DeepLab系列
DeepLab系列
1. DeepLabV1
1.1 语义分割中存在的问题
1. 信号下采样导致分辨率降低
- 造成原因:采用
MaxPooling造成的 - 解决办法:引入
atrous Conv空洞卷积
2. CNN的空间不变性
- 造成原因:重复的池化和下采样
- 解决办法:使用
DenseCRF
1.2 空洞卷积
空洞卷积通过引入扩张率Dilation Rate这一参数使得同样尺寸的卷积核获得更大的感受野
1. 扩张率为1的3*3卷积,其与标准卷积一样
2. 扩张率为2的3*3卷积

3. 扩张率为4的3*3卷积

1.3 网络结构
使用VGG16模型作为backbone
- 将VGG16中的全连接层转化为卷积层
- 将VGG16中的
MaxPooling层由kernel=2, stride=2转化为kernel=3, stride=2, padding=1,并且最后两个MaxPooling层的stride全部设置为1 - 将VGG16中的最后三个卷积层修改为空洞卷积,扩张率为2;并且第一个全连接层卷积化也修改为空洞卷积,在论文中
LargeFOV中的设置为12
Pytorch实现
# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File : backbone.py
# Author :CodeCat
# version :python 3.7
# Software :Pycharm
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def conv3x3(in_channels, out_channels, stride=1, dilation=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=padding, dilation=dilation),
nn.ReLU(inplace=True)
)
def conv1x1(in_channels, out_channels, stride=1, dilation=1, padding=1):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=padding, dilation=dilation),
nn.ReLU(inplace=True)
)
class Block(nn.Module):
def __init__(self, in_channels, out_channels, num_depth=2, padding=1, dilation=1, pool_stride=2):
super(Block, self).__init__()
self.num_depth = num_depth
self.conv1 = conv3x3(in_channels, out_channels, padding=padding, dilation=dilation)
self.conv2 = conv3x3(out_channels, out_channels, padding=padding, dilation=dilation)
if self.num_depth == 3:
self.conv3 = conv3x3(out_channels, out_channels, padding=padding, dilation=dilation)
self.pool = nn.MaxPool2d(kernel_size=3, stride=pool_stride, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
if self.num_depth == 3:
x = self.conv3(x)
x = self.pool(x)
return x
class DeepLabV1(nn.Module):
def __init__(self, num_classes=21):
super(DeepLabV1, self).__init__()
self.block1 = Block(in_channels=3, out_channels=64)
self.block2 = Block(in_channels=64, out_channels=128)
self.block3 = Block(in_channels=128, out_channels=256, num_depth=3)
self.block4 = Block(in_channels=256, out_channels=512, num_depth=3, pool_stride=1)
self.block5 = Block(in_channels=512, out_channels=512, num_depth=3, pool_stride=1, dilation=2, padding=2)
self.avg_pool = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)
self.conv6 = conv3x3(in_channels=512, out_channels=1024, padding=12, dilation=12)
self.drop6 = nn.Dropout2d(p=0.5)
self.conv7 = conv1x1(in_channels=1024, out_channels=1024, padding=0)
self.drop7 = nn.Dropout2d(p=0.5)
self.conv8 = conv1x1(in_channels=1024, out_channels=num_classes, padding=0)
def forward(self, x):
input_size = x.shape[-2:]
# (b, 3, 224, 224) -> (b, 64, 112, 112)
x = self.block1(x)
# (b, 64, 112, 112) -> (b, 128, 56, 56)
x = self.block2(x)
# (b, 128, 56, 56) -> (b, 256, 28, 28)
x = self.block3(x)
# (b, 256, 28, 28) -> (b, 512, 28, 28)
x = self.block4(x)
# (b, 512, 28, 28) -> (b, 512, 28, 28)
x = self.block5(x)
# (b, 512, 28, 28) -> (b, 512, 28, 28)
x = self.avg_pool(x)
# (b, 512, 28, 28) -> (b, 1024, 28, 28)
x = self.conv6(x)
x = self.drop6(x)
# (b, 1024, 28, 28) -> (b, 1024, 28, 28)
x = self.conv7(x)
x = self.drop7(x)
# (b, 1024, 28, 28) -> (b, num_classes, 28, 28)
x = self.conv8(x)
# (b, num_classes, 28, 28) -> (b, num_classes, 224, 224)
x = F.interpolate(x, size=input_size, mode='bilinear', align_corners=True)
return x
if __name__ == '__main__':
model = DeepLabV1()
inputs = torch.randn(2, 3, 224, 224)
outputs = model(inputs)
print(outputs.shape)
2. DeepLabV2
2.1 语义分割中存在的问题
- 分辨率被降低导致特征层丢失细节信息:主要由于下采样
stride>1的层造成的 - 目标的多尺度问题
- DCNNs的不变性会降低定位精度
2.1 论文中的解决办法
- 针对问题1,一般是将最后几个
MaxPooling层的stride设置为1(若是通过卷积进行下采样,也是将其stride设置为1),然后再配合空洞卷积 - 针对问题2,本文提出了
ASPP模块 - 针对问题3,和DeepLabV1一样采用
DenseCRF
2.3 ASPP模块
并行采用多个采样率的空洞卷积提取特征,再将特征进行融合,该结构称为空洞空间金字塔池化
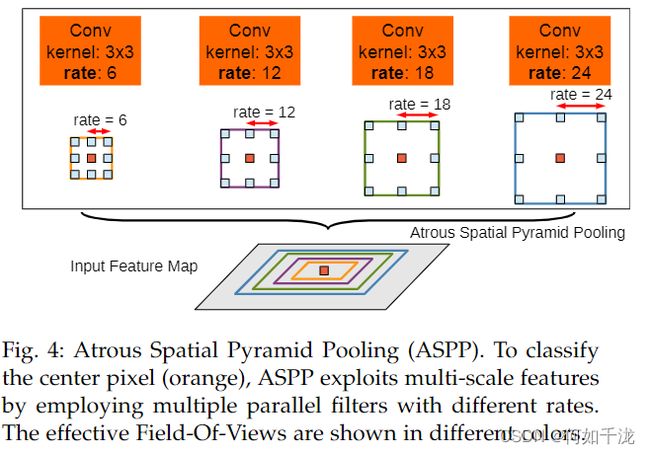
2.4 网络结构
与DeepLabV1使用VGG16作为backbone不同的是,DeepLabV2使用ResNet101作为backbone,做出的修改如下:
- 将
Layer3中的Bottleneck1中原本进行下采样的3x3卷积层(stride=2)的stride设置为1,即不进行下采样,并且3x3卷积层全部采用扩张率为2的空洞卷积 - 将
Layer4中的Bottleneck1中原本进行下采样的3x3卷积层(stride=2)的stride设置为1,即不进行下采样,并且3x3卷积层全部采用扩张率为4的空洞卷积 ASPP模块中的每一个分支只有一个3x3的空洞卷积层,并且卷积核的个数等于num_classes
Pytorch实现
# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File : backbone.py
# Author :CodeCat
# version :python 3.7
# Software :Pycharm
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, dilation=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0, dilation=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=dilation, dilation=dilation, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, stride=1, padding=0, dilation=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.relu(self.bn1(self.conv1(x)))
out = self.relu(self.bn2(self.conv2(out)))
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels, atrous_rates):
super(ASPP, self).__init__()
for i, rate in enumerate(atrous_rates):
self.add_module('c%d'%i, nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=rate, dilation=rate, bias=True))
def forward(self, x):
return sum([stage(x) for stage in self.children()])
class DeepLabV2(nn.Module):
def __init__(self, num_classes, block_nums, atrous_rates):
super(DeepLabV2, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, block_nums[0])
self.layer2 = self._make_layer(128, block_nums[1], stride=2)
self.layer3 = self._make_layer(256, block_nums[2], dilation=2)
self.layer4 = self._make_layer(512, block_nums[3], dilation=4)
self.aspp = ASPP(in_channels=512 * Bottleneck.expansion, out_channels=num_classes, atrous_rates=atrous_rates)
def forward(self, x):
input_size = x.shape[-2:]
# (b, 3, 224, 224) -> (b, 64, 112, 112)
x = self.relu(self.bn1(self.conv1(x)))
# (b, 64, 112, 112) -> (b, 64, 56, 56)
x = self.maxpool(x)
# (b, 64, 56, 56) -> (b, 256, 56, 56)
x = self.layer1(x)
# (b, 256, 56, 56) -> (b, 512, 28, 28)
x = self.layer2(x)
# (b, 512, 28, 28) -> (b, 1024, 28, 28)
x = self.layer3(x)
# (b, 1024, 28, 28) -> (b, 2048, 28, 28)
x = self.layer4(x)
# (b, 2048, 28, 28) -> (b, num_classes, 28, 28)
x = self.aspp(x)
# (b, num_classes, 28, 28) -> (b, num_classes, 224, 224)
x = F.interpolate(x, size=input_size, mode='bilinear', align_corners=True)
return x
def _make_layer(self, channels, block_num, stride=1, dilation=1):
downsample = None
if stride != 1 or self.in_channels != channels * Bottleneck.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, channels * Bottleneck.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels * Bottleneck.expansion)
)
layers = list()
layers.append(Bottleneck(self.in_channels, channels, downsample=downsample, stride=stride, dilation=dilation))
self.in_channels = channels * Bottleneck.expansion
for _ in range(1, block_num):
layers.append(Bottleneck(self.in_channels, channels, dilation=dilation))
return nn.Sequential(*layers)
if __name__ == '__main__':
model = DeepLabV2(
num_classes=21,
block_nums=[3, 4, 23, 3],
atrous_rates=[6, 12, 18, 24]
)
inputs = torch.randn(2, 3, 224, 224)
outputs = model(inputs)
print(outputs.shape)
3. DeepLabV3
改进了ASPP模块
3.1 ASPP模块

ASPP模块
- 一个
1x1卷积 - 三个
3x3空洞卷积,当output_stride=16时,rates=(6, 12, 18);当output_stride=8时,扩张率翻倍,即rates=(12, 24, 36) - 图像级特征:将特征做全局平均池化,后
1x1卷积,再上采样 - 每个卷积层后面会加入
BN层
output_stride说明
- 表示输入图像大小与输出特征图大小的比值
- 在图像分类任务中,最终的输出特征图比输入图像大小小32倍,即
output_stride=32 - 在语义分割任务中,
output_stride一般为8或16,通常通过改变最后1个或2个block,使其不再缩小特征图的大小,并应用空洞卷积来密集提取特征
Pytorch实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels, rate=1, bn_momentum=0.1):
super(ASPP, self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=(1, 1), stride=1),
nn.BatchNorm2d(out_channels, momentum=bn_momentum),
nn.ReLU(inplace=True)
)
self.branch2 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), stride=1, padding=6*rate, dilation=6*rate),
nn.BatchNorm2d(out_channels, momentum=bn_momentum),
nn.ReLU(inplace=True)
)
self.branch3 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), stride=1, padding=12*rate, dilation=12*rate),
nn.BatchNorm2d(out_channels, momentum=bn_momentum),
nn.ReLU(inplace=True)
)
self.branch4 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), stride=1, padding=18*rate, dilation=18*rate),
nn.BatchNorm2d(out_channels, momentum=bn_momentum),
nn.ReLU(inplace=True)
)
self.branch5 = nn.Sequential(
nn.AdaptiveAvgPool2d(output_size=(1, 1)),
nn.Conv2d(in_channels, out_channels, kernel_size=(1, 1), stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels, momentum=bn_momentum),
nn.ReLU(inplace=True)
)
self.conv_cat = nn.Sequential(
nn.Conv2d(out_channels*5, out_channels, kernel_size=(1, 1), stride=1, padding=0),
nn.BatchNorm2d(out_channels, momentum=bn_momentum),
nn.ReLU(inplace=True)
)
def forward(self, x):
b, c, h, w = x.size()
conv1x1 = self.branch1(x)
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
global_feature = self.branch5(x)
global_feature = F.interpolate(global_feature, size=(h, w), mode='bilinear', align_corners=True)
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
result = self.conv_cat(feature_cat)
return result
if __name__ == '__main__':
model = ASPP(in_channels=2048, out_channels=2048)
inputs = torch.randn(2, 2048, 28, 28)
outputs = model(inputs)
print(outputs.shape)
4. DeepLabV3+
4.1 简介
DeepLabV3+不仅采用了ASPP结构,而且还采用了编码器-解码器结构
4.2 网络结构

网络的编码器结构与DeepLabV3一样。
解码器与DeepLabV3不一样,DeepLabV3以factor=16直接进行上采样,而DeepLabV3+采用层级解码器,不是一步到位的,而是通过如下步骤:
- 首先将编码器提取的特征图进行
factor=4的上采样,然后和尺寸相同的low-level特征进行concat拼接 low-level特征首先采用1x1卷积进行降维,这样能够使得编码器提取的特征有一个偏重- 最后再采用
3x3卷积进一步提取特征,再以factor=4进行上采样
完整代码: https://github.com/codecat0/CV/tree/main/Semantic_Segmentation/DeepLabV3+