论文阅读3:INT8量化训练
一、Title
Quantization and Training of Neural Networks for Efficient
Integer-Arithmetic-Only Inference
二、Abstract&Instruction
why?
自从AlexNet问世以来,CNN的模型大小不断增大,模型大小动辄数百MB,计算量也令人畏惧,使得这些模型不再适合在移动端部署。因此,业界亟需对模型大小进行压缩,同时还需兼顾模型的准确率。
how?
针对上述情况,作者提出了一种使用8bit的量化模型,这个模型在训练时仍然使用浮点数对权重进行更新,但是在模型推断时,则只有8位整型的计算,而在某些硬件上,8位整型计算要比浮点数计算高效得多。
result?
作者用MobileNet进行了实验,分别在数据集ImageNet和COCO上进行了测试,结果是在精度损失不大的情况下,神经网络的参数数目和计算延迟有了显著的改善。
三、Methods
1. Quantized Inference & train
作者提出的量化模型在推断时仅仅使用8位整数,而在训练时则使用浮点数,我们用下标q表示量化后的整数,用r表示量化前的浮点数。量化过程是如下的一个简单的仿射变换
r = S ( q − Z ) r=S(q-Z) r=S(q−Z)
其中,q是量化后的8位整数,r是浮点数,S、Z是量化过程用到的参数,S是浮点数,Z是8位整型,事实上,Z是浮点数0量化之后对应的值,而偏置则被量化为32位整型。
在量化模型中,权重或者激活被量化后,还需要反量化为浮点数,然后输入卷积或者全连接运算单元进行计算,如下图

设反量化之前的输入为uint8型的q1,q2,经过反量化后,分别变成了浮点数r1,r2,,r1,r2再进行卷积或者全连接计算,输出浮点型r3,然后通过激活函数,这里是ReLu,最后又被重新量化为uint8的q3。
下面我们推到q1,q2如何计算得到q3,我们以矩阵乘法为例,首先,我们有
r 1 = S 1 ( q 1 − Z 1 ) r_1=S_1(q_1-Z_1) r1=S1(q1−Z1)
r 2 = S 2 ( q 2 − Z 2 ) r_2=S_2(q_2-Z_2) r2=S2(q2−Z2)
r 3 = S 3 ( q 3 − Z 3 ) r_3=S_3(q_3-Z_3) r3=S3(q3−Z3)
由r1,r2得到r3,有
r 3 i , j = ∑ k = 1 N r 1 i , k ∗ r 2 k , j r_3^{i,j}=\sum_{k=1}^Nr_{1}^{i,k}*r_2^{k,j} r3i,j=∑k=1Nr1i,k∗r2k,j
即
S 3 ( q 3 i , j − Z 3 ) = ∑ k = 1 N S 1 ( q 1 i , k − Z 1 ) ∗ S 2 ( q 2 k , j − Z 2 ) = S 1 S 2 ∑ k = 1 N ( q 1 i , k − Z 1 ) ( q 2 k , j − Z 2 ) = S 1 S 2 ( N Z 1 Z 2 − Z 1 ∑ k = 1 N q 2 k , j − Z 2 ∑ k = 1 N q 1 i , k + ∑ k = 1 N q 1 i , k q 2 k , j ) / / 若 考 虑 b i a s , 则 还 需 加 上 ( b r S 1 S 2 + 0 ) S_3(q_3^{i,j}-Z_3)=\sum_{k=1}^NS_1(q_1^{i,k}-Z_1)*S_2(q_2^{k,j}-Z_2)\\=S_1S_2\sum_{k=1}^N(q_1^{i,k}-Z_1)(q_2^{k,j}-Z_2)\\=S_1S_2(NZ_1Z_2-Z_1\sum_{k=1}^Nq_2^{k,j}-Z_2\sum_{k=1}^Nq_1^{i,k}+\sum_{k=1}^Nq_1^{i,k}q_2^{k,j})//若考虑bias,则还需加上(\dfrac{b_r}{S_1S_2}+0) S3(q3i,j−Z3)=∑k=1NS1(q1i,k−Z1)∗S2(q2k,j−Z2)=S1S2∑k=1N(q1i,k−Z1)(q2k,j−Z2)=S1S2(NZ1Z2−Z1∑k=1Nq2k,j−Z2∑k=1Nq1i,k+∑k=1Nq1i,kq2k,j)//若考虑bias,则还需加上(S1S2br+0)
得到r3之后,就是ReLU激活函数
q 3 i , j = R e L U ( r 3 i , j ) S 3 + Z 3 = R e L U ( r 3 i , j ) S 3 = R e L U ( r 3 i , j S 3 ) = R e L U ( r 3 i , j S 3 + Z 3 ) q_3^{i,j}=\dfrac{ReLU(r_3^{i,j})}{S_3}+Z_3=\dfrac{ReLU(r_3^{i,j})}{S_3}=ReLU(\dfrac{r_3^{i,j}}{S_3})=ReLU(\dfrac{r_3^{i,j}}{S_3}+Z_3) q3i,j=S3ReLU(r3i,j)+Z3=S3ReLU(r3i,j)=ReLU(S3r3i,j)=ReLU(S3r3i,j+Z3)
第二个等号是因为 Z 3 = 0 Z_3=0 Z3=0,第二个等号是因为 S 3 > 0 S_3>0 S3>0。
进一步整理得到
q 3 i , j = R e L U ( Z 3 + S 1 S 2 S 3 ( N Z 1 Z 2 − Z 1 ∑ k = 1 N q 2 k , j − Z 2 ∑ k = 1 N q 1 i , k + ∑ k = 1 N q 1 i , k q 2 k , j + b r S 1 S 2 + 0 ) ) q_3^{i,j}=ReLU(Z_3+\dfrac{S_1S_2}{S_3}(NZ_1Z_2-Z_1\sum_{k=1}^Nq_2^{k,j}-Z_2\sum_{k=1}^Nq_1^{i,k}+\sum_{k=1}^Nq_1^{i,k}q_2^{k,j}+\dfrac{b_r}{S_1S_2}+0)) q3i,j=ReLU(Z3+S3S1S2(NZ1Z2−Z1∑k=1Nq2k,j−Z2∑k=1Nq1i,k+∑k=1Nq1i,kq2k,j+S1S2br+0))
可以看到, b r 最 终 被 量 化 为 b r S 3 + 0 , 符 合 我 们 的 预 期 b_r最终被量化为\dfrac{b_r}{S_3}+0,符合我们的预期 br最终被量化为S3br+0,符合我们的预期
这里,唯一的浮点数就是 M : = S 1 S 2 S 3 M:=\dfrac{S_1S_2}{S_3} M:=S3S1S2,我们可以通过用一个32位定点数来表示该浮点数以避免进行浮点运算。整个得到q3的计算过程中,我们用int32来表示加减乘的结果,以防止溢出,计算完成后,右边应该是一个int32类型的整型,因此,我们需要将它进行截断,即
u i n t 8 = c l a m p ( 0 , 255 , i n t 32 ) uint_8=clamp(0,255,int_{32}) uint8=clamp(0,255,int32)
同时我们注意到,模型结构中对卷积或全连接层的输出直接进行了ReLu操作,输出浮点数的最小值为0,从而其对应的量化后的 Z 3 = 0 Z_3=0 Z3=0,因此,先量化再ReLU操作和先ReLU再量化是等效的,也就是说,上边从int32到uint8的截断过程实际上也恰好实现了ReLU激活函数。最终得到的uint8的q3就是我们要求的r3对应的量化值。
2. Training with simulated quantization
上边说到参数被量化之后,还需要反量化为浮点数再送入卷积或者全连接层,这种量化-反量化的操作实际上模拟了量化过程中产生的误差。
量化
s ( a , b , n ) = b − a n − 1 q = r o u n d ( c l a m p ( a , b , r ) − a s ) s(a,b,n)=\dfrac{b-a}{n-1}\\q=round(\dfrac{clamp(a,b,r)-a}{s}) s(a,b,n)=n−1b−aq=round(sclamp(a,b,r)−a)
反量化
r ′ = q ∗ s ( a , b , n ) + a r'=q*s(a,b,n)+a r′=q∗s(a,b,n)+a
上述式子中,a,b分别是浮点数的最小最大值,而n则是量化的范围(本文中是2^8=256)
权重和激活在a,b的具体确定方法上稍有不同。
权重
对权重,我们简单的将a设置为min(w),b设置为max(w),并且如果使用的是int8量化而不是uint8,那么将量化后的权重截断为[-127,127]。
激活
对激活,同样需要统计最小值和最大值,并且作者还采用了exponential moving averages (EMA)方法更新S和Z。
下图是量化训练的流程图

3. Batch normalization folding
对于那些使用BatchNormalization的神经网络模型来说,情况更加复杂,为了提高推理时模型的效率,作者将BN层和CONV层进行了融合,同时,为了提高模型的精确度,也需要在训练时模拟这种融合,这样,在模型推断时,只需要对融合后的新权重进行量化即可,即

这里,EMA是指数滑动平均的意思, γ \gamma γ是BN层的伸缩量, ε \varepsilon ε则是一个很小的数,仅仅是为了结果稳定而设置。

上图是没有量化时含BN层的训练图,输入和权重先进行卷积运算,然后根据卷积运算的输出进行统计,确定 μ \mu μ和 σ \sigma σ,然后对输入进行变换
γ ( x − μ ) / σ + β \gamma(x-\mu)/\sigma+\beta γ(x−μ)/σ+β
最后通过激活函数。
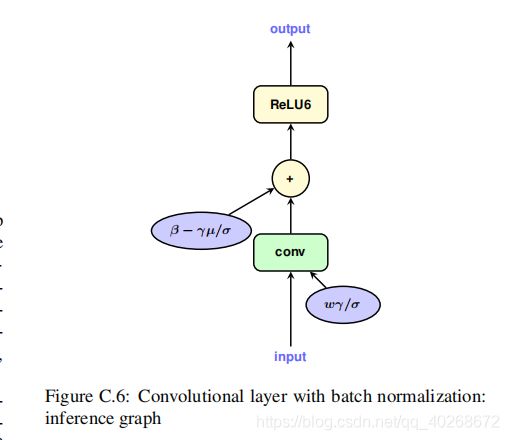
上图则是相应的推理图
w f o l d = w ∗ γ / σ w_{fold}=w*\gamma/\sigma wfold=w∗γ/σ
b f o l d = β − γ ∗ μ / σ b_{fold}=\beta-\gamma*\mu/\sigma bfold=β−γ∗μ/σ
所谓的BN融合,就是通过上述两个式子实现的。
接下来来看包含量化之后的情况。

如上图所示,这是量化之后BN融合的训练图,输入和权重进行卷积(此次卷积仅仅是为了统计),得出 μ 和 σ \mu和\sigma μ和σ之后,对卷积层之前的W和b进行BN融合变换, W f o l d W_{fold} Wfold伪量化之后和输入进行卷积,加上偏置项 b f o l d b_{fold} bfold,最后通过激活函数并伪量化输出。这里还需要强调的是,伪量化=量化+反量化,因此伪量化之后的输出还是float。
四、Experiment
作者一共进行了两组实验,第一组是在ImageNet数据集上训练的ResNets和Inception V3,第二组则是MobileNet。
1.1 ResNets

表4.1显示了ResNet不同深度下量化模型的精度损失,可以看到,8bit量化的精度损失均在2%以内。表4.2显示了不同量化模型的量化结果,可以看到,作者的量化模型精度优于其他模型,即使INQ精度和作者的差不多,但是INQ的计算性能也不如我们,因为INQ采用浮点激活。
1.2 Inception v3 on ImageNet
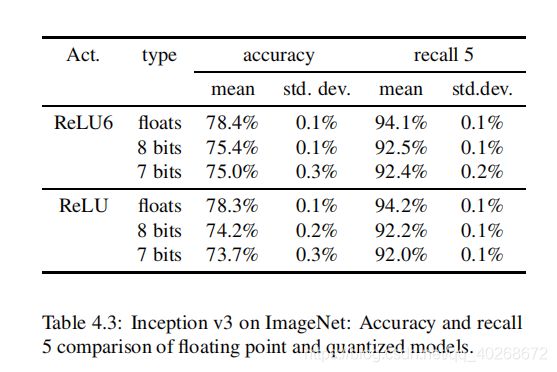
表4.3显示了7bit量化和8bit量化的差异,以及ReLU6激活函数和ReLU激活函数的差异。
从表中可以看出,7bit量化的最终准确率和8bit相差无几,而ReLU6函数的效果要好于ReLU。
2.1 MobileNet on ImageNet
作者在高通的三个处理器上进行了实验,分别是
- Snapdragon 835 LITTLE core
- Snapdragon 835 big core
3)Snapdragon 821 big core
通过改变MobileNet的 depth-multipliers (DM)和resolutions来观察实验结果。
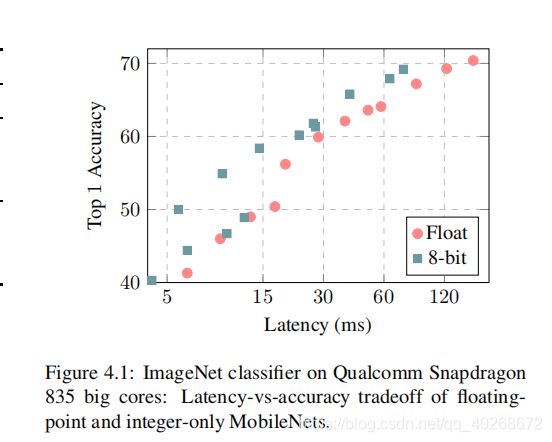
上图是在Snapdragon 835上浮点模型和8bit模型的准确率和延迟,可以看到,在相同延迟的情况下,8bit模型能达到更高的精度。
2.2 MobileNet on COCO
作者还在COCO数据集上进行了目标检测的实验,在实验前,作者对原先的网络结构进行了修改,使之大体上和MobileNet类似。下图是实验所得结果。可以看到,8bit模型在运行时间方面减少了至多50%,而精度损失只有1.8%。

2.3 MobileNet on Face detection
2.4 MobileNet on Face attributes
五、Discussion
作者提出了一个只需要依靠整型运算进行推理的神经网络量化模型,该模型通过在训练时模拟量化过程中带来的误差来提升模型的精度,除了存储空间缩小为原先的4倍外,该模型还在推理效率上有了很大提升,可以相信,这个模型再加上高效的硬件设计可以推动神经网络在计算机视觉中的应用和部署。