【神经网络学习】人工智能与神经网络基础
目录
1. 人工智能的三个学派:
2. 机器学习(Machine Learning)
3. 生物神经元与人工神经元
4. 用计算机模仿神经网络的步骤:
1. 人工智能的三个学派:
1、行为主义:基于控制论,构建感知-动作体系。如控制论,如平衡、行走、避障等自适应控制系统;
2、符号主义:基于算术逻辑表达式,求解问题时先把问题描述为表达式,再求解表达式,可以用公式描述、实现理性思维,例如专家系统;
3、连接主义:基于仿生学,模仿神经元连接关系,仿脑神经元连接,实现感性思维,如神经网络
2. 机器学习(Machine Learning)
机器学习是通过定义算法,以训练一个可以从数据中描述和抽取有价值信息的模型。例如人脸检测和识别、自动驾驶、文本解析、推荐系统等都是ML的广泛应用。
ML通常分为三大类:
- 有监督学习
- 无监督学习
- 半监督学习
在机器学习中最重要的概念是集(数据集)。机器学期的数据集被分割为三个互不相交部分:
训练集:用于训练模型的子集;一般来说训练集是最大的子集;
验证集:用于在训练期间测试模型性能以及执行超参数调整/搜索的子集;
测试集:在训练或验证阶段不接触的子集,仅用于最终性能评估。
而轮则是遍历整个训练集的过程。
超参数:当要完全定义的算法需要将值分配给一组参数时,需要考虑超参数。我们将定义算法本身的参数称为超参数。
1、有监督学习
有监督学习算法在n维空间中划分不同类别元素时有良好表现。
有监督学习算法的原理是:从知识库(Knowledge Base)种提取知识,KB包含被学习对象的标注的数据集。有监督学习算法分为两个阶段,第一个阶段为训练阶段(学习阶段),来尝试解决问题;第二个阶段为测试阶段,来对其性能进行评估。
训练阶段:对数据集进行分析以生成一个可以涵盖所有训练数据的理论,并可以依据次训练对未见过的目标进行预测。在此阶段,我们希望得到的理论具备一定的鲁棒性,可以应对带有相同便签下的示例的变化(即参数的摄动);在训练阶段使用训练集和验证集;
鲁棒性:鲁棒是Robust的音译,也就是健壮和强壮的意思。它是在异常和危险情况下系统生存的关键。所谓"鲁棒性",是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。
测试阶段:即对训练阶段的理论进行应用。在测试阶段使用测试集。
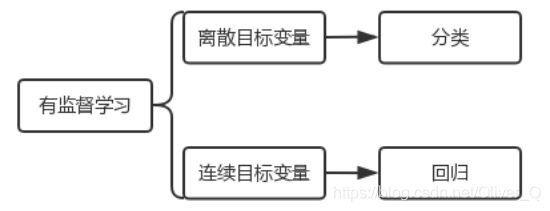
分类问题:标签是离散的,目的是对示例进行分离并预测标签。分类算法的目的是了解分类边界;相当于投票计权的结果;
回归问题:目标变量是连续的,目标是通过示例回归连续值。常用的利于最小二乘法进行回归处理。
2、无监督学习
无监督学习在发现人类难以预测的模式上有良好表现。需要从数据中提取价值的决策者经常使用无监督学习算法。
无监督学习在训练阶段不需要带标注的示例数据集。无监督学习的目的是发现训练集中的自然划分。无监督学习算法不依赖于标签的信息,它们必须是自己发现标签的特征并去学习。无监督学习分为两个阶段,第一个阶段为训练和验证阶段(学习阶段),第二个阶段为测试阶段。
训练和验证阶段:训练算法来发现数据中存在的模式。在有验证集的情况下,验证集应该包含标签。模型的性能可以在每轮结束时进行测试。
测试阶段:在算法的输入中标注数据集,并将其结果与第一阶段的模型进行对比。
无监督学习算法不是根据标签类别进行分类,而是根据它们发现的内容进行分类。如果进行一个简单的比喻,无监督学习更像是“找不同”的小游戏,即相互对比,而有监督学习则是自我对比。无监督学习可以分为两类:

聚类;目的是发现类簇,即数据的自然分区;
关联:目的是发现数据及其之间关联的规则。
3、半监督学习
半监督学习介于有监督学习算法和无监督学习算法之间。其基本思路是,可以利用标注数据的信息来改进无监督学习算法的结果,对于有监督学习亦是这样。
使用半监督学习对其数据集的要求较高,若只有标注数据,则可以使用有监督学习;若没有任何标签数据,则必须使用无监督学习;若数据集同时拥有带标签和不带标签的,或者都标注为相同类的实例的,则可以使用半监督学习。
半监督学习也分为两个阶段,同无监督学习一样。
3. 生物神经元与人工神经元
大脑的主要计算单元为神经元,在人类的神经系统中,目前已知大约有860亿个神经元。而人体神经元是遍布人体的,承担人体的各级信息传递及控制。另外,在一些文献报告中提到,器官移植手术前后被捐献者有了很多捐献者的记忆、性格和爱好等,这也从一方面证明了神经元具有一定的独立性。目前生物学对生物神经元及生物神经系统的研究尚未十分完善,对其基本原理也尚未完全研究成熟。基于目前已经的生物学结构,对生物神经元和人工神经元结构及功能对比如下:
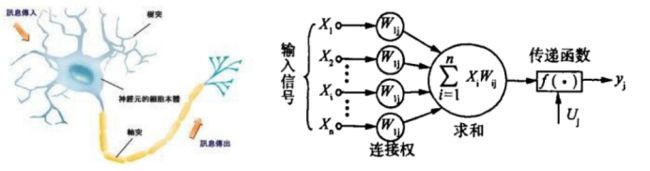
| 表 生物神经元和人工神经元结构及功能 |
||
|
|
生物神经元 |
人工神经元 |
| 树突 |
细小的纤维,以电信号的形式将信息从外部传递到细胞核 |
神经元接受的输入的数量,也可以看作是输入数据的维度D |
| 突触 |
神经元之间的连接点。神经元在与树突相连的突触上接收输入信号 |
与树突相关的权重,这些值在训练过程中会发生变化 |
| 细胞核 |
接收并处理来自树突的信号,产生响应(输出信号)并将其发送至轴突 |
为了模拟生物神经元的活动,仅在输入中存在特定激励时才放电(激活)、可以用非线性函数对细胞核进行建模 |
| 轴突 |
神经元的输出通道,可以连接到其他神经元突触 |
神经元的输出值,也可以作为其他神经元的输入值 |
4. 用计算机模仿神经网络的步骤
- 准备数据:采集大量的“特征/标签”数据;
- 搭建网络:搭建神经网络;
- 优化参数:训练网络获取最佳参数(反传)--优化连接的权重,直到模型的识别准确率达到要求;
- 应用网络:将网络保存为模型,输入新数据,输出分类或预测结果(前传)--输出概率值,概率值最大的一个,就是分类和预测的结果;