OpenMMlab社区开放麦<第22期:姿态估计领域的前沿进展>——笔记
姿态估计技术的发展对于行为分析、虚拟现实和自动驾驶等诸多应用都有着重要的意义。本期开放麦我们就邀请到了两位顶会顶刊论文作者和大家分享如何解决姿态估计中的前沿问题和一些新的姿态估计任务和解决方案。
姿态估计领域
什么是姿态估计
姿态估计又叫做关键点的检测。这个任务旨在预测人为定义的、具有明确语义的关键点的位置,比如说肩膀、膝盖等。

这里展示了一张图片,输入一张两个舞者的图片。然后姿态估计网络就会检测出这个人的各个关键点,比如说这个肩膀、膝盖、手臂等等。

姿态估计任务也是最近几年比较热门的一个研究领域。然后研究者们也提出了各种各样的子任务然后我们 MMpose这个框架当中也支持了很多很多的姿态估计的任务,比如说包括这种人体的关键点的检测,人脸的关键点的估计,还有这个手势的姿态估计等等。
姿态估计中应用的场景

它的应用场景其实非常的广泛,比如说在运动健身领域,这个姿态估计可以帮助人们帮助用户去判断自己的运动姿势是不是足够标准,是不是能起到锻炼效果。比如说在 VR 这种场景下,我们可以用手势的姿态估计去做手势的控制。还有像最近几年兴起的这种无人超市,可以用姿态估计的算法检测出人的购买行为。像在这种娱乐等领域,又有这种 VR 这种体感游戏等等,都是跟我们姿态估计非常相关的一些应用。
姿态估计中主要的困难与挑战

首先,是我们的人体姿态是非常多样的,这里列的这张图所示,例如在瑜伽这种很多很困难的很罕见的场景中,估计其实一直是我们的一个比较重大的难点。第二个,是在这种多人的场景下,挡问题是尤其是这种遮非常常见的。像这种人与人之间的遮挡,或者是人在比如侧身的时候,他一半的身子就会被遮挡,像这种互遮挡和自遮挡都会给我们的姿态估计提出比较严峻的挑战。第三个,像第三张图片里边还会有这种尺寸不一的情况,有一些比较近的人,她的尺度可能比较大。然后像离得远的人,她的尺度比较小。同时这个同一个人他的各个部位的尺度可能也不一样。比如说这个人的躯干它的尺度相对较大。然后人的面部表情这种关键点,它的尺度较小。而这种尺度较小的关点又要求它比较能够精确地定位。所以这个尺寸不一的问题也是一个比较困难的问题。最后,在实际应用当中,我们的姿态估计模型往往要部署在手机智能相机、 AI 传感器这种较低算力的场景下,那么就会对我们的模型的速度具有比较高的要求。
今天的分享也会围绕这些挑战来出发。那么就首先进入我们第一篇工作的分享,这篇工作是我们在 ECCV 2022 刚刚发表的一篇工作,叫 Pose Trans 然后给大家起一个比较好听的中文名字,让数据集中的人体动起来。然后这个工作我们其实提出了一个比较简单有效的数据增强的算法,来能够帮助姿态估计的精度提升。PoseTrans: A Simple Yet Effective Pose Transformation Augmentation for Human Pose Estimation
Pose Trans
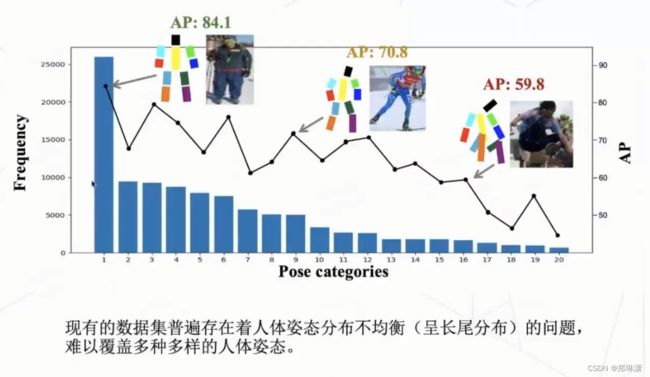
首先是研究的动机,把现有的 coco 数据集做了一个姿态的聚类。下面这张图就展示了一个聚类的效果,其中,横轴就是我们聚成了 20 个类别。这个柱状图展示了我们每个类别它的频率。也就是它的这个姿态的数量。这个折线图展示了每一个类别它的一个预测精度。
其实我们会发现大量的姿势其实都集中在一些头部类上,比如这种站立的姿姿势,在这种姿势的精度也会非常的高,那可能有 80 多。然后像这些在尾部类的姿态,它们在数据集中的占比相对较小,然后它们的精度也比较低。总而言之,在这些数据集中其实是普遍存在着人体姿态分布的不均衡的问题或者叫做长尾的问题,就很难去覆盖多种多样的人体姿态。
为了解决这个问题,产生了一个直观的想法就是能不能去生成出来这种更多丰富的这种罕见的姿势,我们把这个数据的分布调整一下,能让它更加的均衡,这样就能够解决这些罕见姿势的预测问题。这也就是我们这个工作的一个出发点。我们的这个工作主要包括两个模块,下面先分别介绍两个模块,然后再介绍整体的一个算法流程。
1、PCM人体姿势聚类模块

这个姿势聚类其实非常简单,一共就分为三步。
第一步,就是归一化,会对所有的训练样本(根据人体检测框)进行人体姿态的一个规划。
第二步,把这个归一化后的人体关键点的向量去拟合一个高斯混合模型。这样做姿态的聚类,我们会把它聚类成 20 类,这里就会自然地聚类成这种站立或者侧身或者蹲着的这种不同的姿势。
第三步,有了这样拟合好的高斯混合模型之后,就可以拿它去做预测。我们给定一个输入的图片,就能预测出它是属于哪一个类别,同时能够知道它归属于各个类别的一个高斯分量的概率。
2、PPM姿势变换模块
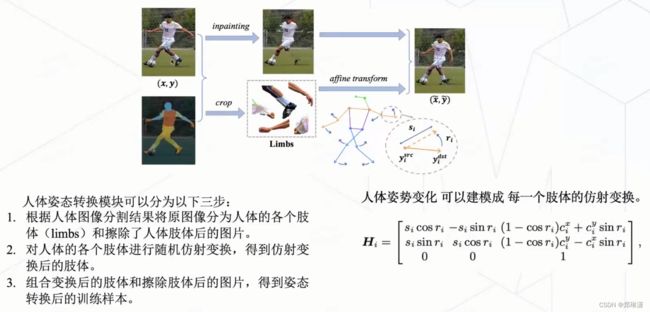
给定一张原图+姿势的分割结果,我们去生成一张新的姿势的一张图片。
具体做法:
首先会根据这个人体图像的分割结果,将原图像分为人体的各个肢体(limbs) 还有就是擦除了人的肢体的一个躯干的图片。
接着把这个人体姿态的变化建模成了每一个肢体的仿射变换,然后把每一个肢体做随机仿射变换之后再重新和这张擦除掉肢体的这个躯干图片做一个组合。就得到了我们一个新的图片。
这张新的图片就是相比于之前的这个原图,就是会动一动这个胳膊,动一动腿。就产生了新这个一个新的姿势。
3、Pose Trans框架

生成data imitation的过程:
1、就是给定一张原图之后,我们会对它做human parsing得到每一个肢体的分割结果。我们有了这个分割结果,再加上原图,就可以对这个肢体做姿态的变换(PTM)。
2、姿态变换之后有一些变换的肢体其实不符合人的人的自然的骨架的形式。这些不符合自然骨架的图像或者是生成的这个图像质量比较差,那这些就是不合格的一些图片,我们就会把它删掉。
3、对于这些合格的图片,我们可能会产生多种多样的姿势。就会形成一个Candidate Pose Pool,这个Pose Pool里就可能有一些候选的生成的结果。接下来我们会对这个候选的结果去判断它们的罕见程度。(这一步骤使用的就是PCM模块)
4、使用PCM模块后,把它聚成若干类,比如这个例子里,会把它聚成了三类,这个 A 类是站立的肢体,然后 B 类是侧身的,C 类是坐着的。
这张图在经过我们的聚类模块之后,它就会得到这样一个聚类结果,它以 0.3 的概率属于这个 A 类,然后 0.4 的概率属于这个 B 类,0.3的概率属于这个 C 类。我们发现在这三张图当中,这一类是相对来说最罕见的,因为它的这个 C 类这个罕见肢体的概率比较高。这样的话我们就会选择这个比较罕见的一个肢体作为我们的训练样本。
姿态变换效果图:
可视化效果对比: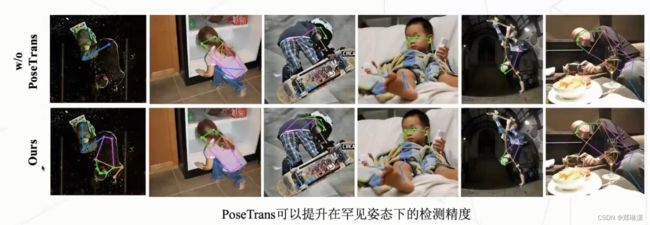
实验结果:
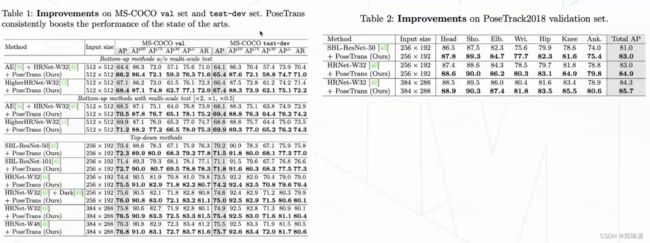
与其他数据增强算法、其他长尾算法对比:

接下来的要介绍的这篇工作其实是解决遮挡问题。然后这篇工作的题目叫做HDR:基于去遮挡和干扰移除的 3D 交互双手姿态估计。3D Interacting Hand Pose Estimation by Hand De-occlusion and Removal
HDR
首先它研究的动机,在这种双手交互的一个图片当中,预测出两只手的关键点的坐标。这里就有两个比较大的难点。
第一个难点是:这个左右手可能存在严重的互相遮挡,难以估计被遮挡的手的姿态。比如说下图,他的右手就被左手基本完全遮挡住了。那其实右手有很大部分其实是看不见的,预测这个看不见的区域就比较困难。
第二个难点是,左手和右手的纹理非常的相似,而且对姿态估计网络来说是有一点歧义性的。我们预测一只手的时候往往会被另一只手干扰。比如说像下图,他想预测右手的关键点,但是他有一些关键点预测到了左手上。这其实也是我们不想看到的。

为了解决这两个难点,所以这就是我们出发点,我们希望把双手的一个图片变成一张单手的图片,这样就可以利用我们现成的单手姿态估计的网络去做一个精准的估计。就能够得到一个比较准确的关联点。
算法流程
我们算法流程其实包括三个模块。分别是HASM、HDRM、SHPE。
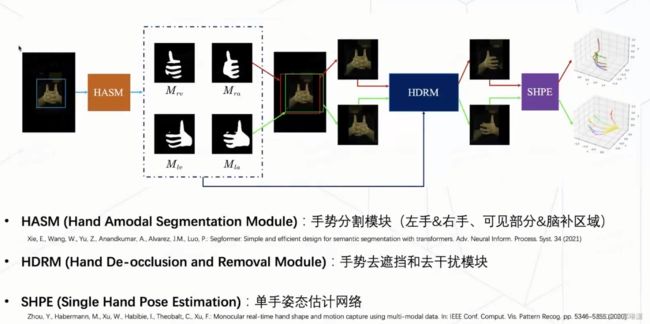
HASM(Hand amodal segmentation module)手势分割模块
它的目的就是说输入一张双手的图片,然后它去生成出来左手和右手这种可见部分的分割结果,同时还要预测出它的一个脑补结果,就是说它假设它没有被遮挡,这个手应该长成什么样子。有了这个脑补结果之后,就能够对我们的手做一个粗略的定位,就能够画一个这样的检测框。我们会分别把这个左、右手部分然后输入到 HDRM 里。
HDRM(hand De-occlusion and Removal Module)去遮挡、去干扰模块
比如说针对上图来说,经过HASM后得出的右手,输入HDRM模块,它就会只保留它的右手的一个完整的区域。同理,输入左手,它会得到一个左手的一个完整的一只左手。
SHPE(Single Hand Pose Estimation)单手姿态估计网络
使用一个现成的单手姿态估计网络就能够得到一个比较精准的 3D 人手的估计结果了。
HDRNet——去遮挡模型
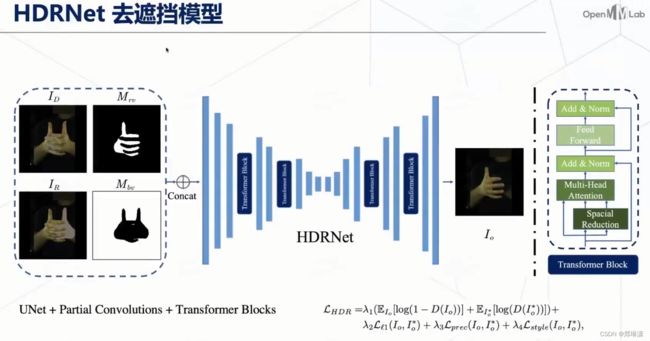
这个模块它的网络结构也比较简单,就是一个UNet+partial Convolutions,然后又加了一些 transformer 的 block 来增强我们特征提取的能力。
如上图,它的输入是有被遮挡区域的图片+它的右手有的一个可见部分的 mask +需要移除的部分的一个 mask 图片+背景区域的图片。这个网络需要学习的是用这个背景区域的信息来填充上这个需要移除的区域。同时它还要利用这个可见部分的信息,然后去填充上这个遮挡部分,就能够得到一个比较完整的这个手势的图像。
训练损失就包括一些生成式的Gan的损失还有一些图像迁移相关的一些损失。为了训练我们这一个模型,是需要一个比较大量的数据集的。
数据集的获取,其实是构造了两个虚拟合成的数据集,一个叫做AIH_Syn和一个叫做 AIH_Render。
AIH_Syn的构造方式比较简单,它其实就是把两张单手的图片,把它用贴图的方式贴在一起,这样就能得到一个双手的图片。(这个数据集能够知道每个手的mask 、每个手的可见部分的 mask 、不可见部分的 mask 以及它去遮挡之后的原图应该是长成什么样子)但是这种方式生成的这个手,它的双手是没有交互的,就它只是一个简单的贴图,这个双手之间是没有一个交互关系的。
AIH_Render的生成方式是利用人手的mesh,然后对这个 mesh 进行渲染,渲染出不同的颜色的皮肤,再把它投影到2d 的图片上,就能够得到比较真实的这个双手的姿态。同时他们的这个手势的是个手的纹理能够也能够进行变化。
在实验上, 作者一共生成了大概有 200 多万的这样一个数据集,然后用于训练我们的 HDR 网络。这里再展示一下我们的一个实验结果。

实验结果

可视化效果

ZoomNAS
这一块主要以一下三点来介绍ZoomNAS,论文ZoomNAS:Searching for Whole-body Human Pose Estimation in the Wild。
第一个,首先我们提出了一个去考虑这个人在不同part之间的一个相互关系。采用一个 zoom in的方式去提出了这套ZoomNet,去更好地去预测这个像脸和手这样子一个区域比较小的一个关键点。
第二个,我们提出了这个 zoom NAS 的方式,然后在网络结构上包括 sub-module之间的关系上进行一个搜索,并且进行sub-module 之间的这个资源的自动分配。那使得我们这个整一个就是 wholebody 的预测的效果进一步的提升。
第三个,我们提出了这个这个 coco-wholebody的这个数据集,那么使得这个研究方向可以进一步的推进。这个是我们做的一个关于wholebody的一个工作。
Whole-body Pose Estimation(两个方式来做whole body任务)
whold body任务,就是说希望去对这个人进行一个更全面一些关键点的探索。那么由于我们在实际的应用当中,其实除了一些人的整体的姿态以外,我们也希望去了解他的表情和一些手势。所以说我们这个后 body 任务,它本身就是除了关注这个 body的整个的信息以外,还会关注这个人脸、人手和人教的一些关键点。
OpenPose
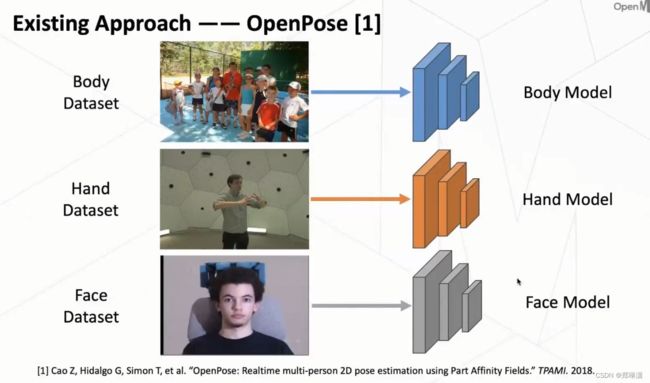
它尝试使用各种多个模型来分别解决不同的这个 part 的一个 key point 的一个问题。因为我们常规的来说,是用这个body dataset然后设计一个 body 的网络,来预测这个 body 的key point,所以它还是沿用了这套方式,就是说对于 body 在 body 数据上去进行训练,然后设计一个单独的网络,同时对于这个 hand 和 face 也是用类似的方式去做。
缺陷:这种方式其实就是把整个人体给解耦开来了,所以它没有很好地去利用一个全身的信息,那么也没有办法进行一个 end to end 的一个训练。
Single-Network

为了规避用多个模型的问题,所以设计了一个统一的模型。这个模型它能够同时地去预测这些关键点。但是由于这个没有一个whole body的一个数据集,所以它不得不在这个 body 的数据集上去训练一些 body的关键点,然后在hand和face数据上又去训练这个对应的关键点。
缺陷:它可能会引入一些不同数据集带来的一些传送,那也正是基于之前我们观察到的是这样的一个问题。我们认为它这个数据缺失是做这个任务一个很大的目前是存在的一个挑战。
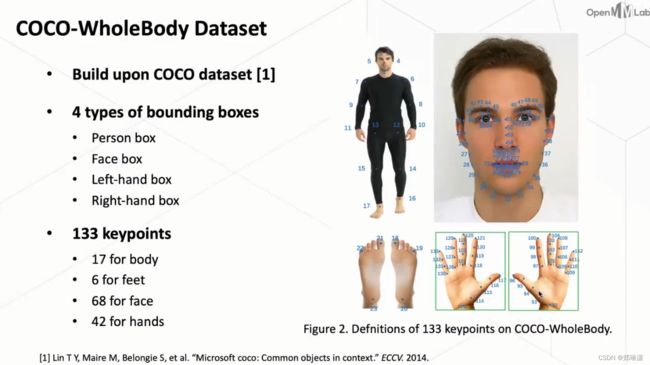
COCO-WholeBody Dataset
为了解决上面所提到的问题,作者去设计了一个叫做coco-wholebody的数据集。这个数据集是基于我们做这个多人在户外的姿态估计最流行的这个 coco 这个数据集去做的。那么 coco 这个数据集它本身是只有标注的body的key point的一些信息。

在这个数据集当中,作者又去标注了脸框和手框,其中,包括脸的key point和手的key point更多的一些信息。
从coco-wholebody这个数据集,可以看到它其实总共是标注了四种类型的这个框,包括人框、脸框还有两个手框,且用了 133 个关键点的标注。
半自动标注方式
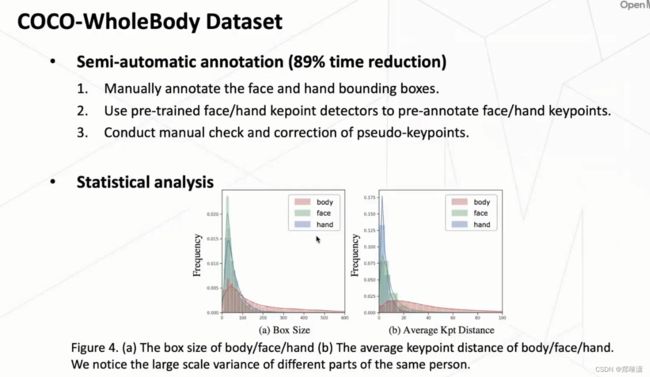
实际上去标注人脸和人手是非常困难的,因为它可能存在一些尺度比较小甚至模糊、遮挡的一些情况。所以说直接去标注这个数据其实是会耗费非常多的一个成本。
因此我们去采取了一种半自动标注的一种方式。
首先,我们先去训一个比较好的一个大模型,然后先我们人为地去标这个脸框和手框,那标框其实是相对来说标注成本比较低的。
其次,在这个框内,我们去用大模型先去做一个伪标签的一个预测,然后再做人为的修改。
那么通过这样的一个半自动的标注方式,我们这个的标注时间有将近 90% 的一个减少。同时呢我们这个也通过验证,我们也证明了我们这个标注质量还是非常的高的。
wholebody任务的特点
通过分析,发现其实wholebody这个任务它最大的一个特点是在于它不同的部分之间的差异非常大。比如说它这个 body 这个整个躯干是一个比较大的一个尺度,但是这个脸和手它其实就是一个比较小的一个尺度。
那么如何同时解决好这个不同尺寸的一个问题,那么其实是解决好这个 whole body 这个问题的一个关键。那因此基于这样的一个观察,我们去提出了这个ZoomNet的这么一套就是解决方案。
ZoomNet
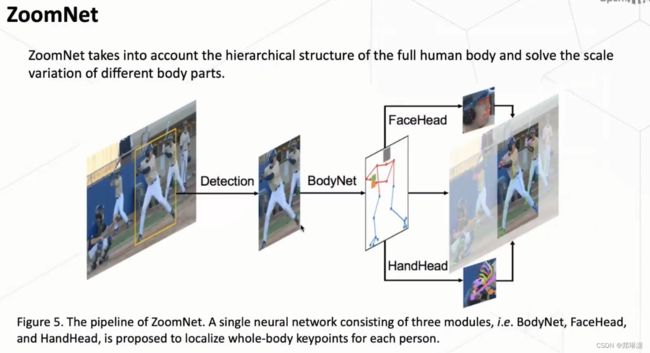
首次去使用一个 top-down 的一个模式去解决wholebody的问题。并且我们对于每一个人,去抓住它内部的一个结构信息,然后去进行一个更加精确的一个预测。
详细流程:
首先我们采取 top down 的方式,我们首先是说对于一张图里面,我们对每个人做一个检测。然后对于这检测出来这个人以后,我们对这个人进行一个单独的预测。
其次,在预测的过程当中,首先使用了一个BodyNet 网络,其中,BodyNet 一方面是预测我们这个人的整体躯干的一个关键点以及这个脚的一个关键点。另一方面我们去预测这个人的一个手框和脸框。
最后,得到了这个手框和脸框以后,我们利用两个FaceHead和HandHead去从这个BodyNet中去提取这个特征,然后进一步的对这两个部分进行一个预测。
所以其实在这两个head 进行预测过程中,我们会做一个Zoom in的操作。
就是说把这个区域给剪裁出来,然后放大到一个更高的分辨率下,那么使得就是这两个比较小的一个区域,它能够获得一个更高的精度。

所以说我们这个整体来看,BodyNet中我们使用的是一个 HRNet的一个网络,因为它也是去做 body 的 key point 预测的网络。
对于这个face和head这两个部分,我们用的这个sub-module分别用的是这个做face和hand这个比较流行的一个模型叫做HRNetV2,然后两个sub-module会从BodyNet中去提取对应区域的这个特征,再进一步的一个预测。
所以,整体来说就是利用这三个子模去组成了这个 whole-body 的key point 的一个预测方式。
ZoomNAS
思考:在这个过程中,我们还意识到一个新的问题,就是说由于这个 whole-body 这个任务它需要对于各个part 进行一个预测,那它用了三个 sub-module以后,势必带来就是说我们这个计算复杂度的一个增加。那么在实际使用的过程中,我们可能不光是关心这个精度,我们同时也会关心这个计算的效率。
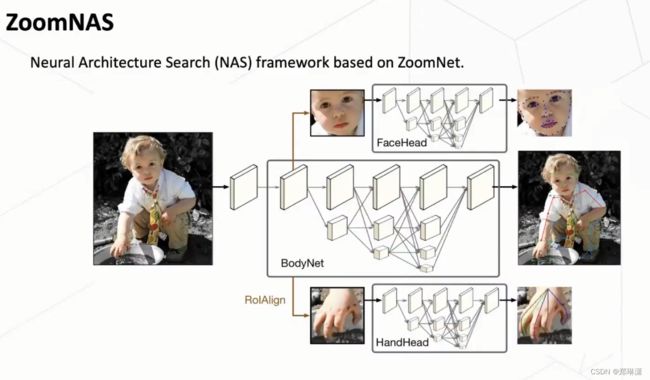
基于这样的一个思考,我们进一步提出了一套叫做 ZoomNAS 的一个框架来采用这个neural architecture search(神经结构搜索)的一个方式。来更好地获取一个精度和速度之间的一个均衡。
那么具体而言的话,这套 ZoomNAS 的框架对几个维度进行了一个搜索。首先第一个就是网络的结构。其次,第二个是说这些sub-module 之间它的一个连接关系。
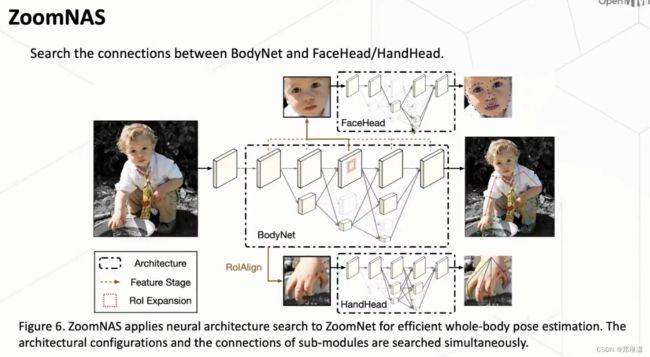
ZoomNASA中四个维度上的搜索

第一个是网络深度
第二个是我们网络的 channel 数。
第三个是我们去搜索在这个卷积中它的group number
第四个是我们去搜索每一个sub-module 的输入的resolution,包括就是输入的原图(比如 face那个分支它的特征的一个resolution)

在submodule之间,我们主要关注到两个问题。
第一个:对于我们这个 key point 预测,它其实是一个既需要 high level 信息又需要 low level 信息的一个任务。
因为这个high level信息可以帮助我们获得一些更鲁棒的效果,因为它可能对于一些遮挡的推测会更有帮助。那么low level信息它可以知道更多细节的定位的信息,所以会使得这个预测更准确。
思考时间~:那么这个 bodynet 它到底为这个 face head 它提供哪一个维度的?这个 feature 是 low level feature还是high level feature 其实是一个值得思考的问题。
第二个:ROI Expansion 我们想像搜索这么一个维度。这是什么意思呢?
就是说我们BodyNet去给这个 face 和 hand 预测了一个框,但是这个框它本身是一个预测的框,所以它其实并不是完全准确的。那么如果说这个框太小的话,它可能就没办法包含我们想预测的一些关键点,那它势必就造成了这些关键点丢失。那如果这个框太大的话,我们也知道肯定会造成这个预测精度下降,所以如何去选取这个框又是一个新的问题。
为了解决这个问题,一般我们采用了一些常规的方式,就是说我们对这个框可能做一定程度放大。那么这个放大的比例到底是多少?这个是不太确定的。所以在我们这套 NAS 框架里,我们就对网络的连接这两个维度进行了一个自动的搜索。
sub-module之间的资源分配
让这个网络它自动地去分配这个计算资源

通过我们这套搜索框架得到最终的结果是说给这个 bodynet 分配了将近 70% 的一个计算资源。
这个其实是因为我们这个 bodynet,它其实在wholebody的这个任务当中承担了非常重要的作用。一方面它预测了身体和脚的关键点,另一方面它也去给这个脸和手去预测了一个框。那么这个框它本身的话就是对于这两个就是脸和手的这个关键点,预测又非常重要。所以它这个 bodynet 它势必需要去获得一个比较准确的一个预测结果,因此它也被分配到了这个最多的一个计算量。
实验结果
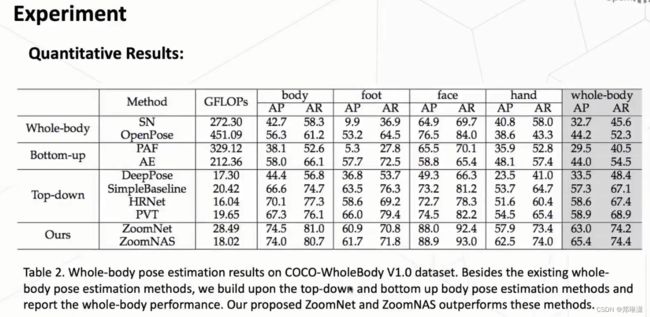

可视化的结果
Pose for Everything
它对于各种各样的类别(比如,动物、车辆等等)都能够进行一个姿态的预测。这是这篇论文的一个初衷。这一块主要以一下三点来介绍,论文地址:Pose for Everything:Towards Category-Agnostic Pose Estimation
第一个,我们提出了这个类别无关的姿态估计(CAPE)这个任务。然后这个任务它可能是重要的,但是同时也是非常困难的。
第二个,我们去提出了一套解决的方案,叫做POMNet。也构建了一个 MP-100 的数据集来进行训练和测试。
第三个,展望。这个任务其实还是有很多可以继续探究的地方,它可能一方面是有价值的,另一方面也是非常困难的。那么可能可以引发更多未来的工作来进行一个探究。
研究动机

研究动机:解决不同类别之间的一个长尾分布问题。
因为我们知道自然界中各种类别也是长尾分布的。那么像有一些类别,比如说受到关注比较少,也有可能它本身数据比较少。但是事实上对它进行姿态估计也是非常重要的。比如像我们这个姿态估计领域,跟人相关的一个姿态估计,上文已经介绍了很多。那么刚刚说的,比如对于车相关的一个姿态估计,可以用在自动驾驶上。另外,比如说可能有一些关于这个衣服的一些姿态估计,它可能可以做一些换装的任务,所以说实际大家这个需求是非常多的。
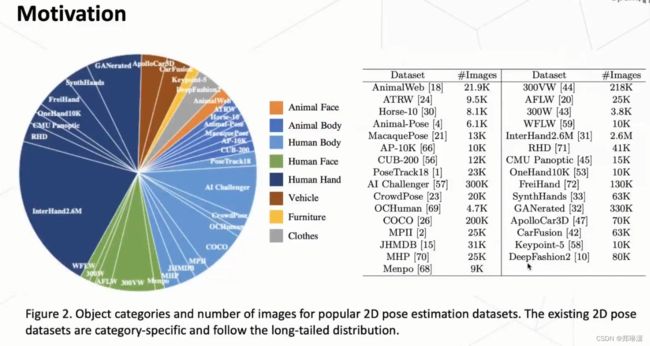
从上图中,我们可以看到human相关的姿态,估计的这个数据集是最多的。它可能是占据了绝大部分的一个数据量。那其实对于另外的一些类别,可能相对它的数据量就会比较少,甚至有一些类别大家比较关注。但是实际事实上它缺少这样的数据。
CAPE——类别无关的一个姿态估计
基于上面所说背景的一个情况,首先我们定义了一个新的任务,这个任务就是类别无关的一个姿态估计。这个任务与之前的一些人有什么差异?
可以看到我们之前是如何来做这个姿态估计,这个任务是一个怎么样的一个范式呢?
首先,比如说现在想做一个人体的一个姿态估计,那么我们就收集一个人体的姿态估计的一个数据集。然后我们去设计一个对应的模型网络,在这个数据集上进行一个训练。然后训练完以后,它就可以对这个input的图像它做一个姿态的估计。
如果我想做一个新的任务,那我势必要去收集一个新的数据集,然后重复上面的过程。那这整个过程是非常繁琐的,需要花费很多时间去收集数据集、标注数据集等等。因此,提出CAPE。

首先,我们有一个类别无关的一个姿态估计的检测器,它可以在一个多类的物体上进行一个训练。同时的话在测试阶段,我们给定任何一个类别的物体,这个类别的物体,它可能是一个新类,它从来没有在这个训练类训训练中见过。(比如说这个椅子,它可能在训练类别中根本就没有椅子。那么给定任何一种新类以及它对应的这个关键点定义,就说我要预测这些关键点。那么它对于其他的椅子,它就可以去预测一个相应的 key point 一个结果。)那这是我们想做的一个任务的设计。那基于这个任务的话,其实过往的这个姿态估计的这个方式它已经都失效了,因为他们之前都是认为这个是用大量的数据,学一个 回归的一个结果。
POMNet
为了做CAPE这个任务,作者设计了一套新的范式,叫做Pose Matching Network(POMNet)。
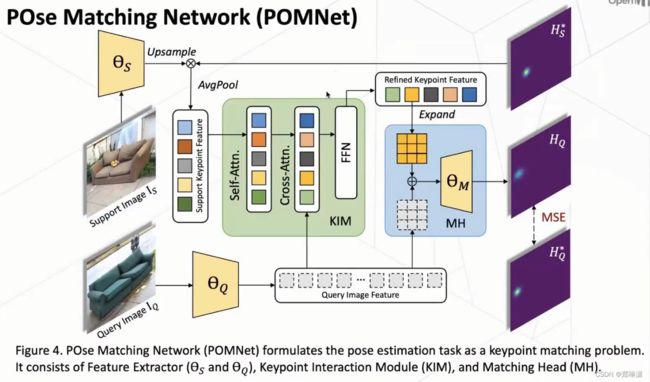 具体而言的话,就是利用一张给定的一个参考的图像,然后以及它上面给定的关键点的定义,利用这两个信息来提取这个关键点的一些特征,然后再拿这个关键点特征去和我们真正要去预测的这个图去做一些匹配,在各个位置上做匹配。如果这个最相近的那个位置,我们就认为它可能是这一个关键点的一个位置。那么大,这是我们整体的一个思路。
具体而言的话,就是利用一张给定的一个参考的图像,然后以及它上面给定的关键点的定义,利用这两个信息来提取这个关键点的一些特征,然后再拿这个关键点特征去和我们真正要去预测的这个图去做一些匹配,在各个位置上做匹配。如果这个最相近的那个位置,我们就认为它可能是这一个关键点的一个位置。那么大,这是我们整体的一个思路。
整个网络由三个部分构成:1、Feature Extractor 2、
Feature Extractor

对于support image:
首先利用一个特征提取去提取它一个全图的特帧。然后我们再利用这个对应的一个关键点的一个定义,然后把这个表征成这个heatmap的一个形式。然后把这个全图的一个特征和这个heatmap去做一个 pixel-wise的相乘,然后再利用一个average pooling来获取这一个关键点的一个特征。
对于query image:
利用另外一个特征提取器来提取这张 query image 的这个全图的特征。在这样做了以后,我们如果直接去对两者进行匹配的话,其实还存在很多问题。那么为此的话我们涉及了一个KIM叫做 keypoint interaction module,只有一个关键点的交互的一个模网络,一个模块来进一步的去 refined这个 key point 的这个特征。
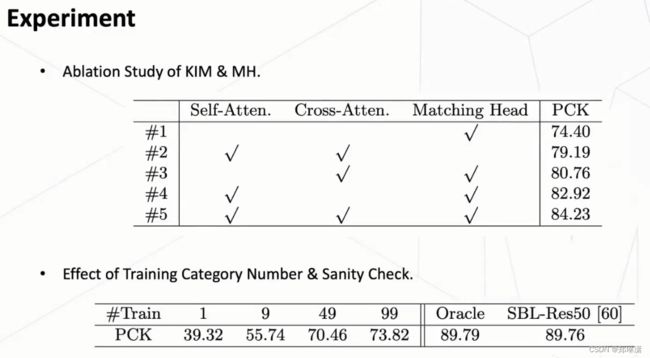
KIM和MH
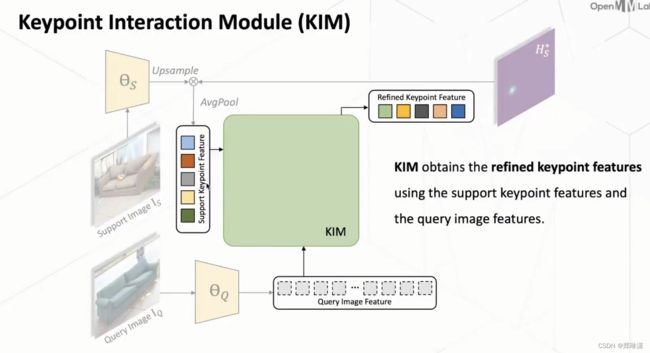
第一步:
首先第一点就是我们意识到现在有一个问题是说,我们现在这个每一个的keypoint特征它其实是独立提取到的。那么这样带来的问题就是说,它其实这些关键点它本身是都是一个物体中的关键点,所以它们其实本身本质上它是有一些联系的。但是如果它们都是单独提取的话,它其实是去忽略了这些隐藏的、物体结构的一些信息。
那么因此的话我们首先第一步我们用一个 self-attention 的一个方式,然后对这些关键点进行了一个交互,这样子的话它就可以去学习到这个关键点之间的一个相互关系,然后也学习到这个物体一个隐藏的结构特征。
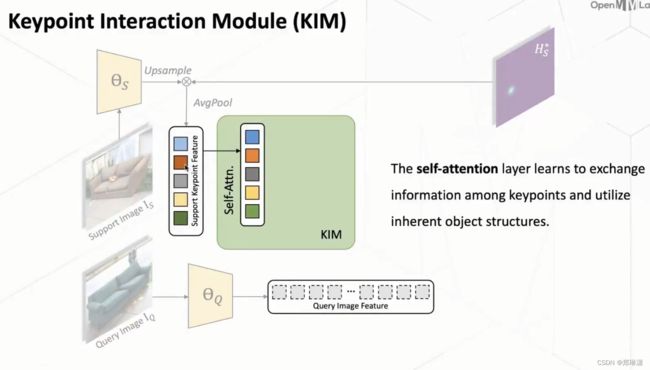
第二步:
对于 support image 的这个 feature 和这个 query image feature 它是单独提取的,所以它们这个 feature 之间可能存在一个没对齐的一个情况,那么它在做 matching 的时候势必会出现一些问题。
因此,我们又使用了这个 cross-attention的一个方式,把这个 keypoint feature 和这个 query image feature 去做一个交互,这样使得两者的 feature 去做一个对齐。也就是通过这样的方式,我们这个KIM能够把这个keypoint feature 提到一个更好的形式。
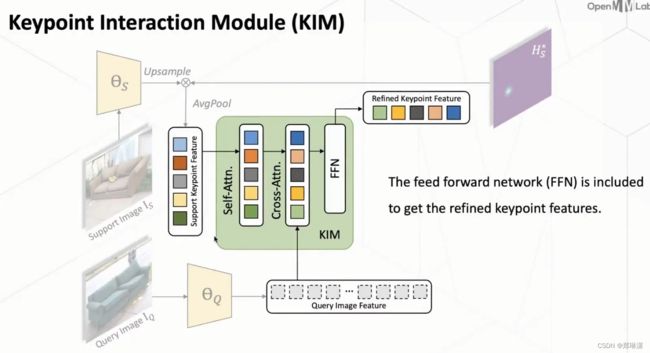
第三步:
在获得了这个 keypoint feature 和这个 query image feature 之后,我们再使用一个 matching head 去预测当前 query image 的一个head map。

第四步:
具体而言的话就是我们首先对于每一个 keypoint 的这个 feature 和这个 query image feature 我们都把它这个refined到同一个维度。那么在在这样之后,我们再把它就是 concat(这里也不确定。。在图中用红框标起来) 起来,然后再利用一个 decoder 去预测这个 heat map 。那么这个 decoder 它就是是由卷积和反卷积来组成的。
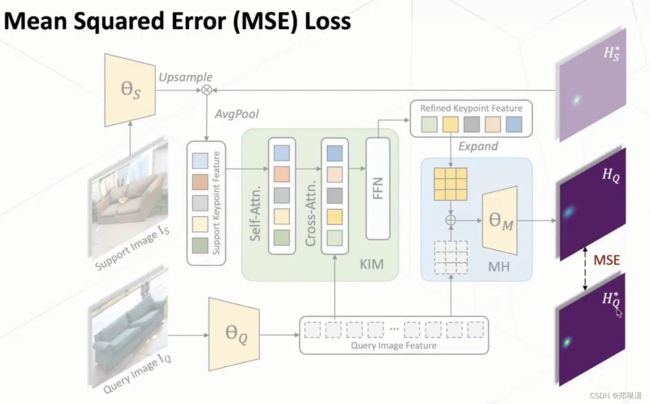
MSE Loss
在训练阶段,会采用一个 MSE loss,利用query image的head map去进行一个监督,然后使得我们这个网络进行一个end to end的训练。
在测试阶段,会利用这个 support image 和它这个关键点的定义,然后以及这个 query image 去预测在当前给定的keypoint的定义下,在这样 query image 上去预测它这个对应的一些 key point 的位置。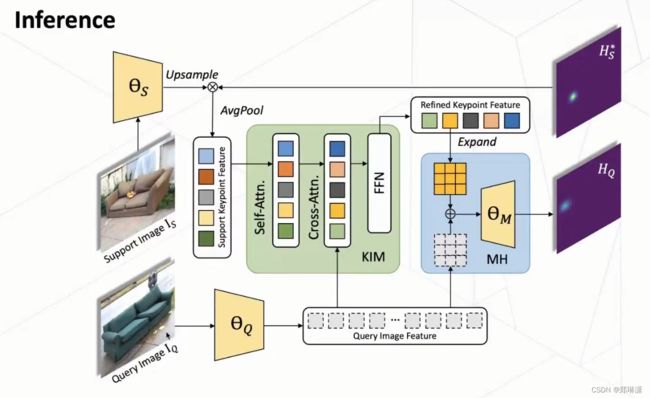
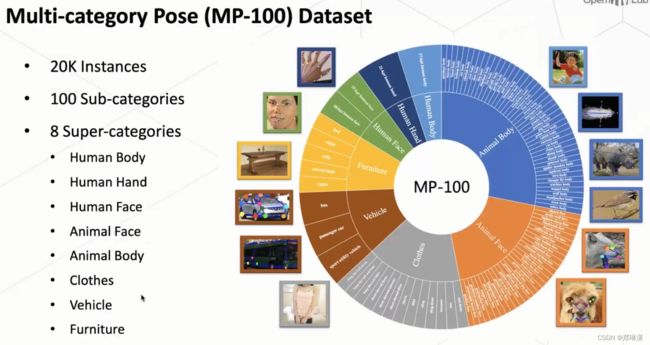
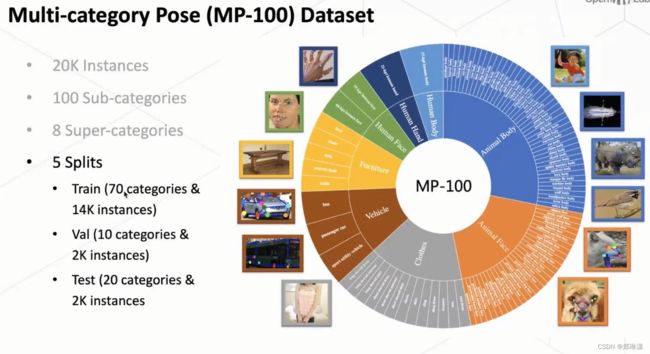
MP-100数据集

包含多种类别物体的一个姿态估计的一个数据集。我们叫 MP-100,然后这个 MP-100 我们总共是包含了 20k 的一个数据,然后包含 100 类的这个物体,其中包含这个八大类。八大类现在就是可能大家比较关注的一些比较 popular 的一个类别。但同时因为我们是 target 去作为姿态类别无关的一个姿态,估计所以说它其实也可以泛化到这个更更多的类别上去做。
八大类:
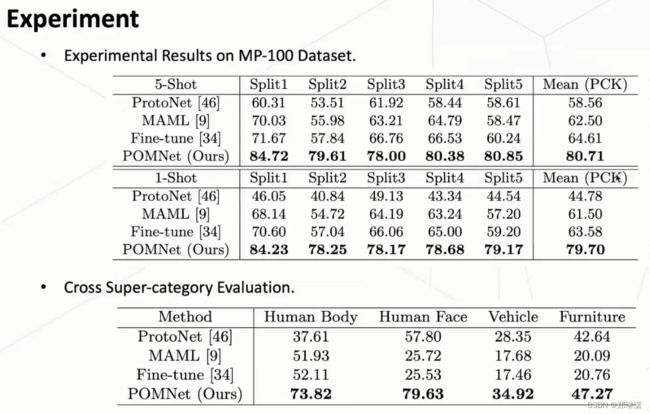
实验结果
可视化结果
展望

我们认为这个新提出的这个类别无关的姿态,估计这个任务其实可能是有很大的一个应用场景,一个应用前景的。
今天的开放麦笔记到这里结束啦~~~Thanks♪(・ω・)ノ
本笔记来自第22期 @OpenMMLab 社区开放麦
为了方便大家交流,我们创建了OpenMMLab计算机视觉微信交流群,欢迎大家扫码加入和大佬们一对一讨论吧~
