基于CNN的音乐流派分类
文章目录
- 写在前面
- 正文开始
-
- 梅尔频谱图
- 收集和预处理数据
- CNN是怎么做到的?
- 更深入的观察
-
- 蓝调还是爵士?
- 雷鬼还是嘻哈?
- 这是摇滚吗?
- 这告诉我们什么?
- 一个自然的问题
写在前面
笔者的上一篇翻译笔记:《librosa | 梅尔谱图最通俗的解释》。呈接上一篇笔记:在对梅尔谱图有了一个大致的了解后,来看看作者Leland Roberts是怎么用CNN实现音乐流派分类的吧!
依旧是有条件的话建议阅读原文~
正文开始
原文:《Musical Genre Classification with Convolutional Neural Networks》
作者:Leland Roberts

作为音乐和数据的爱好者,将两者结合起来的想法听起来很诱人。Spotify和Shazam等创新公司已经能够以聪明的方式利用音乐数据,为用户提供惊人的服务!我想尝试使用音频数据,并尝试构建一个可以按流派自动对歌曲进行分类的模型。我的项目的代码可以在github找到:lelandroberts97/Musical_Genre_Classification
自动流派分类算法可以大大提高AllMusic等音乐数据库的效率。它还可以帮助Spotify和Pandora等公司使用的音乐推荐系统和播放列表生成器。如果您喜欢音乐和数据,这也是一个非常有趣的问题!
此问题有两个主要挑战:
- 音乐流派的定义很松散。非常之多,以至于人们经常为一首歌的流派争论不休。
- 从可喂入模型的音频数据中提取
差异化特征是一项不简单的任务。
第一个问题我们无法控制。这是音乐流派的本质,也是一种限制。第二个问题在音乐信息检索(MIR)领域得到了深入研究,MIR致力于从音频信号中提取有用信息的任务。
如果你花时间真正思考一下,这是一个难题!我们如何将气压中的振动转化为我们可以从中获得见解的信息?

我花了很多时间研究这个问题。为了建立一个可以按流派对歌曲进行分类的模型,我需要找到好的特征。一个不断出现的有趣特征是mel频谱图。
梅尔频谱图
mel频谱图可以被认为是音频信号的视觉表示。具体来说,它表示频率频谱如何随时间变化。这里进行一个简短的总结:
傅里叶变换是一个数学公式,允许我们将音频信号转换到频域。它给出了每个频率的振幅,我们称之为频谱。由于频率内容通常随时间而变化,因此我们对信号的重叠窗口段执行傅里叶变换,以获得随时间变化的频率频谱的视觉效果。这称为频谱图。最后,由于人类不是在线性尺度上感知频率的,我们将频率映射到mel尺度(音高的量度),这使得音高中的相等距离听起来与人耳的距离相等。我们得到的是梅尔频谱图。
最棒的是,用几行Python代码即可实现梅尔频谱图特征的提取:
import librosa
y, sr = librosa.load('./example_data/blues.00000.wav')
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
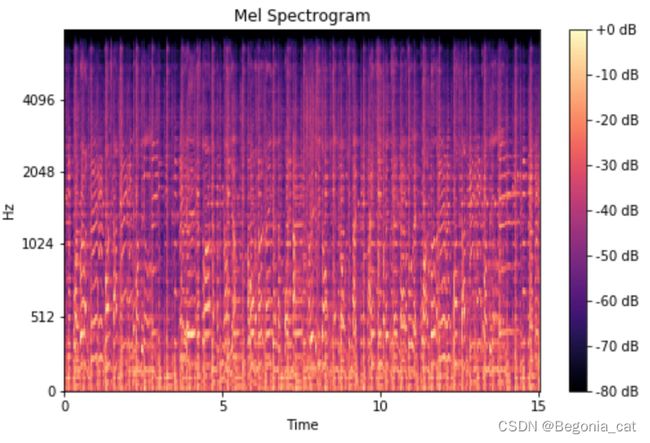
太神奇了吧?我们现在有了一种直观地表示一首歌的方法。让我们来看看不同流派歌曲的一些mel频谱图。
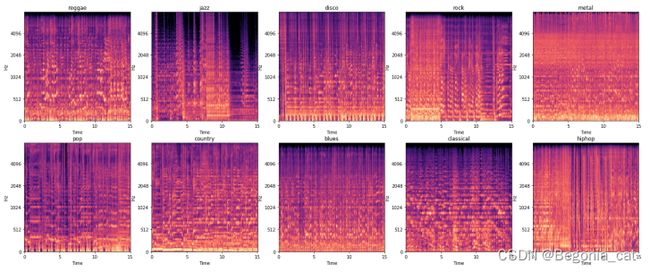
这真是太棒了!流派中的一些特殊差异在mel频谱图中得到了体现,这意味着它们可以成为出色的特征。
我们所做的基本上是将问题转化为图像分类任务。这很好,因为有一个专门为此任务制作的模型:卷积神经网络(CNN)。这就引出了我项目的主要问题:基于卷积神经网络,使用mel频谱图识别音乐流派的准确度如何?
让我们开始吧!
收集和预处理数据
我使用的数据集是GTZAN流派集合(可在http://marsyas.info/downloads/datasets.html找到)。
译者注:这个链接貌似打不开,大家可以使用其他的音乐流派数据集作为替代。
该数据集在2002年一篇关于流派分类的著名论文中被使用。该数据集包括10种不同的流派(蓝调,古典,乡村,迪斯科,嘻哈,爵士,金属,流行,雷鬼和摇滚),每种流派有100首歌曲(每个样本30秒)。由于它们都是.wav文件,因此我能够使用librosa库将它们加载到Jupyter Notebook中。
译者注:librosa也可以输入
.mp3、.flac格式的音频哦,只要在电脑上安装ffmpeg即可。详情可以在笔者关于librosa的介绍文章里找到,也可以在csdn里直接搜索ffmpeg的安装教程。
如上所示,使用librosa计算mel频谱图是相当简单的。我能够编写一个函数来计算每个音频文件的mel频谱图,并将它们存储在numpy数组中。它返回该数组以及具有相应流派标签的数组。
现在我们有了特征和目标,我们可以创建一个验证集。我选择20%用于测试。
在构建模型之前,必须执行几个步骤:
mel 频谱图的值应进行缩放,以便它们介于 0 和 1 之间,以提高计算效率。- 数据目前是
1000 行 mel 频谱图,为128 x 660。我们需要将其重塑为 1000 行 128 x 660 x1,以表示存在单个颜色通道。如果我们的图像有三个颜色通道,RGB,我们需要这个额外的维度是3。 - 目标值必须经过one-hot编码才能被喂到神经网络中。
请务必在创建验证集后完成这些步骤,以防止数据泄露。现在我们准备做一些建模!
CNN是怎么做到的?
在运行CNN之前,我想训练一个前馈神经网络(FFNN)进行比较。CNNs具有额外的层可用于边缘检测,这使得它们非常适合图像分类问题,但它们的计算成本往往比FFNN高。如果FFNN可以表现得很好,就没有必要使用CNN。由于这篇文章的主要焦点是CNN,我不会在这里详细介绍模型,但最好的FFNN模型获得了 45% 的测试分数。
正如人们所怀疑的那样,CNN的模型做得更好!最好的CNN模型(基于测试分数准确性)获得了 68% 的分数。这不是太差劲,特别是考虑到问题的难度,但它仍然不是很好。训练得分为 84%,因此模型过拟合了。这意味着它对训练数据进行了很好的调整,而不能泛化到新数据。即便如此,这确实是在学习。
我尝试了几种不同的架构来改进模型,其中大多数都达到了55%到65%的准确率,但我无法做到更好。大多数模型在大约15个epochs后变得越来越过拟合,因此增加epochs的数量似乎不是一个好的选择。
以下是最终模型结构的摘要:
- 输入层:128 x 660 个神经元(128 个 mel 尺度和 660 个时间窗口)
- 卷积层:16 个不同的 3 x 3 滤波器
- 最大池化层数:2 x 4
- 卷积层:32 个不同的 3 x 3 滤波器
- 最大池化层数:2 x 4
- 致密层:64个神经元
- 输出层:10个神经元,用于10种不同的流派
所有隐藏层都使用RELU激活函数,输出层使用softmax函数。使用分类交叉熵函数计算损失。Dropout也被用来防止过度拟合。
更深入的观察
为了更深入地了解模型发生的情况,我计算了一个混淆矩阵,以可视化模型对实际值的预测。我发现的真的很有趣!

蓝调还是爵士?
该模型几乎从未预测过蓝调,只有35%的蓝调歌曲被正确分类,但大多数错误分类是爵士乐和摇滚乐。这很有道理!爵士乐和蓝调是非常相似的音乐风格,摇滚乐深受蓝调音乐的影响,并真正从蓝调音乐中脱颖而出。
雷鬼还是嘻哈?
该模型也很难区分雷鬼和嘻哈。雷鬼音乐的错误分类中有一半是嘻哈音乐,反之亦然。同样,这是有道理的,因为雷鬼音乐严重影响了嘻哈音乐,并具有相似的特征。
这是摇滚吗?
该模型将几种流派错误地归类为摇滚,尤其是蓝调和乡村音乐。这并不奇怪,因为摇滚音乐的子流派有很多分支到其他流派。蓝调摇滚非常受欢迎,南方摇滚也有乡村影响。
这告诉我们什么?
这其实是个好消息!我们的模型遇到了与人类相同的困难。它显然正在学习音乐流派的一些区别因素,但它在与其他流派具有共同特征的流派方面遇到了麻烦。同样,这又回到了第一个问题,那就是音乐流派的本质。它们很难区分!
即便如此,我想说的是,对于计算机来说,68% 的准确率并不是那么糟糕,但我确实相信还有改进的余地。我可以自信地说,CNN比FFNN做得更好,它能够以相当高的准确性学习和预测一首歌的类型。
一个自然的问题
如果我们删除一些与其他流派具有共同特征的流派,会发生什么情况?模型的性能会更好吗?它与二元分类有什么关系?这些是一些仍在我脑海中燃烧的问题。如果您想更深入地研究这些问题,请继续关注我的下一篇文章。
未完待续…
(完)
作者的文章到这里就结束了,不过,并没有后续文章…
不过作者把音乐流派分类的代码放在了github上,感兴趣的朋友可以去试试跑一下。
这篇文章是作者2020年写的文章,当时是一名研二学生,也是一名我们音乐科技领域的同仁。读到此文,笔者有种惺惺相惜的感觉~