs 位于Encoder和Decoder部分之间,作用主要是用于提取连续帧输入的时序关联信息,与前文所说的 ConvLSTM 是类似的。
Paper - 7
《RESA: Recurrent Feature-Shift Aggregator for Lane Detection》
论文链接
网络同样基于Encoder-Decoder结构进行改进。在Encoder和Decoder部分之间,插入 RESA 模块,增强空间结构信息在全局的传播能力。结构如下图所示:
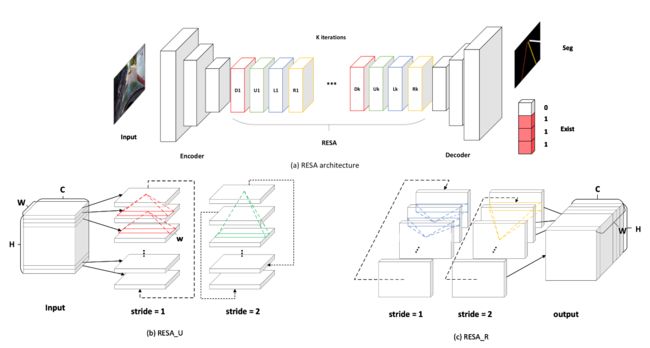
同样的思路可以回溯到 SCNN这篇文章 。
同样是通过在Encoder-Decoder之间插入一个 SCNN 模块,来增强网络感知空间结构信息的能力。
按论文的说法, RESA 模块比 SCNN 模块的效率要高,时间复杂度与尺度的关系为 l o g 2 L log_2L log2L。
3. 总结
总结近期车道线检测领域的论文,有如下一些发展趋势:
车道线检测的应用场景具有很明显的时序信息特征,为了利用到时序信息,通常采用 Encoder-RNN-Decoder 这样的网络架构,利用RNN模块,对Encoder提取的Features进行进一步加工,提取连续帧带来的历史信息。
可以参考人的视觉暂留现象,人在开车时观察车道线,能够自觉把虚线识别为一条空间上连续的线,也是利用了前后的时序信息。
在全图分割的思路以外,出现了一些以目标检测或目标分类的思路来处理车道线检测问题的方法。
除了车道线检测本身,通过增加一些额外的相关任务,引导网络更好地学习,来获得更好的效果。
不用整张图片处理,因为车道线相比背景很少,整张图片处理起来会后很多没用的信息,因此按行处理不仅降低了计算量,效果也不错。
一般的Encoder-Decoder结构提取的是局部特征,能够提取全局特征将会增加车道线推理准确度。