多兴趣召回SINE:Sparse-Interest Network for Sequential Recommendation
今天分享一篇阿里2021年发表的推荐论文 Sparse-Interest Network for Sequential Recommendation
召回阶段负责从海量的item中选出用户感兴趣的候选集,在这一过程中表征用户的兴趣是非常重要的, 一般的做法是为每个用户生成1个embedding。然而实际中用户的兴趣是多种多样的。此外,单一的embedding是由用户历史行为累计的向量,占比大的兴趣占优势,占比小的兴趣不占优势,即存在累计效应。因此考虑将用户的兴趣表示为多个向量,每个向量代表一个兴趣。
尽管如此,最近关于多兴趣embedding的工作通常考虑通过聚类发现的少量概念(concept,可以理解为用户兴趣),这可能无法与实际系统中的大量item类别相提并论。也就是说,我们对序列进行聚类,形成多个类目,在分别对几个类别进行建模,这就建模出多个兴趣向量。比如说我们把序列中的裙子,衣服,裤子分成三类,然后显式的去建模这三个子序列,形成多个兴趣向量用于表示user。但是用户的多兴趣这个概念是难以定义的,也就是说我们对于seq如何划分成概念上的兴趣比较难;尽管可以将item的类别信息用作概念,但在许多情况下,由于注释噪声,这种类型的辅助信息在实践中可能不可用或不可靠(人工标注可能会引入error)。其次,如何定义概念上的兴趣K这个超参也是个复杂的问题。
因此,提出了SINE(稀疏兴趣网络), SINE的创新点在于:
- 稀疏兴趣提取模块(sparse-interest module)从大量概念池中自适应地推断用户的交互兴趣并输出多个兴趣embedding。
- 兴趣聚合模块(interest aggregation module)Given multiple interest embeddings, we develop an interest aggregation module to actively predict the user’s current intention and then use it to explicitly model multiple interests for next-item prediction. The aggregation module enables dynamically predicting the user’s next intention, which helps to capture multi-interests for top-N item recommendation explicitly.
引言
对于多兴趣emb存在的挑战:
然而,从行业级数据中的用户行为序列中有效地提取多个嵌入向量存在一些挑战。首先,项目在实际系统中通常在概念上没有很好地聚类。尽管可以将项目的类别信息用作概念,但在许多情况下,由于注释噪声在实践中,此类辅助信息可能不可用或不可靠。第二个挑战是从大型概念池中自适应地为用户推断出一组稀疏的感兴趣的概念。推理过程包括一个选择操作,这是一个离散的优化问题,很难进行端到端的训练。第三,给定多个兴趣嵌入向量,我们需要确定哪个兴趣可能被激活以进行下一项预测。在训练过程中,下一个预测项目可以用作激活首选意图的标签,但推理阶段没有这样的标签。该模型必须自适应地预测用户的下一个意图。
SINE 可以学习大量的兴趣组,并以端到端的方式捕捉用户的多种意图。

输入:用户行为序列。
自适应地从兴趣池中激活兴趣,同时输出多兴趣emb。然后,兴趣聚合模块通过主动预测用户的下一个意图来帮助选择最喜欢的兴趣进行下一个item推荐。
主要创新点:
- 大规模item聚类和稀疏兴趣提取联合集成到推荐系统中。对大量的item在细粒度上进行聚类是一项重要的任务。一个人通常只与一组稀疏的概念进行交互,需要准确从全量概念原型中抽出一部分。
聚合模块能够动态预测用户的下一个意图,这有助于显式地捕获 Top-N 项目推荐的多兴趣。
The state-of-art sequence encoders for capturing a user’s mul- tiple intentions can be summarized into two categories. 捕获用户多个意图的最先进的序列编码器可以概括为两类
multi-head self-attention Transformer。 但这两种都是有限制的,例如 一个item属于多个类别。
概念激活:

旨在从一个包含L概念的大型概念池 隐概念嵌入矩阵
3.2.1 概念激活
首先通过一个自注意力机制有选择地聚合输入序列中的特征信息:


a 得到的是用户行为序列中每个 item 的权重。


内积操作得到 su.
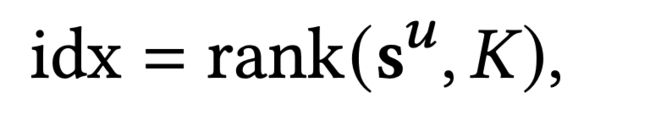
得到的是最大的 k 个。
先要找到和用户最相关的k个兴趣
3.2.2 Intention assignment 意向分配

3.2.3 注意力权重
此外通过引入另一种注意力来计算 [公式] 位置的item对预测用户接下来行为意图的重要性:
3.2.4 兴趣向量聚合
至此,我们已经介绍了稀疏兴趣网络的全过程。 给定用户的行为序列,我们首先从概念池中激活他/她喜欢的概念原型。
然后执行意图分配以估计与输入序列中的每个项目相关的用户意图。 之后,应用自注意力层来计算所有项目的注意力权重,以进行下一个项目的预测。 最后,根据公式 5,通过加权和生成用户的多个兴趣嵌入。
3.3 Interest Aggregation Module
3.4 Model Optimization
3.5 Connections with Existing Models
待完成:
- 序列化推荐 sequential recommendation