基于text2vec进行文本向量化、聚类
基于text2vec进行文本向量化、聚类
- 基于text2vec进行文本向量化、聚类
-
- 介绍
- 安装
-
- 安装text2vec库
- 安装transformers库
- 模型下载
- 文本向量化
-
- 使用text2vec
- 使用transformers
- 文本聚类
-
- 训练流程:
- 训练代码
- 推理流程
- 推理代码
基于text2vec进行文本向量化、聚类
介绍
文本向量表征工具,把文本转化为向量矩阵,是文本进行计算机处理的第一步。
text2vec实现了Word2Vec、RankBM25、BERT、Sentence-BERT、CoSENT等多种文本表征、文本相似度计算模型,并在文本语义匹配(相似度计算)任务上比较了各模型的效果。
安装
安装text2vec库
pip install text2vec
安装transformers库
pip install transformers
模型下载
默认情况下模型会下载到cache的目录下,不方便直接调用
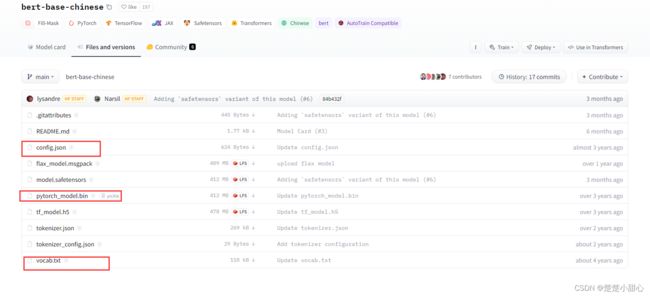
需要手动下载以下三个文件,新建bert_chinese文件夹,把这三个文件放进去。
https://huggingface.co/bert-base-chinese/tree/main
文本向量化
使用text2vec
from text2vec import SentenceModel
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
model_path = "bert_chinese"
model = SentenceModel(model_path)
embeddings = model.encode(sentences)
print(embeddings)
使用transformers
from transformers import BertTokenizer, BertModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Load model from local
model_path = "bert_chinese"
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
文本聚类
训练流程:
- 加载新闻数据
- 基于text2vec利用bert模型进行文本向量化
- 基于KMeans对向量化的模型进行聚类
- 基于三种评估指标查看模型好坏
- 利用joblib保存模型
训练代码
from transformers import BertTokenizer, BertModel
import torch
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.metrics import silhouette_score
from sklearn.metrics import davies_bouldin_score
import joblib
import os
#get txt file
file_path = "data\THUCNews"
files = os.listdir(file_path)
contents = []
for file in files:
file_p = os.path.join(file_path,file)
with open(file_p, 'r',encoding='utf-8') as f:
a = f.read()[:200]
contents.append(a)
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
model_path = "bert_chinese"
# Load model from HuggingFace Hub
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
# sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡','明天下午会下雨','周二下午可能是阴天','星期六不是晴天']
# Tokenize sentences
encoded_input = tokenizer(contents, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings.shape)
X = sentence_embeddings
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
joblib.dump(kmeans, 'kmeans.joblib')
#kmeans = joblib.load('kmeans.joblib')
labels = kmeans.predict(X)
print(labels)
score = silhouette_score(X, labels)
ch_score = metrics.calinski_harabasz_score(X, kmeans.labels_)
davies_bouldin_score = davies_bouldin_score(X, kmeans.labels_)
print("Calinski-Harabasz指数:", ch_score)
print("轮廓系数评分为:", score)
print("Davies-Bouldin指数评分:", davies_bouldin_score)
推理流程
- 输入文本
- 基于text2vec利用bert模型进行文本向量化
- 加载训练好的聚类模型
- 对向量化的文本进行预测类别
- 类别映射
推理代码
import joblib
from transformers import BertTokenizer, BertModel
import torch
map_labels = ["娱乐","星座",'体育']
contents = '双鱼综合症患者的自述(图)新浪网友:比雅 星座真心话征稿启事双鱼座是眼泪泡大的星座,双鱼座是多愁善感的星座,双鱼座是多情的星座,双鱼座是爱幻想的星座。'
kmeans = joblib.load('kmeans.joblib')
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
model_path = "bert_chinese"
# Load model from HuggingFace Hub
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
# Tokenize sentences
encoded_input = tokenizer(contents, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings.shape)
X = sentence_embeddings
labels = kmeans.predict(X)
print(map_labels[labels[0]])