线性回归——加州房价预测
1. 数据预处理
#导入所需的库
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge, LinearRegression ,Lasso
from sklearn.model_selection import train_test_split as TTS
from sklearn.datasets import fetch_california_housing as fch
import matplotlib.pyplot as plt
#数据预处理
housevalue = fch()
X = pd.DataFrame(housevalue.data)
y = housevalue.target
X.columns = ["住户收入中位数","房屋使用年代中位数","平均房间数目"
,"平均卧室数目","街区人口","平均入住率","街区的纬度","街区的经度"]
X.head()
Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)
#恢复索引
for i in [Xtrain,Xtest]:
i.index = range(i.shape[0])
1.1 使用线性回归训练数据集
from sklearn.metrics import mean_squared_error as MSE
reg = LinearRegression().fit(Xtrain,Ytrain)
yhat = reg.predict(Xtest)
print('训练集的均方误差:{}'.format( MSE(yhat,Ytest)))
print('训练集的拟合优度:{}'.format(reg.score(Xtrain,Ytrain)))
print('测试集的拟合优度:{}'.format(reg.score(Xtest,Ytest)))
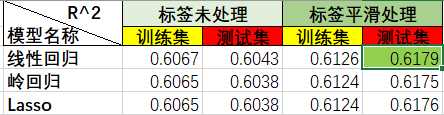
训练集的均方误差:0.5309012639324571
训练集的拟合优度:0.6067440341875014
测试集的拟合优度:0.6043668160178817
1.2 使用岭回归训练数据集
from sklearn.linear_model import RidgeCV
alphas = np.arange(1,100,1)
Ridge_ = RidgeCV(alphas= alphas,cv = 5).fit(Xtrain, Ytrain)
print('训练集的拟合优度:{}'.format(Ridge_.score(Xtrain,Ytrain)))
print('测试集的拟合优度:{}'.format(Ridge_.score(Xtest,Ytest)))
print('岭回归的最佳参数取值:{}'.format(Ridge_.alpha_))
训练集的拟合优度:0.6065484332609066
测试集的拟合优度:0.6038138173821119
岭回归的最佳参数取值:71
1.3 使用Lasso回归训练数据集
from sklearn.linear_model import LassoCV
alpharange = np.logspace(-10,-2,200,base = 10)
Lasso_ = LassoCV(alphas = alpharange , cv = 5 ).fit(Xtrain,Ytrain)
print('训练集的拟合优度:{}'.format(Lasso_.score(Xtrain,Ytrain)))
print('测试集的拟合优度:{}'.format(Lasso_.score(Xtest,Ytest)))
print('Lasso的最佳参数取值:{}'.format(Lasso_.alpha_))
训练集的拟合优度:0.606583409665469
测试集的拟合优度:0.6038982670571436
Lasso的最佳参数取值:0.0020729217795953697
2. 线性优化 尝试对标签Y进行平滑处理
y_log=np.log(y)
x_train,x_test,y_train_log,y_test_log = TTS(X,y_log,test_size = 0.3,random_state = 420)
for i in [x_train,x_test]:
i.index = range(i.shape[0])
2.1 使用线性回归训练数据集
reg = LinearRegression().fit(x_train,y_train_log)
print('训练集的拟合优度:{}'.format(reg.score(x_train,y_train_log)))
print('测试集的拟合优度:{}'.format(reg.score(x_test,y_test_log)))
训练集的拟合优度:0.6125701741509962
测试集的拟合优度:0.617943317073625
2.2 使用岭回归训练数据集
from sklearn.linear_model import RidgeCV
alphas = np.arange(1,100,1)
Ridge_ = RidgeCV(alphas= alphas,cv = 5).fit(x_train, y_train_log)
print('训练集的拟合优度:{}'.format(Ridge_.score(x_train,y_train_log)))
print('测试集的拟合优度:{}'.format(Ridge_.score(x_test,y_test_log)))
print('岭回归的最佳参数取值:{}'.format(Ridge_.alpha_))
训练集的拟合优度:0.6123854582097952
测试集的拟合优度:0.6174800899951471
岭回归的最佳参数取值:86
2.3 使用Lasso回归训练数据集
from sklearn.linear_model import LassoCV
alpharange = np.logspace(-10,-2,200,base = 10)
Lasso_ = LassoCV(alphas = alpharange , cv = 5 ).fit(x_train,y_train_log)
print('训练集的拟合优度:{}'.format(Lasso_.score(x_train,y_train_log)))
print('测试集的拟合优度:{}'.format(Lasso_.score(x_test,y_test_log)))
print('Lasso的最佳参数取值:{}'.format(Lasso_.alpha_))
训练集的拟合优度:0.6123911271099716
测试集的拟合优度:0.6176512725565488
Lasso的最佳参数取值:0.0010843659686896108
3.尝试其他回归模型进行预测
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
from xgboost import XGBRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import AdaBoostRegressor
models=[KNeighborsRegressor()
,SVR()
,DecisionTreeRegressor()
,XGBRegressor(objective ='reg:squarederror')
,RandomForestRegressor()
,AdaBoostRegressor()]
models_str=[ 'KNNRegressor'
,'SVR'
,'DecisionTree'
,'XGBoost'
,'RandomForest'
,'AdaBoost']
for name,model in zip(models_str,models):
print('开始训练模型:'+name)
model=model #建立模型
model.fit(Xtrain,Ytrain)
Ypred=model.predict(Xtest)
score=model.score(Xtest,Ytest)
print(name +' 得分:'+str(score))
开始训练模型:KNNRegressor
KNNRegressor 得分:0.1546025334615646
开始训练模型:SVR
SVR 得分:0.09407556998797517
开始训练模型:DecisionTree
DecisionTree 得分:0.5929621533188016
开始训练模型:XGBoost
XGBoost 得分:0.7835016279408904
开始训练模型:RandomForest
RandomForest 得分:0.7816564717222622
开始训练模型:AdaBoost
AdaBoost 得分:0.3711725603283339
结论:线性回归的拟合优度R^2 的最佳取值为0.6179,岭回归和lasso只是处理回归问题上的多重共线性的缺陷而成立,在加州房价回归预测数据中并没得到较好优化;相对的,在其他的预测模型比较中(未调参情况下),XGBoost的回归拟合程度最好,拟合优度R^2取值达到0.7835.