视觉人工智能初识 OpenMMLab
非常开心参与了这一次关于OpenMMLab公开课程的学习,通过课程的知识分享总结,我讲简述从计算机视觉的发展历程以及对于OpenMMLab简单认识。
1、20世纪50年代,主题是二维图像的分析和识别
1959年,神经生理学家David Hubel和Torsten Wiesel通过猫的视觉实验,首次发现了视觉初级皮层神经元对于移动边缘刺激敏感,发现了视功能柱结构,为视觉神经研究奠定了基础——促成了计算机视觉技术40年后的突破性发展,奠定了深度学习之后的核心准则。
1959年,Russell和他的同学研制了一台可以把图片转化为被二进制机器所理解的灰度值的仪器——这是第一台数字图像扫描仪,处理数字图像开始成为可能。
这一时期,研究的主要对象如光学字符识别、工件表面、显微图片和航空图片的分析和解释等。
2、20世纪60年代,开创了三维视觉理解为目的的研究
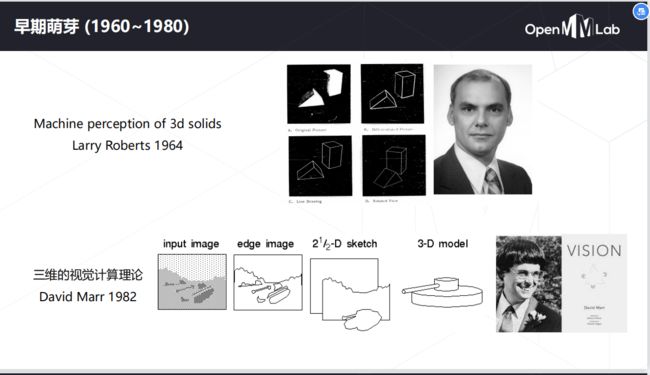
1965年, Lawrence Roberts《三维固体的机器感知》描述了从二维图片中推导三维信息的过程。——现代计算机视觉的前导之一,开创了理解三维场景为目的的计算机视觉研究。他对积木世界的创造性研究给人们带来极大的启发,之后人们开始对积木世界进行深入的研究,从边缘的检测、角点特征的提取,到线条、平面、曲线等几何要素分析,到图像明暗、纹理、运动以及成像几何等,并建立了各种数据结构和推理规则。
1966, MITAI实验室的Seymour Papert教授决定启动夏季视觉项目,并在几个月内解决机器视觉问题。Seymour和Gerald Sussman协调学生将设计一个可以自动执行背景/前景分割,并从真实世界的图像中提取非重叠物体的平台。——虽然未成功,但是计算机视觉作为一个科学领域的正式诞生的标志。
1969年秋天,贝尔实验室的两位科学家Willard S. Boyle和George E. Smith正忙于电荷耦合器件(CCD)的研发。它是一种将光子转化为电脉冲的器件,很快成为了高质量数字图像采集任务的新宠,逐渐应用于工业相机传感器,标志着计算机视觉走上应用舞台,投入到工业机器视觉中。【1】
3、20世纪70年代,出现课程和明确理论体系
70年代中期,麻省理工学院(MIT)人工智能(AI)实验室:CSAIL正式开设计算机视觉课程。

1977年David Marr在MIT的AI实验室提出了,计算机视觉理论(Computational Vision),这是与 Lawrence Roberts当初引领的积木世界分析方法截然不同的理论。计算机视觉理论成为80年代计算机视觉重要理论框架,使计算机视觉有了明确的体系,促进了计算机视觉的发展。
4、20世纪80年代 ,独立学科形成,理论从实验室走向应用
1980年,日本计算机科学家Kunihiko Fukushima在Hubel和Wiesel的研究启发下,建立了一个自组织的简单和复杂细胞的人工网络——Neocognitron,包括几个卷积层(通常是矩形的),他的感受野具有权重向量(称为滤波器)。这些滤波器的功能是在输入值的二维数组(例如图像像素)上滑动,并在执行某些计算后,产生激活事件(2维数组),这些事件将用作网络后续层的输入。Fukushima的Neocognitron可以说是第一个神经网络【2】,是现代 CNN 网络中卷积层+池化层的最初范例及灵感来源。
1982年,David Marr发表了有影响的论文-“愿景:对人类表现和视觉信息处理的计算研究”。基于Hubel和Wiesel的想法视觉处理不是从整体对象开始, David介绍了一个视觉框架,其中检测边缘,曲线,角落等的低级算法被用作对视觉数据进行高级理解的铺垫。同年《视觉》(Marr, 1982)一书的问世,标志着计算机视觉成为了一门独立学科。
1982年 日本COGEX公司于生产的视觉系统DataMan,是世界第一套工业光学字符识别(OCR)系统。
1989年,法国的Yann LeCun将一种后向传播风格学习算法应用于Fukushima的卷积神经网络结构。在完成该项目几年后,LeCun发布了LeNet-5--这是第一个引入今天仍在CNN中使用的一些基本成分的现代网络。现在卷积神经网络已经是图像、语音和手写识别系统中的重要组成部分。
5、20世纪90年代,特征对象识别开始成为重点
1997年,伯克利教授Jitendra Malik(以及他的学生Jianbo Shi)发表了一篇论文,描述了他试图解决感性分组的问题。研究人员试图让机器使用图论算法将图像分割成合理的部分(自动确定图像上的哪些像素属于一起,并将物体与周围环境区分开来)
1999年, David Lowe 发表《基于局部尺度不变特征(SIFT特征)的物体识别》,标志着研究人员开始停止通过创建三维模型重建对象,而转向基于特征的对象识别。

1999年,Nvidia公司在推销Geforce 256芯片时,提出了GPU概念。GPU是专门为了执行复杂的数学和集合计算而设计的数据处理芯片。伴随着GPU发展应用,游戏行业、图形设计行业、视频行业发展也随之加速,出现了越来越多高画质游戏、高清图像和视频。
6、21世纪初,图像特征工程,出现真正拥有标注的高质量数据集
2001年,Paul Viola 和Michael Jones推出了第一个实时工作的人脸检测框架。虽然不是基于深度学习,但算法仍然具有深刻的学习风格,因为在处理图像时,通过一些特征可以帮助定位面部。该功能依赖于Viola / Jones算法,五年后,Fujitsu 发布了一款具有实时人脸检测功能的相机。
2005年,由Dalal & Triggs提出来方向梯度直方图,HOG(Histogramof Oriented Gradients)应用到行人检测上。是目前计算机视觉、模式识别领域很常用的一种描述图像局部纹理的特征方法。
2006年,Lazebnik, Schmid & Ponce提出一种利用空间金字塔即 SPM (Spatial Pyramid Matching)进行图像匹配、识别、分类的算法,是在不同分辨率上统计图像特征点分布,从而获取图像的局部信息。
2006年,Pascal VOC项目启动。它提供了用于对象分类的标准化数据集以及用于访问所述数据集和注释的一组工具。创始人在2006年至2012年期间举办了年度竞赛,该竞赛允许评估不同对象类识别方法的表现。检测效果不断提高。
2006年左右,Geoffrey Hilton和他的学生发明了用GPU来优化深度神经网络的工程方法,并发表在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。他给多层神经网络相关的学习方法赋予了一个新名词–“深度学习”。随后深度学习的研究大放异彩,广泛应用在了图像处理和语音识别领域【3】,他的学生后来赢得了2012年ImageNet大赛,并使CNN家喻户晓。
2009年,由Felzenszwalb教授在提出基于HOG的deformable parts model(DPM),可变形零件模型开发,它是深度学习之前最好的最成功的objectdetection & recognition算法。它最成功的应用就是检测行人,目前DPM已成为众多分类、分割、姿态估计等算法的核心部分,Felzenszwalb本人也因此被VOC授予"终身成就奖"。
OpenMMLab简介
总体介绍
OpenMMLab 首次发布于 2018 年,当时算法开源还没有蔚然成风,复现靠运气,对比凭人品,PyTorch 生态也远不足以抗衡 TensorFlow。模块化设计、算法支持丰富的检测算法库 MMDetection 的出现,为这个研究领域带来了新的气息。自此之后,越来越多的标准化算法工具箱涌现出来,开源也逐渐成为研究者们理所当然的事情。从 2018 年到 2021 年,OpenMMLab 也不断推出新的算法框架,覆盖更多的研究领域和算法,从一枝独秀到百花齐放,形成了 OpenMMLab 1.0 版本。代码质量和易用性始终是我们关注的重点,形成了良好的开发体验和口碑,被全球 100 多个国家和地区的开发者使用。
经过一年的潜心研发,OpenMMLab 2.0 正式亮相。我们发布了新一代训练架构 MMEngine,以统一的执行引擎,灵活支持了各算法库中 20 个以上的计算机视觉任务和半监督、自监督等丰富的训练流程。在此基础上,OpenMMLab 2.0 还新增了 MMRotate,MMFewshot,MMFlow,MMHuman3D,MMSelfSup,MMRazor 六个算法库和 MMDeploy 模型部署框架,实现了从模型训练、部署到推理的无缝衔接,打通了 AI 落地的最后一公里。OpenMMLab 2.0 还对训练和推理芯片进行了广泛适配,并在新一代核心架构设计之初就将多训练芯片的支持纳入考量,促进了国产软硬件生态共同发展。
新架构
基于 MMEngine,OpenMMLab 2.0 的核心架构焕然一新,具有通用、统一、灵活三大特点。
通用
OpenMMLab 2.0 中的 20 多个算法任务都基于一个强大且通用的训练器。和 OpenMMLab 1.0 中的训练器相比,新的训练器以统一的方式实现了数据、模型、评测等组件的构造流程供各算法库调用,以更加可拓展的方式支持了不同芯片环境(CPU,GPU,Apple M1,MLU等)下的分布式和非分布式训练,并支持了一些最新的大模型训练技术如 FullyShardedDataParallel。下游的各种算法库都可以直接使用这个训练器,在简化代码的同时,通过依赖最新的 MMEngine 享受最新的训练技术和芯片支持。
同时,这个通用的训练器还支持被 OpenMMLab 体系外的算法库单独使用,它可以做到以少量代码训练不同任务:例如仅使用 80 行代码训练 imagenet(而 pytorch example 需要 400行),100 行代码训练 CLIP(OpenCLIP 中有上千行训练代码) ,还能轻松兼容当前流行的算法库中的模型,例如 TIMM,TorchVision 和 Detectron2。
统一
OpenMMLab 1.0 中的各算法库分别支持了感知、生成、预训练等 30 多个算法方向,每个算法方向中还有各种不同的算法和训练范式,各算法库也因此在接口上存在细微差别,难以兼容,使得支持新芯片和训练技术的开发成本和算法库数量成正比。
在 OpenMMLab 2.0 中,我们将不同算法的训练流程统一拆解成了数据、数据变换、模型、评测、可视化器等抽象,并且将这些接口进行了统一设计,在 MMEngine 和 MMCV 中实现了若干基类来定义它们的接口。为了保持架构的开放性,上述关键抽象都在 MMEngine 中有一个对应的注册器进行管理,使得符合接口定义的扩展模块只要被正确注册进了注册器中,就可以通过配置文件进行使用。OpenMMLab 2.0 中的各个算法库都继承了这些注册器,并且基于 MMEngine 的基类和接口约定重构了相关组件,拥有了统一的训练/测试/可视化抽象、统一的数据接口和数据流。示意如下:
同时,OpenMMLab 2.0 中的各个算法库也继承了 MMEngine 中的注册器,使得一个符合接口约定的拓展模块只需要被实现一次,就可以被 OpenMMLab 2.0 中的其他算法库使用。例如,我们可以基于一份代码搞定所有任务的轻量化,使得 MMRazor 1.x 可以优化 36% 的代码量 ;训练芯片等上下游也只需一次性对接 MMEngine 接口,便可适配多个算法库 。