深度学习 #1 —— 环境搭建(基于 Windows)
注:由于写稿时博主已完成搭建,所以部分步骤的截图可能会缺失。
环境搭建可分为三步:
- Anaconda
- CUDA (无英伟达显卡可跳过)
- PyTorch
一、Anaconda
Anaconda 提供了 Conda、Python 等海量科学包,功能齐全、安装简便。
首先进入 Anaconda 官网 下载安装程序。开始安装过程后,切记勾选新建环境变量到 PATH 选项,不然后期手动添加很麻烦。(好吧也不是很麻烦,但能一键完成干嘛手动呢?)

安装完成后就能在开始菜单中找到其文件夹,打开子项 “Anaconda Prompt (anaconda)”

打开后就会出现一个基于命令行的窗口。路径前的 (base) 就是指当前基于 base 环境。接下来创建一个新的环境。切记,请关闭任何代理服务,否则会创建失败。由于写稿时 Anaconda 官网给出的 Python 版本是 3.8,所以博主这里填 3.8。可以替换。
conda create -n python=3.8 然后进入刚刚创建的环境,我们将在这里完成接下来的搭建。
conda activate 然后前面就变成了 (YourName),代表你已进入你创建的环境。
二、CUDA 加速包 (无英伟达显卡可跳过)
拜托,显卡都能用来挖矿了,这不是说明这个算力非常适合跑深度学习吗?抢空气冲冲冲!
截至写稿前,CUDA 最新出到 11.4,但是由于下一步要安装的程序才支持到 11.1,所以我们从 官网 安装 11.1 版本。

以上安装选项中,最下面 local 和 network 的区别是,前者下载 3.1GB 的安装程序,接下来一切在本地进行;后者下载 59.2MB 的安装程序,接下来需要联网获取那几个G的文件。请自行取舍。
打开安装程序之后无脑下一步即可完成安装。接下来添加环境变量(其实前面 Anaconda 没勾选添加到 Path 那个步骤也差不多)。按照下图进行操作。
上图中右下角出现的界面里,当你的电脑有多用户时,如果你只想给当前用户安装就选择上面那个框的 Path 点击编辑,如果想给所有用户安装那就选择下面框中的 Path 点击编辑。
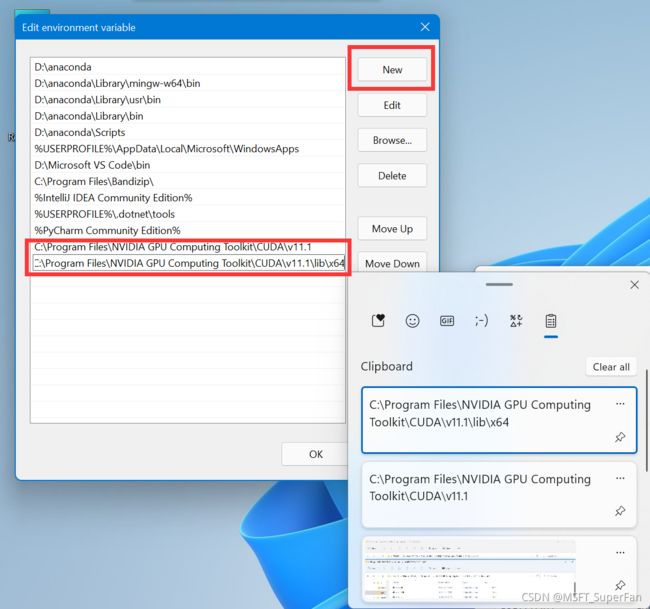
然后定位到你的 CUDA 的安装目录,将下图这两个路径的地址复制下来。(可以两个都复制,因为冷知识:Win+V 快捷键可以调出剪贴板历史)

然后在环境变量编辑界面点击新建,将那两个路径复制进去。
然后一路确定即可。进入命令提示符或 Anaconda Prompt 输入 nvcc -V,若出现如图反馈则说明 CUDA 安装成功。
三、PyTorch
PyTorch 由 Facebook 人工智能研究院推出,是一个开源的 Python 机器学习库。它提供两个高级功能:
- 具有强大的GPU加速的张量计算(如NumPy)
- 包含自动求导系统的深度神经网络
进入 PyTorch 官网, 在前面那一段文字中选择安装较早版本,因为 1.8.0 较为稳定。
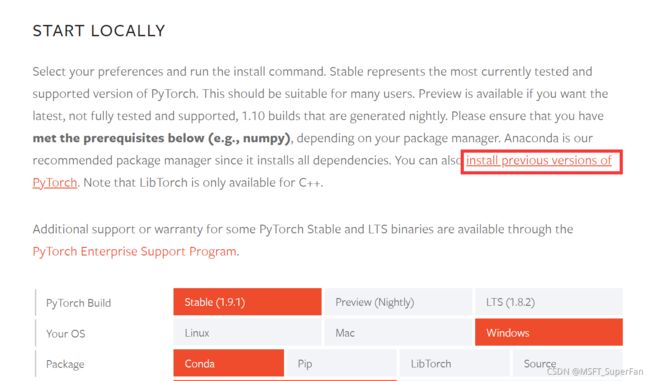
然后在 1.8.0 部分稍微往下拉一点点,选择使用 Wheel 安装,因为装这个成功率较高。如果你的电脑安装了 CUDA 加速,那么选择对应你 CUDA 版本的命令;未安装则选择 CPU。复制一整行命令,然后在你创建的 Conda 环境下右击粘贴执行。然后等待亿会儿即可。


待安装完毕后,安装了 CUDA 的小伙伴可在 Anaconda Prompt 中,在自己搭建的环境下输入 Python 回车,调出 Python 的执行界面。然后输入以下代码:
import torch
print(torch.cuda.is_available())
from torch.backends import cudnn
print(cudnn.is_available())如果两个输出都是 True 则环境搭建完毕,深度学习的第一个挑战成功。

四、测试一下
那么到此,我们就来实际跑一个程序测试一下所创建的环境吧。接下来的代码实现了一个复杂的矩阵运算并用显卡和 CPU 各处理了一次,并能输出两者的时间来直观对比差距。如果没有英伟达显卡只需运行后半部分即可测试环境,如果没有搭好是跑不起来的。
import torch
import time
a = torch.randn(400,600,600).to("cuda:0")
b = torch.randn(400,600,600).to("cuda:0")
start_time = time.time()
for i in range(1,1000):
c = a*b
end_time = time.time()
print("CUDA time: ",(end_time-start_time))
a = torch.randn(400,600,600)
b = torch.randn(400,600,600)
start_time = time.time()
for i in range(1,1000):
c = a*b
end_time = time.time()
print("CPU time: ",(end_time-start_time))
我们打开 Anaconda Prompt,进入自己搭建的环境,然后使用命令
python \ 即可执行本地的 .py 文件。冷知识:直接把任意文件拖进命令行窗口就可以快速粘贴它的绝对路径噢!
执行结果如图所示,可以看到,使用 CUDA 加速后的处理速度比纯 CPU 处理快了上千倍,差距悬殊。博主使用的联想小新 Pro 16 配置是 AMD R7-5800H + 英伟达 GeForce GTX 1650 降频残血版。可以看到,这么一颗堪称轻薄本性能天花板的 CPU,即使面对显卡领域表现并不好的 1650 依然差了不止一个量级,足见显卡强大的运 (wa) 算 (kuang) 能力。
笔记到此结束
感谢大家看到这里,如果喜欢且有帮到你,还请点个赞噢!
另外欢迎关注博主酷安、Bilibili账号,均与 CSDN ID: MSFT_SuperFan 同名,不定期更新数码相关内容!