吴恩达DeepLearningCourse4-卷积神经网络
部分内容参考之前的笔记 PyTorch深度学习实践
文章目录
-
-
- 第一周:卷积神经网络
-
-
- 边缘检测
- Padding、Stride
- 三维卷积
- 卷积神经网络中的一层
- 池化层
-
- 第二周:深度卷积网络实例探究
-
-
- 残差网络
- 1x1卷积
- Inception模块和网络
- 卷积神经网络的迁移学习
-
- 第三周:目标检测
-
-
- 目标定位
- 基于滑动窗口的目标检测
- 滑动窗口的卷积实现
- Bounding Box 预测 /YOLO算法基础
- 交并比 loU
- 非极大值抑制
- Anchor Boxes
-
- 第四周:特殊应用——人脸识别和神经风格转换
-
-
- One-Shot学习
- Siamese 网络
- Triplet Loss(三元组损失)
- 人脸验证与二分类(替换Triplet Loss)
- 神经风格迁移
-
-
第一周:卷积神经网络
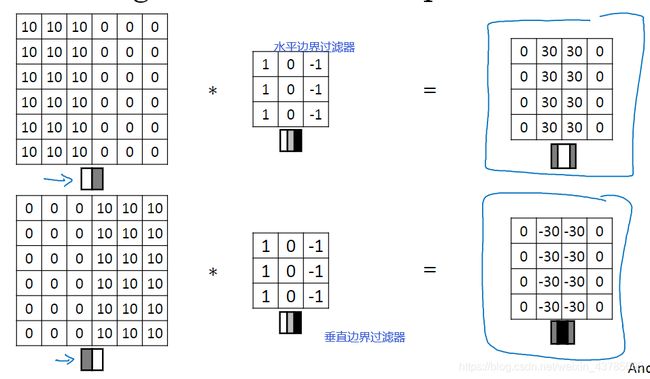
边缘检测
有关卷积运算在此不记录。见PyTorch深度学习实践。
(n, n) * (f, f) = (n-f+1, n-f+1)
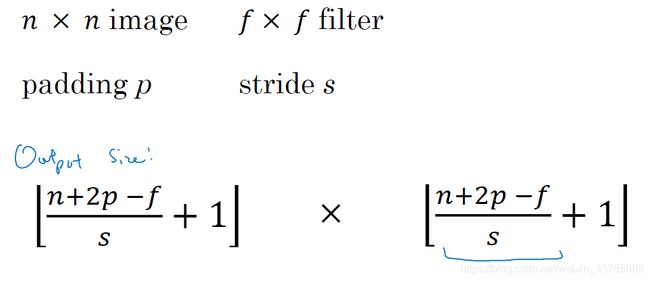
Padding、Stride
Padding要解决的问题:①每次做卷积操作图像都会缩小 ②在角落或者边缘区域的像素点在输出中采用较少,丢掉了图像边缘位置的许多信息
根据填充像素的不同,卷积操作分为Valid卷积(不填充)和Same卷积(填充后,卷积前后图像大小不变)
三维卷积
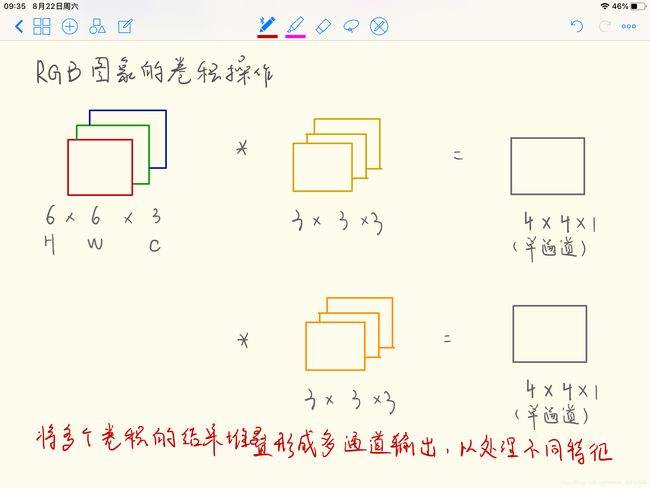
卷积神经网络中的一层

池化层
池化操作具有参数:大小f,步长s,PaddingSize(少见)
池化操作的分类:最大池化、平均池化
池化层有一组超参数,但并没有参数需要学习。一旦确定了f和s,它就是一个固定运算,梯度下降无需改变任何值。所以反向传播并不改变池化层的参数。
常用的参数是f=2, s=2,将输入的高度和宽度缩减为一半。
第二周:深度卷积网络实例探究
残差网络
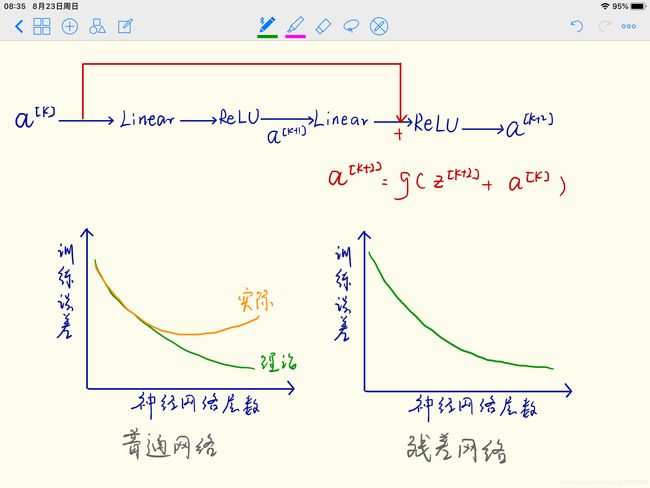
残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,能确定网络性能不会受到影响,很多时候甚至可以提高效率,或者说至少不会降低网络的效率。
1x1卷积
1x1卷积可以减少(压缩通道数)/保持(仅添加非线性函数)/增加输入的通道数,且不改变H和W。
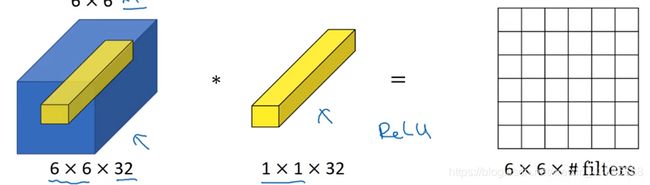
1×1 卷积可以从根本上理解为,在输入的切片中,对这 32 个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字。并在这 36 个单元上重复此过程,输出结果是 6×6×#filters。
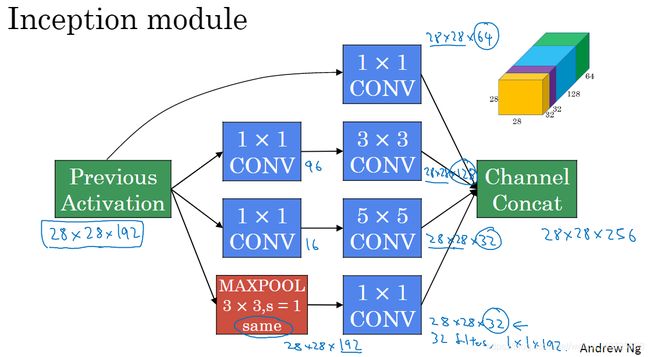
Inception模块和网络
对同一输入进行不同卷积,合并最终结果,取最优解。
不同路径只能改变频道数,不能改变宽度和高度(因为最终需要合并)。
最终将不同的卷积结果沿着通道方向合并。
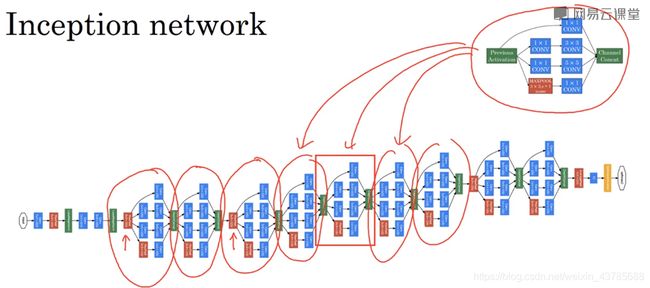
对Inception模块进行多层调用以构建深层的Inception网络。
卷积神经网络的迁移学习
相比于从头训练权重,或者说从随机初始化权重开始,下载别人已经训练好网络结构的权重,通常能够进展的相当快,用这个作为预训练,然后转换到目标任务上。
如果目标任务的数据量较小,可以在下载好的神经网络和参数的基础上,仅训练最后一层的激活函数,使其输出想要的结果。在此情况下,之前的神经网络可以看作是冻结的(不需要对其进行训练),可以先计算前层网络的计算结果存在硬盘里,只需训练最后一层网络。
如果目标任务数据量较大,可以训练网络最后的若干层,甚至整个网络。
第三周:目标检测
目标定位
Localization和Detection问题
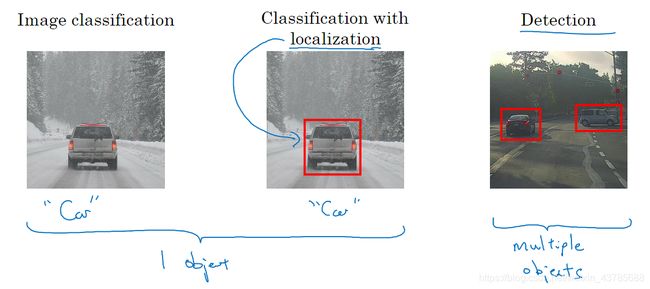
当前问题属于第二类,即给出一张图片,可能是行人、汽车、摩托车和背景中的一种,要求输出类型并给出位置(背景除外)。
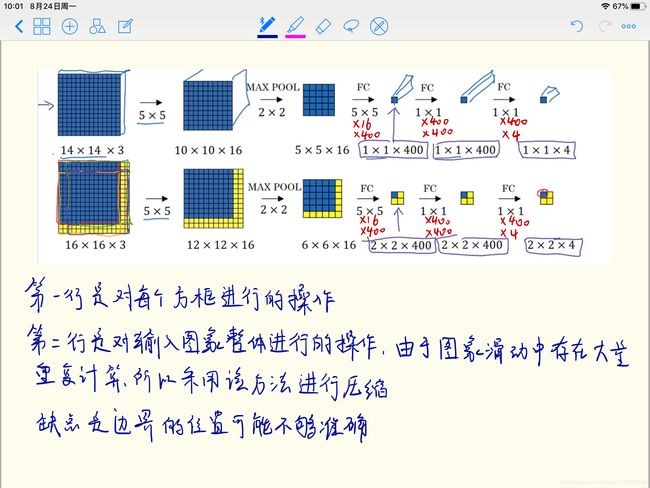
基于滑动窗口的目标检测
针对上例,最初可以使用适当剪切的图片,使得整张图片x几乎都被汽车占据,使用该标签训练集训练卷积网络。
首先选定一个特定大小的窗口,将这个红色小方块输入卷积神经网络,卷积网络开始进行预测,即判断红色方框内有没有汽车。然后将方框按照一定步长向右滑动,直到这个窗口滑过整个图像。
缺点是,如果步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
滑动窗口的卷积实现
①将全连接层转换成卷积层
即:将第一层FC转换成,5x5x16(输入规模)的400(=5x5x16,即Flatten后的元素个数)个过滤器。对第二层FC进行相同操作。
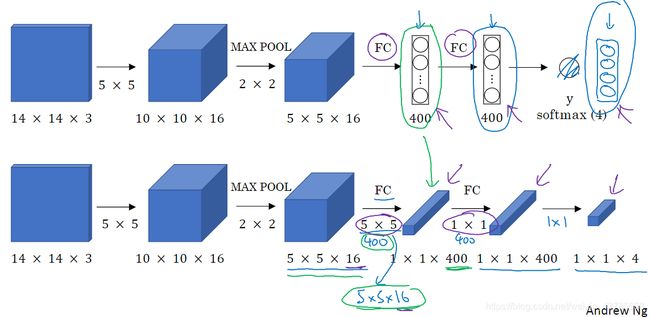
②滑动窗口的卷积实现
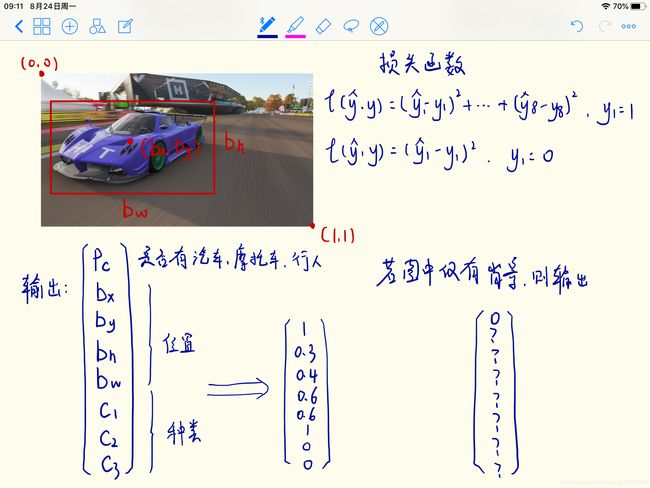
Bounding Box 预测 /YOLO算法基础
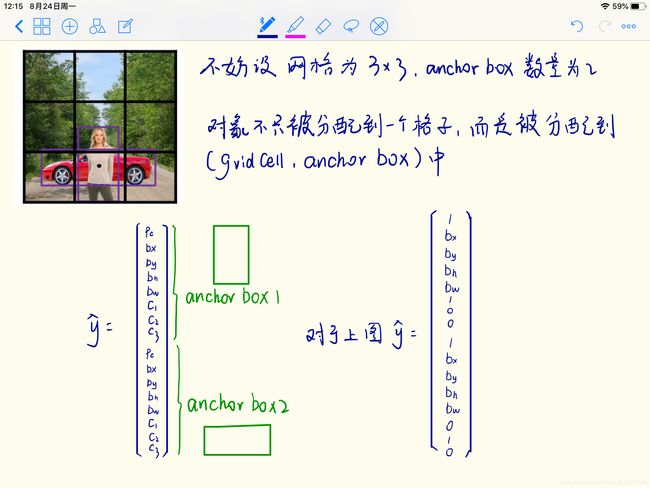
在输入图像上添加网格,并将对象分配给 包含对象中点 的网格。即使对象可以横跨多个格子,也只会被分配到 9 个格子其中之一。
对于上述例子,应用3x3的网格,输出应该是3x3x8
算法优点是,它显式地输出边界框坐标,所以这能让神经网络输出边界框,可以具有任意宽高比,并且能输出更精确的坐标,不会受到滑动窗口分类器的步长大小限制。其次,这是一个卷积实现,有很多共享计算步骤,算法效率很高。
交并比 loU

非极大值抑制
使用YOLO算法时,同一个对象可能被多个方格检测,为了排除部分不准确的方格所采用的方法。
具体步骤(针对只检测车辆,而不检测行人、摩托车的问题;此时的输出为[pc, bx, by, bh, bw]T):
①排除pc<=0.6的方格
②当剩下还有方格时:输出pc值最大的方格,并排除与其loU>=0.5的方格(即针对同一个物体但是不够准确的方格)
Anchor Boxes
目的是在YOLO算法中,处理不同的对象被分配到同一方格的情况。考察不同Anchor Box和对象的交并比,并取最大值。
此时的输出为3x3x2x8(3x3x16)
第四周:特殊应用——人脸识别和神经风格转换
人脸验证(Face Verification):有一张输入图片,以及某人的 ID 或者是名字,这个系统要做的是,验证输入图片是否是这个人。有时候也被称作 1 对 1 问题,只需要弄明白这个人是否和他声称的身份相符。
人脸识别(Face Recognition):1对K问题,有K个人的数据库,输入一张图片,输出该人是否属于K个人之一。
One-Shot学习
在一次学习问题中,只能通过一个样本进行学习。当深度学习只有一个训练样例时,它的表现并不好。
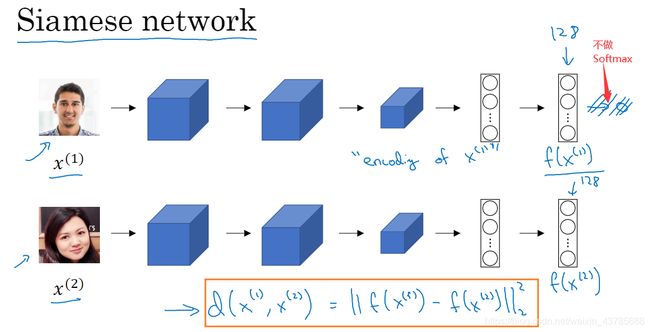
为了能有更好的效果,你现在要做的应该是学习Similarity函数。(1,2) = ,它以两张图片作为输入,然后输出这两张图片的差异值。如果你放进同一个人的两张照片,它输出一个很小的值,如果放进两个长相差别很大的人的照片,它就输出一个很大的值。在识别过程中,如果这两张图片的差异值小于某个阈值,那么这时就能预测这两张图片是同一个人。
Siamese 网络
实现函数d的一种方式是通过Siamese网络。
Triplet Loss(三元组损失)

人脸验证与二分类(替换Triplet Loss)
选取 Siamese 网络,使其同时计算这些嵌入,然后将其输入到逻辑回归单元,然后进行预测,如果是相同的人,那么输出是 1,若是不同的人,输出是 0。这就把人脸识别问题转换为一个二分类问题,训练这种系统时可以替换 Triplet loss 的方法。
最后的逻辑回归单元进行如下操作。

可以对数据库中的图片提前计算并存储,以加快验证速度。
神经风格迁移
使用来表示内容图像,表示风格图像,表示生成的图像
本质上是定义代价函数J(G),并使其最小化
J(G) = α Jcontent(C, G) + β Jstyle(S, G)