OpenPPL PPQ量化(2):离线静态量化源码剖析
目录
模型支持
量化onnx原生模型:quantize_onnx_model
输入输出
执行流程
ONNX格式解析
后记

模型支持
openppl支持了三种模型:onnx、caffe、pytorch,其中pytorch和caffe是通过quantize_torch_model和quantize_caffe_model,先将模型转换成onnx模型,再调用quantize_onnx_model来实现量化的。
@ empty_ppq_cache
def quantize_torch_model(
model: torch.nn.Module,
calib_dataloader: DataLoader,
calib_steps: int,
input_shape: List[int],
platform: TargetPlatform,
input_dtype: torch.dtype = torch.float,
setting: QuantizationSetting = None,
collate_fn: Callable = None,
inputs: List[Any] = None,
do_quantize: bool = True,
onnx_export_file: str = 'onnx.model',
device: str = 'cuda',
verbose: int = 0,
) -> BaseGraph:
# dump pytorch model to onnx
dump_torch_to_onnx(model=model, onnx_export_file=onnx_export_file,
input_shape=input_shape, input_dtype=input_dtype,
inputs=inputs, device=device)
return quantize_onnx_model(onnx_import_file=onnx_export_file,
calib_dataloader=calib_dataloader, calib_steps=calib_steps, collate_fn=collate_fn,
input_shape=input_shape, input_dtype=input_dtype, inputs=inputs, setting=setting,
platform=platform, device=device, verbose=verbose, do_quantize=do_quantize)@ empty_ppq_cache
def quantize_caffe_model(
caffe_proto_file: str,
caffe_model_file: str,
calib_dataloader: DataLoader,
calib_steps: int,
input_shape: List[int],
platform: TargetPlatform,
input_dtype: torch.dtype = torch.float,
setting: QuantizationSetting = None,
collate_fn: Callable = None,
inputs: List[Any] = None,
do_quantize: bool = True,
device: str = 'cuda',
verbose: int = 0,
) -> BaseGraph:
if do_quantize:
if calib_dataloader is None or calib_steps is None:
raise TypeError('Quantization needs a valid calib_dataloader and calib_steps setting.')
if setting is None:
setting = QuantizationSettingFactory.default_setting()
ppq_ir = load_graph(file_path=caffe_proto_file,
caffemodel_path=caffe_model_file,
from_framework=NetworkFramework.CAFFE)
ppq_ir = format_graph(ppq_ir)
ppq_ir = dispatch_graph(ppq_ir, platform,
dispatcher=setting.dispatcher,
dispatching_table=setting.dispatching_table)
if inputs is None:
dummy_input = torch.zeros(size=input_shape, device=device, dtype=input_dtype)
else: dummy_input = inputs
quantizer = PFL.Quantizer(platform=platform, graph=ppq_ir)
executor = TorchExecutor(graph=quantizer._graph, device=device)
executor.tracing_operation_meta(inputs=dummy_input)
if do_quantize:
quantizer.quantize(
inputs=dummy_input,
calib_dataloader=calib_dataloader,
executor=executor,
setting=setting,
calib_steps=calib_steps,
collate_fn=collate_fn
)
if verbose: quantizer.report()
return quantizer._graph
else:
return quantizer._graph所以我们接下来看看quantize_onnx_model是怎么实现的。
量化onnx原生模型:quantize_onnx_model
输入输出
onnx_import_file (str): 被量化的 onnx 模型文件路径 onnx model location
calib_dataloader (DataLoader): 校准数据集 calibration data loader
calib_steps (int): 校准步数 calibration steps
collate_fn (Callable): 校准数据的预处理函数 batch collate func for preprocessing
input_shape (List[int]): 模型输入尺寸,用于执行 jit.trace,对于动态尺寸的模型,输入一个模型可接受的尺寸即可。
如果模型存在多个输入,则需要使用 inputs 变量进行传参,此项设置为 None
a list of ints indicating size of input, for multiple inputs, please use
keyword arg inputs for direct parameter passing and this should be set to None
input_dtype (torch.dtype): 模型输入数据类型,如果模型存在多个输入,则需要使用 inputs 变量进行传参,此项设置为 None
the torch datatype of input, for multiple inputs, please use keyword arg inputs
for direct parameter passing and this should be set to None
inputs (List[Any], optional): 对于存在多个输入的模型,在Inputs中直接指定一个输入List,从而完成模型的tracing。
for multiple inputs, please give the specified inputs directly in the form of
a list of arrays
setting (OptimSetting): 量化配置信息,用于配置量化的各项参数,设置为 None 时加载默认参数。
Quantization setting, default setting will be used when set None
do_quantize (Bool, optional): 是否执行量化 whether to quantize the model, defaults to True.
platform (TargetPlatform, optional): 量化的目标平台 target backend platform, defaults to TargetPlatform.DSP_INT8.
device (str, optional): 量化过程的执行设备 execution device, defaults to 'cuda'.
verbose (int, optional): 是否打印详细信息 whether to print details, defaults to 0.执行流程
我们首先要加载计算图:
ppq_ir = load_onnx_graph(onnx_import_file=onnx_import_file)
此处加载的计算图是原始的,尚未被调度,也就是所有算子都被认为是可量化的。
然后我们需要执行图的切分与调度,不同算子会被执行不同的调度:
ppq_ir = dispatch_graph(graph=ppq_ir, platform=platform,
dispatcher=setting.dispatcher,
dispatching_table=setting.dispatching_table)所有对计算图执行的操作,最后都会返回BaseGraph类,这个类是PPQ内部专门为模型量化准备的计算图,除了保存一般计算图的必要信息之外,还存储了所有量化信息。后面在写博客解析这个量化计算图的设计。
然后根据指定的平台platform确定指定的量化类:
quantizer = PFL.Quantizer(platform, ppq_ir)
所有的平台类型写在ppq/lib/common.py文件中:
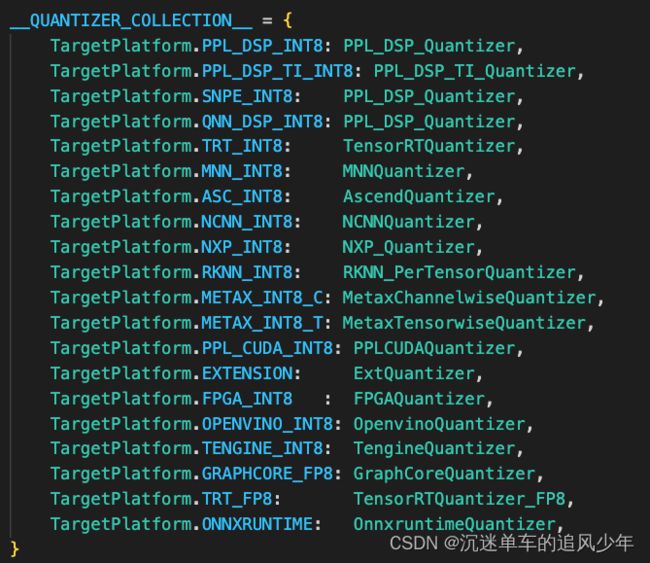
这些具体量化方法写在quantizer文件夹中,传入量化计算图是因为这些量化类需要计算图进行初始化:
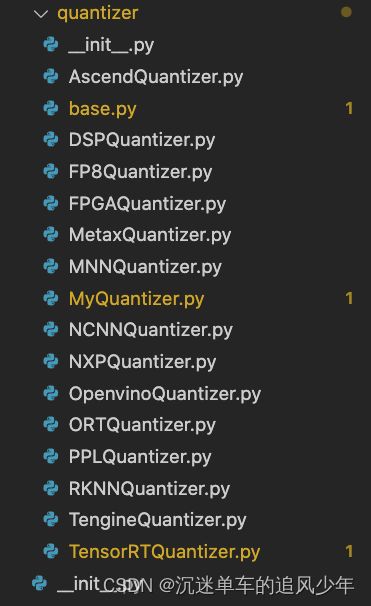
因为我们已经初始化了量化类,所以后面表示计算图不再使用ppq_ir,直接用quantizer._graph表示。我们继续要用量化图初始化执行引擎,这个引擎TorchExecutor能执行onnx的推理,由于不同平台的推理细节是不同的,所以这里的实现有点复杂,大致的流程如下:

详细的解析后面专门再写博客讲吧。
好了继续回到我们的主逻辑中,最后一步是执行量化,返回量化后的量化计算图,搞定~
if do_quantize:
quantizer.quantize(
inputs=dummy_input,
calib_dataloader=calib_dataloader,
executor=executor,
setting=setting,
calib_steps=calib_steps,
collate_fn=collate_fn
)
if verbose: quantizer.report()
return quantizer._graph
else:
executor = TorchExecutor(graph=ppq_ir, device=device)
executor.tracing_operation_meta(inputs=最后注意这里如果不需要执行量化,我们用没有原始载入的计算图执行一遍推理,然后返回即可。
ONNX格式解析
如果不了解ONNX格式,前面从ONNX解析出计算图部分会比较难理解,有一篇写的很棒的博客,我摘抄了一部分帮助理解:ONNX学习笔记 - 知乎
这一节我们来分析一下ONNX的组织格式,上面提到ONNX中最核心的部分就是onnx.proto(https://github.com/onnx/onnx/blob/master/onnx/onnx.proto)这个文件了,它定义了ONNX这个数据协议的规则和一些其它信息。现在是2021年1月,这个文件有700多行,我们没有必要把这个文件里面的每一行都贴出来,我们只要搞清楚里面的核心部分即可。在这个文件里面以message关键字开头的对象是我们需要关心的。我们列一下最核心的几个对象并解释一下它们之间的关系。
ModelProtoGraphProtoNodeProtoValueInfoProtoTensorProtoAttributeProto
当我们加载了一个ONNX之后,我们获得的就是一个ModelProto,它包含了一些版本信息,生产者信息和一个GraphProto。在GraphProto里面又包含了四个repeated数组,它们分别是node(NodeProto类型),input(ValueInfoProto类型),output(ValueInfoProto类型)和initializer(TensorProto类型),其中node中存放了模型中所有的计算节点,input存放了模型的输入节点,output存放了模型中所有的输出节点,initializer存放了模型的所有权重参数。
我们知道要完整的表达一个神经网络,不仅仅要知道网络的各个节点信息,还要知道它们的拓扑关系。这个拓扑关系在ONNX中是如何表示的呢?ONNX的每个计算节点都会有input和output两个数组,这两个数组是string类型,通过input和output的指向关系,我们就可以利用上述信息快速构建出一个深度学习模型的拓扑图。这里要注意一下,GraphProto中的input数组不仅包含我们一般理解中的图片输入的那个节点,还包含了模型中所有的权重。例如,Conv层里面的W权重实体是保存在initializer中的,那么相应的会有一个同名的输入在input中,其背后的逻辑应该是把权重也看成模型的输入,并通过initializer中的权重实体来对这个输入做初始化,即一个赋值的过程。
最后,每个计算节点中还包含了一个AttributeProto数组,用来描述该节点的属性,比如Conv节点或者说卷积层的属性包含group,pad,strides等等,每一个计算节点的属性,输入输出信息都详细记录在https://github.com/onnx/onnx/blob/master/docs/Operators.md。
后记
关于如何做量化校准?如果使用校准数据?如何配置量化设置?具体的量化过程是如何?如何选择需要量化的算子?……
还有很多问题没有讲明白,这个系列很长,我们一一探索!!