图像去模糊综述
深度学习去模糊
文章目录
- 深度学习去模糊
- 摘要
- 一、介绍
- 二、准备工作
-
- 2.1.问题公式化
- 2.2、图像质量评估
- 3、非盲去模糊
- 4、盲去模糊
-
- 4.1网络输入和框架搭建
- 4.2基本层和块
- 4.3网络架构
- 5、损失函数
-
- 5.1 像素损失( Pixel Loss)
- 5.2 知觉损失( Perceptual Loss)
- 5.3 对抗性损失( Adversarial Loss)
- 5.4 相对损失( Loss)
- 5.5 光流量损失(光流量损失)
- 6、去模糊基准数据集
-
- 6.1 图像去模糊数据集
- 6.2 视频去模糊数据集
- 6.3 域特定数据集
- 7、性能评估
-
- 7.1单图像去模糊
- 7.2 视频去模糊
- 8、域特定去模糊
-
- 8.1 人脸图像去模糊
- 8.2 文本图像去模糊
- 8.3 立体图像去模糊
- 9、挑战和机遇
摘要
图像去模糊是低级计算机视觉中的一个经典问题,它的目的是从模糊的输入图像中恢复清晰的图像。深度学习的最新进展使得在解决这一问题方面取得了重大进展,并提出了大量的去模糊网络。本文对最近发表的基于深度学习的图像去模糊方法进行了全面和及时的调查,旨在为这个领域提供一个有用的文献综述。我们首先讨论图像模糊的常见原因,介绍基准数据集和性能指标,并总结不同的问题公式。接下来,我们提出了一种基于架构、损失函数和应用程序的使用卷积神经网络(CNN)的方法的分类,并提供了详细的回顾和比较。此外,我们还讨论了一些特定领域的去模糊应用,包括人脸图像、文本和立体图像对。最后,我们讨论了关键的挑战和未来的研究方向。
一、介绍
图像去模糊技术是低层次计算机视觉领域的一项经典任务,它已经引起了图像处理界和计算机视觉界的关注。图像去模糊的目的是从模糊的输入图像中恢复清晰的图像,其中模糊可以由各种因素引起,如失焦、相机抖动,或快速目标运动。在图1中给出了一些例子。

非深度学习图像去模糊方法通常将该任务表示为一个逆滤波问题,其中模糊图像被建模为与模糊核的卷积的结果,无论是空间不变的或空间变化的。一些早期的方法假设模糊核是已知的,并采用经典的图像反褶积算法,如露西-理查森,或维纳反褶积,有或没有蒂洪霍诺夫正则化,以恢复尖锐的图像。另一方面,盲图像去模糊方法假设模糊核是未知的,其目的是同时恢复清晰的图像和模糊核本身。由于这个任务是不适定的,因此使用各种附加约束来规范解决方案。虽然这些非深度学习方法在某些情况下表现出良好的性能,但它们通常在更复杂但更常见的场景下表现不佳,如具有强运动模糊的图像。
深度学习技术的最新进展已经彻底改变了计算机视觉领域;在图像分类和目标检测等许多领域都取得了重要的进展。图像去模糊也不例外:大量的单图像和视频去模糊,并提高了技术的水平。然而,具有不同网络设计的新方法的引入,使得快速获得该领域的概述具有挑战性。本文旨在通过提供对近期研究进展的调查来填补这一空白,并为新的研究者提供参考点。
具体来说,我们将重点讨论最近发表的基于深度学习的图像和视频去模糊方法。本文的目的是:
------回顾图像去模糊的初步工作,包括问题定义、模糊原因、去模糊方法、质量评估指标和性能评估的基准数据集。
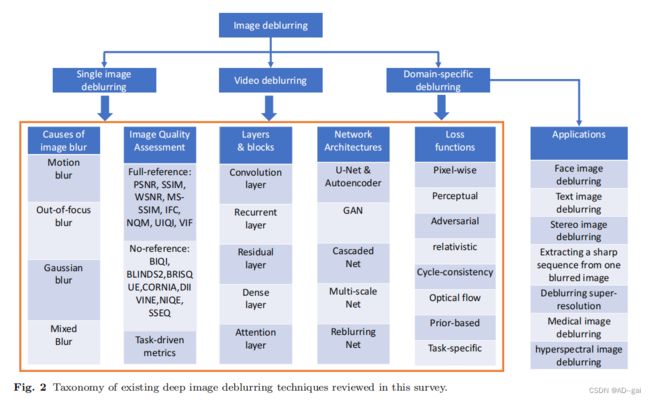
------讨论单个图像和视频去模糊的深度学习模型的新发展,并为现有方法提供一个分类方法(见图2)。
------分析图像去模糊处理所面临的挑战,并探讨研究机遇。
本文的组织结构如下。在第二节中,我们将讨论问题的公式,模糊的原因,去模糊处理的类型和图像质量指标。第3节和第4节分别介绍了基于cnn的非盲图像和盲图像去模糊方法。在第5节中讨论了在深度去模糊方法中应用的损失函数。我们分别在第6节和第7节中介绍公共基准数据集和评估。在第8节中,我们回顾了针对特定领域的三种去模糊方法,即人脸、文本和立体图像。最后,我们讨论了该研究领域所面临的挑战和未来的机遇。
二、准备工作
2.1.问题公式化
在图像捕捉过程中,图像模糊可能由各种因素引起:相机抖动、场景内运动或离焦外模糊。我们将一个模糊的图像Ib表示为

其中,Φ为图像模糊函数,θη为参数向量。是模糊图像Ib的潜在清晰版本。去模糊方法可以分为非盲方法和盲方法,具体取决于模糊功能是否已知(参见章节??)。图像去模糊的目标是恢复一个清晰的图像,即,找到模糊函数的倒数,如

其中Φ−1为去模糊模型,θν表示其参数,Idb为去模糊图像,为潜在锐利图像I的估计值。以深度去模糊方法为例,Φ−1和θν可以分别作为网络及其参数。
运动模糊一幅图像是通过测量相机曝光时间段内的光子来捕获的。在明亮的照明下,曝光时间足够短,使图像捕捉瞬时瞬间。然而,较长的曝光时间可能会导致运动模糊。许多方法通过假设整个图像的模糊是均匀的,直接将退化过程建模为一个卷积过程:

其中K为模糊核,θµ表示加性高斯噪声。在这样的图像中,任何相对于照相机移动的物体沿着相对运动的方向都会显得模糊。当我们使用等式时3来表示模糊过程的等式1、θη对应模糊核和高斯噪声,Φ对应卷积和和算子。用于相机抖动、运动模糊发生在静态背景中,而在没有相机抖动的情况下,快速移动的物体会导致这些物体被模糊,而背景保持清晰。模糊图像自然包含由这两个因素造成的模糊。早期的方法使用移位不变核[24,141]来建模模糊,而最近的研究则解决了非均匀模糊的情况。
失焦模糊除了运动模糊之外,图像的锐度也会受到场景和相机焦平面之间的距离的影响。当物体在焦点上时,它们正好在焦平面上。当物体与相机的距离不同时,场景的部分会聚焦,而其他部分则显得模糊。失焦模糊[71]的点扩散函数(PSF)通常被建模为:
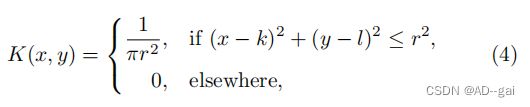
其中(k,l)是PSF的中心,r是模糊的半径。失焦去模糊在显著性检测、离焦放大和图像重聚焦等方面都有应用。为了解决离焦模糊的问题,经典的方法通过模糊检测或编码孔径去除模糊伪影。深度神经网络已被用于检测模糊区域和预测深度来指导去模糊过程。
高斯模糊高斯卷积是图像处理中常用的一种简单模糊模型,定义为

式中,x、y分别为横轴和纵轴到原点的距离,σ为标准差。本文提出了几种经典的方法来去除高斯模糊。
混合模糊在许多现实世界的场景中,多种因素会导致模糊,如相机抖动、物体运动和深度变化。例如,当一个快速移动的物体在一个焦距距离被捕获时,图像可能包括运动模糊和离焦模糊,如图1(d).所示为了合成这种类型的模糊图像,一种选择是首先将清晰的图像转换为其运动模糊版本(例如,通过平均相邻的模糊帧),然后应用基于等式的失焦模糊核 4.或者,我们可以训练一个模糊的网络来直接生成真实的模糊图像。
除了上面说明的主要类型的模糊外,可能还有其他原因,如由色差导致的与通道相关的模糊。
2.2、图像质量评估
图像质量评价(IQA)的方法可分为主观指标和客观指标。主观的方法是基于人类的判断,这可能不需要一个参考图像。一个具有代表性的指标是平均意见评分(MOS)[37],人们以1-5对图像质量进行评分。MOS值因不同的意见而不同,依赖于这些分数的方法通常会考虑到意见分数的统计数据。对于图像去模糊,大多数现有的方法都是根据客观评价分数进行评估的,可以进一步分为两类:全参考和无参考的IQA指标。
全面参考度量全参考指标通过比较恢复后的图像与地面真实值(GT)来评估图像质量。这些指标包括PSNR[36],SSIM[134],WSNR[77],MS-SSIM[135],IFC[110],NQM[19],UIQI[133],VIF[109],和LPIPS[156].其中,PSNR和SSIM是图像恢复任务[26,57,58,84,114,121,129,150,152]中最常用的指标。另一方面,LPIPS和E-LPIPS能够准确地预测人类对图像质量[51,156]的判断。
无参考度量虽然全参考指标需要一个地面真实图像来进行评估,但没有参考指标只使用去模糊图像来衡量质量。为了评估去模糊方法在真实图像上的性能,使用了一些无参考指标,如BIQI[80],BLINDS2[104],brique[78],CORNIA[147],绿素[81],NIQE[79],和SSEQ[68].此外,通过比较对不同视觉任务的精度的影响,如目标检测和识别[64,146],已经开发了一些指标来评估图像去模糊算法的性能。
3、非盲去模糊
图像去模糊的目标是从给定的模糊图像Ib中恢复潜在图像。如果给定了模糊核,那么这个问题也被称为非盲去模糊。即使模糊核可用,由于传感器噪声和高频信息的丢失,这项任务也具有挑战性。
一些非深度方法也采用自然图像先验,例如,全局[55]和局部[166]图像先验,而且在空间域[100]或在频域[56]中重建清晰的图像。为了克服不希望出现的环形伪影,Xu等人[141]和Ren等人[102]结合了空间反褶积和深度神经网络。此外,还提出了几种方法来处理饱和区域[17,136]和去除由图像噪声[52,87]引起的不必要的伪影。
我们在表1中总结了现有的基于深度学习的非盲方法。这些方法可以大致分为两组:第一组使用反褶积,然后是去噪,而第二组直接使用深度网络。
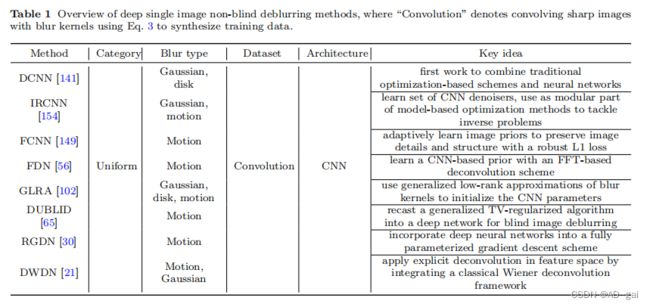
去噪解卷积 这类算法的代表性算法包括[102,106,141,149,154]。Schuler等人[106]开发了多层感知器(MLP)来对图像解卷积。该方法首先通过傅里叶域的正则化逆恢复清晰的图像,然后使用神经网络去除反褶积过程中产生的伪影。Xu等人[141]使用深度CNN去模糊包含异常值的图像。该算法将奇异值分解应用于模糊核,并将传统的基于优化的方案与cnn联系起来。然而,该模型需要对不同的模糊核进行重新训练。受[141]中伪逆核的低秩性质的启发,Ren等人[102]提出了一种广义的深度CNN,在一个统一的框架中处理任意的模糊核,而不需要对每个核进行重新训练。然而,模糊核的低级别分解可能会导致性能的下降。两种方法[102,141]分别连接一个反褶积CNN和一个去噪CNN来去除模糊和噪声。然而,这种去噪网络的设计是为了去除加性高斯白噪声和难以处理模糊图像中的异常值或饱和像素。此外,这些非盲去模糊网络需要进行训练,以达到一个固定的噪声水平,以获得良好的性能,这限制了它们在一般情况下的使用。Kruse等人。[56]通过展开一个迭代方案,提出了一个傅里叶反褶积网络(FDN),其中每个阶段包含一个基于FFT的反褶积模块和一个基于cnn的去噪器。合成了多个噪声水平的数据进行训练,以获得更好的去模糊和去噪性能。
上述方法倾向于学习非盲图像去模糊的去噪模块。学习去噪模块是学习先验的一种方法,我们将在下面进行讨论。
学习先验的去卷积 Bigdeli等人。[7]学习一个代表自然图像分布的平滑版本的平均位移向量场,并使用梯度下降来最小化非盲去模糊的贝叶斯风险。Jin等人的[46]使用一个贝叶斯估计器来同时估计噪声水平和去除模糊。他们还提出了一个网络(GradNet)来加速去模糊的过程。与学习固定图像先验相比,GradNet可以与不同的先验集成,改进现有的基于地图的去模糊算法。Zhang等人[154]训练了一组判别去噪器,并将其集成到一个基于模型的优化框架中,以解决非盲去模糊问题。
从[7,46,154]学习到的先验并不总是能够处理带有异常值的模糊图像。在没有离群值处理的情况下,这些非盲去模糊方法往往会产生铃声伪影,即使是在估计的核是准确的情况下。我们注意到一些超分辨率方法(尺度因子为1)可以用于非盲去模糊任务,因为它们的问题公式相似,如USRNet[153]。
4、盲去模糊
在本节中,我们将讨论最近的盲去模糊方法。对于盲去模糊,潜像和模糊核都是未知的。早期的盲去模糊方法侧重于去除均匀模糊[16,24,76,107,140]。然而,真实世界的图像通常包含非均匀模糊,其中同一图像中的不同区域是由不同的模糊核[103]生成。许多方法已经发展了从三维摄像机运动[35,137]的非均匀模糊建模模糊核。虽然这些方法可以模拟飞机外的摄像机抖动,但它们不能处理动态场景,这激发了使用移动对象的模糊场[10,27,40]。运动不连续和遮挡使模糊核的准确估计具有挑战性。近年来,人们提出了几种基于深度学习的动态场景[26,84,129]去模糊化方法。
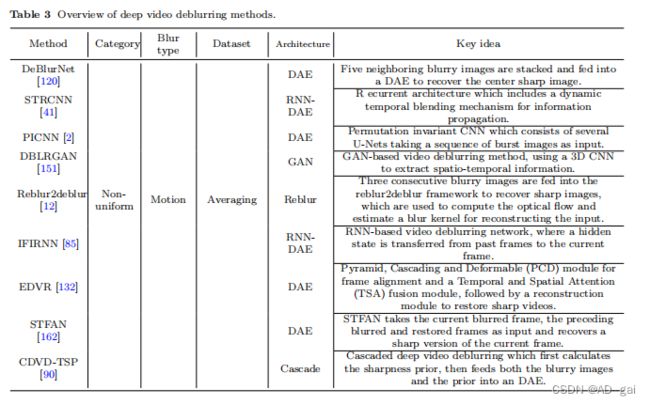
表2和表3分别总结了具有代表性的单幅图像和视频去模糊方法。为了分析这些方法,我们首先引入了网络输入的帧聚合方法。然后,我们回顾了在现有的去模糊网络中使用的基本层和块。最后,我们讨论了其架构,以及当前方法的优点和局限性。
4.1网络输入和框架搭建
单个图像去模糊网络以单个模糊图像作为输入,生成相应的去模糊结果。视频去模糊方法以多个帧作为输入,并在图像或特征域中聚合帧信息。图像级聚合算法,如Su等[120],堆叠多个帧作为输入,并估计中心帧的去模糊结果。另一方面,特征级聚合方法,如Zhou等[162]和Kim等[41],首先从输入帧中提取特征,然后融合特征来预测去模糊的结果。
4.2基本层和块
本节简要回顾了用于图像去模糊的最常用的网络层和块。

4.3网络架构
我们将最广泛使用的用于图像去模糊的网络架构分为五类:深度自动编码器(DAE)、生成式对抗网络(GAN)、级联网络、多尺度网络和重模糊网络。我们将在以下章节中讨论这些方法。
深度自动编码器(DAE)
深度自动编码器首先提取图像特征,解码器从这些特征中重建图像。对于单个图像去模糊,许多方法都使用带有残差学习技术的U-Net架构。[26,89,112,116,129].在某些情况下,额外的网络可以帮助利用额外的信息来指导U-Net。例如,Shen等人[112]提出了一个人脸解析/分割网络来预测人脸标签作为先验,并同时使用模糊的图像和预测的语义标签作为U-Net的输入。其他方法采用多个u型网来获得更好的性能。Tao等人的[129]分析了不同的u型网和DAE,并提出了一个尺度递归网络来处理模糊的图像。第一个U-net获得粗去模糊图像,然后输入另一个U-net,得到最终结果。[113]的工作结合了这两种想法,使用去模糊网络获得粗糙的去模糊图像,然后输入它们进入一个人脸解析网络来生成语义标签。最后,将粗去模糊图像和标签都输入U-Net,获得最终的去模糊图像。
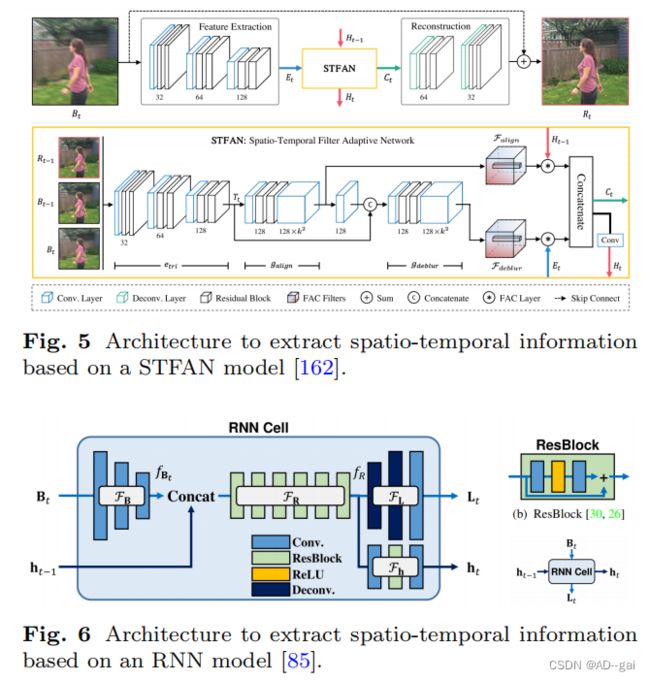
视频去模糊方法可以根据其输入分为两组。第一组以一堆相邻的模糊帧作为输入,提取时空信息。Su等人[120]和Wang等人[132]设计了DAE架构,通过向编码器中连续输入几个帧来消除视频中的模糊,解码器恢复了清晰的中心帧。从编码器的不同层中提取的特征按元素添加到相应的解码器层中,如图4所示,加速收敛,生成更清晰的图像。第二种方法是将单个模糊帧输入编码器以提取特征。已经开发了各种模块来从相邻帧中提取特征,并将这些特征联合输入解码器,以恢复去模糊帧[162]。来自相邻帧的特征也可以被输入到编码器中进行特征提取[41]。许多基于该架构的深度视频去模糊算法已经被开发为[85,116,132]。主要的区别是,从邻近帧建模时间信息的模块,例如,图5中的STFAN[162]和图中的RNN模块[85]。主要的区别是用来建模来自相邻帧的时间信息的模块,例如,图5中的STFAN[162]和图6中的RNN模块[85]。
生成式对抗性网络(GAN)
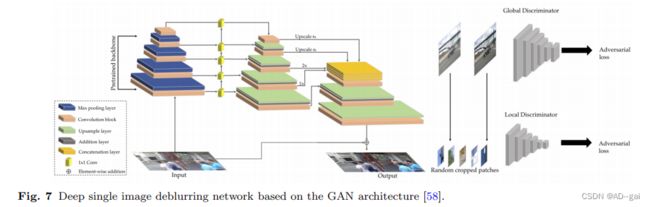
近年来,GANs已广泛应用于图像去模糊,大多数基于gan的去模糊模型共享相同的策略:生成器(图7)生成清晰的图像,使鉴别器无法将它们与真实的尖锐图像区分开来。Kupyn等人[57]提出了去模糊GAN,一种用于运动去模糊的端到端条件GAN。DeburGAN的生成器包含双串卷积块、9个残差块和两个转置卷积块,将模糊图像转换为相应的清晰版本。该方法进一步推广到DeblurGAN-v2[58],它采用相对论条件GAN和双尺度鉴别器,由局部分支和全局分支组成。发电机的核心块是一个特征金字塔网络,它提高了效率和性能。Nah等人[84]和Shen等人[112]使用对抗性损失来生成更好的去模糊图像。
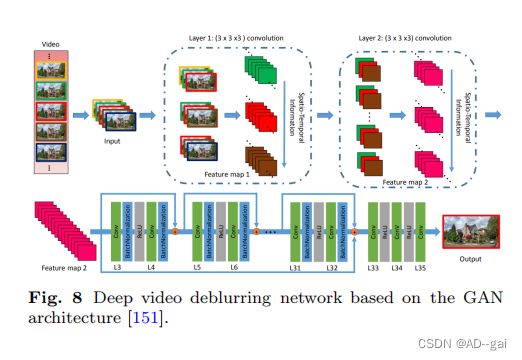
GANs也被用于视频去模糊网络。与单个图像去模糊的主要区别是生成器,它也考虑了来自相邻帧的时间信息。Zhang等人[151]开发了一个3DCNN模型,利用空间和时间信息来恢复尖锐的细节,见图8。Kupyn等人[58]提出了DeblurGAN-v2,通过修改DeblurGAN的单图像去模糊方法来恢复清晰的视频。
级联网络
级联网络包含几个模块,这些模块按顺序连接以构建更深层次的结构。级联网络可分为两组。第一个方法是在每个级联中使用不同的架构。例如,Schuler等人[107]提出了一个两级级联网络,见图9。到第一阶段的输入是一个模糊的图像,并且去模糊的输出被输入到第二阶段来预测模糊的核。第二组在每个级联中重新训练相同的架构,以生成去模糊的图像。前一阶段的去模糊图像被输入相同类型的网络,以生成更精细的去模糊结果。这种级联方案可以用于几乎所有的去模糊网络。虽然该策略取得了更好的性能,但CNN参数的数量显著增加。为了减少这些问题,最近的方法在每个级联[90]中共享参数。
多尺度网络
不同尺度的输入图像描述了互补信息[20,22,139]。多尺度去模糊网络的策略是首先恢复低分辨率的去模糊图像,然后逐步产生高分辨率的清晰结果。Nah等人[84]提出了一种多尺度去模糊网络来从单个图像中去除运动模糊(图10)。在一个从粗到细的方案中,所提出的网络首先生成1/4和1/2分辨率的图像,然后在原始尺度上估计去模糊的图像。许多深度去模糊的方法都使用了多尺度体系结构,在不同尺度上改进去模糊,例如,在[26]中使用嵌套跳过连接,或增加不同尺度的网络连接,例如,在[129]中应用循环层。
再模糊网络
再模糊网络可以合成额外的模糊训练图像[6,152]。Zhang等人[152]提出了一个框架,其中包括学习到模糊GAN(BGAN)和学习到去模糊GAN(DBGAN)。该方法分别学习将清晰图像转移到模糊版本,并从模糊版本中恢复清晰图像。Chen等人[12]引入了一个用于视频去模糊的重模糊2去模糊框架。将三个连续的模糊图像输入框架以恢复清晰的图像,并进一步用于计算光流和估计模糊核来重建模糊输入。
各种模型的优缺点
U-Net架构已被证明是有效的图像去模糊的[112,129]和低水平的视觉问题。用于有效图像去模糊的替代主干架构包括重块[57]或义块[152]的级联。在选择主干后,深度模型可以通过多种方式进行改进。多尺度网络[84]以从粗到细的方式消除不同尺度的模糊,但增加了计算成本[155]。同样,级联网络[113]通过多个去模糊阶段恢复更高质量的去模糊图像。去模糊的图像被转发到另一个网络,以进一步提高质量。其主要区别在于,多尺度网络中的去模糊图像是中间结果,而级联体系结构中的每个去模糊网络的输出可以单独视为最终的去模糊输出。多尺度架构和级联网络也可以通过将多尺度网络作为级联网络中的一个阶段来组合。
图像去模糊的主要目标是实现更好的内容,这可以通过PSNR和SSIM等全参考指标来衡量。然而,这些指标并不总是与人类的视觉感知相一致。因此,基于gan的结构可以应用于生成真实的图像[57,58]。在GAN结构中,上述所有架构都可以作为生成器使用,而鉴别器旨在使去模糊的图像更加真实。对于推理,只需要生成器。基于gan的模型在诸如PSNR或SSIM等失真指标方面通常表现较差。
当训练样本数量不足时,可以使用再模糊网络来生成更多的[152,12]。这个架构由一个学习到模糊和学习去模糊模块组成。上述任何一个深度模型都可以用于合成更多的训练样本,创建原始清晰图像的训练对和学习-模糊模型的输出。虽然该网络可以合成无限数量的训练样本,但它只模拟了训练样本中存在的模糊效应。
像素错位问题是多帧输入图像去模糊的挑战。对应关系通常是通过使用光流或几何变换计算连续帧中的像素关联来构造的。例如,一对有噪声和模糊的图像可以通过光流[31]进行图像去模糊和补丁对应。在应用深度网络时,对齐和去模糊可以通过提供多个图像作为输入来共同处理,并通过三维卷积[151]进行处理。
5、损失函数
人们提出了各种损失函数来训练深度去模糊网络。像素级内容丢失函数在早期的深度去模糊网络中被广泛用于测量重构误差。然而,像素损失并不能准确地测量去模糊图像的质量。这激发了其他损失函数的发展,如特定任务的损失和对抗性损失,以重建更现实的结果。在本节中,我们将回顾这些损失函数。
5.1 像素损失( Pixel Loss)
像素损失函数计算去模糊图像与地面真实值之间的像素级差值。两个主要变量是平均绝对误差(L1损失)和均方误差(L2损失),定义为:
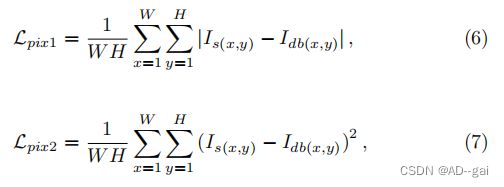
其中,Is(x、y)和Idb(x、y)分别为清晰图像和去模糊图像在位置(x、y)的值。像素损失引导深度去模糊网络生成接近地面真实像素值的清晰图像。大多数现有的深度去模糊网络[9,84,129,145,150,151]应用L2损失,因为它导致一个较高的PSNR值。有些模型是经过训练的以优化L1损失[89,144,152]。然而,由于像素损失函数忽略了长程图像结构,使用该损失函数训练的模型往往会产生过平滑的结果[58]。
5.2 知觉损失( Perceptual Loss)
感知损失函数[47]也被用来计算图像之间的差异。与像素损失函数不同的是,感知损失比较了高级特征空间的差异,如经过分类训练的深度网络的特征,如VGG19[118]。对损失的定义为:
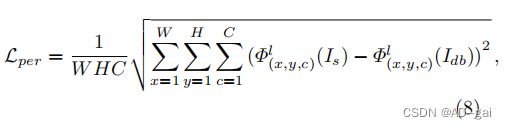
其中,Φlx、y、c(·)是来自第1层的类定义器网络的输出特征。C是第1层的通道数。感知损失函数比较清晰图像与其去模糊版本之间的网络特征,而不是直接匹配每个像素的值,得到视觉上令人满意的结果[57,58,73,151,152]。
5.3 对抗性损失( Adversarial Loss)
对于基于GAN的去模糊网络,联合训练生成器网络G和鉴别器网络D,使G生成的样本可以欺骗D。该过程可以建模为一个具有值函数V(G,D)的最小-最大优化问题:
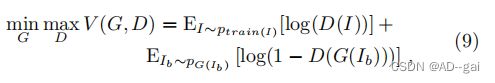
其中,I和Ib分别代表清晰的图像和模糊的图像。为了引导G生成逼真的尖锐图像,我们使用了对抗性损失函数:
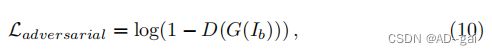
其中,D(G(Ib))为去模糊图像为真实的概率。基于gan的深度去模糊方法已应用于单幅图像和视频去模糊[57,58,84,112,151]。与像素和感知损失函数相比,对抗性损失直接预测去模糊图像是否与真实图像相似,并导致逼真的清晰图像。
5.4 相对损失( Loss)
相对论性损失与对抗性损失有关,可以表述为:
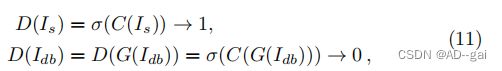
式中,D(·)是输入为真实图像的概率,C(·)是通过鉴别器捕获的特征,σ(·)是激活函数。在训练阶段,只有等式的第二部分11更新生成器G的参数,而第一部分只更新鉴别器。
为了训练一个更好的生成器,提出了相对论损失来计算生成的图像是否比合成的图像[48]更真实。基于此损失函数,Zhang等人[152]用相对论性损失代替标准的对抗性损失:
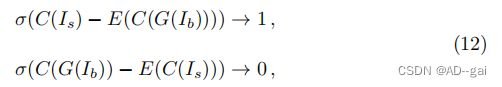
其中,E(·)表示对一批图像的平均操作。C(·)是通过鉴别器捕获的特征,σ(·)是激活函数。发电机由相对论损失函数更新
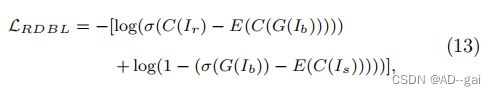
5.5 光流量损失(光流量损失)
由于光流能够表示相邻两帧之间的运动信息,一些研究通过估计光流来消除运动模糊。Gong等人[29]构建一个CNN,首先从模糊图像中估计运动流,然后根据估计的流场恢复去模糊图像。为了获得成对的训练样本,他们通过模拟运动流来生成模糊的图像。Chen等人[12]引入了一个重模糊2去模糊框架,其中三个连续的模糊图像被输入到去模糊子网。然后利用三张去模糊图像之间的光流来估计模糊核并重建输入值。
不同的损失函数的优缺点
一般来说,上述所有的损失函数都有助于图像去模糊的进程。然而,他们的特点和目标却有所不同。在像素级测量方面接近清晰图像的生成像素丢失去模糊图像。不幸的是,这通常会导致过度平滑。感知的损失与人类的感知更一致,而结果与真实的清晰的图像相比仍然表现出明显的差距。对抗性损失函数和光流损失函数的目的是分别生成真实的去模糊图像和建模运动模糊。然而,它们不能有效地提高PSNR/SSIM的值或仅作用于运动模糊图像。多个损失函数也可以用作加权和,权衡它们不同的属性。
6、去模糊基准数据集
在本节中,我们将介绍用于图像去模糊的公共数据集。高质量的数据集应该反映出真实世界场景中所有不同类型的模糊。我们还介绍了特定于领域的数据集,例如,人脸和文本图像,适用于特定于领域的去模糊方法。表4显示了这些数据集的概述。
6.1 图像去模糊数据集
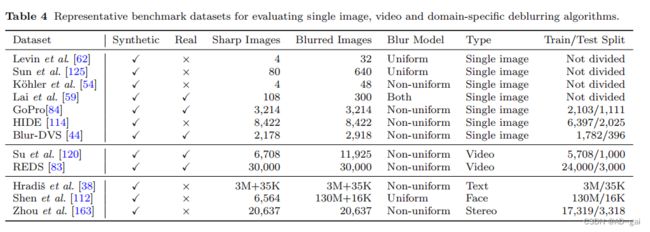
Levin et al. dataset. Levin等人[62]开发了一个数据集,其中包含4个大小为255×255的清晰图像和8个均匀模糊核。通过将真实的模糊核与清晰的图像进行卷积,该数据集总共包含了32张合成的模糊图像。
Sun et al. dataset Sun等人[124]通过使用来自[125]的80张高分辨率自然图像,扩展了Levin等人[62]的数据集。应用来自[62]的8个模糊核,这将得到640张模糊图像。与Levin等人[62]类似,该数据集只包含均匀模糊的图像,不足以训练鲁棒的CNN模型。
K¨ohler et al. dataset 为了模拟非均匀模糊,K¨ohler等人的[54]使用斯图尔特平台(即机械臂)来记录6D相机的运动并捕捉打印出来的图片。有4幅潜在的锐利图像和12幅摄像机轨迹,共得到48张非均匀模糊图像。
Lai et al. dataset Lai等人[59]提供了一个数据集,其中包括100个真实图像和200个合成模糊图像,分别使用均匀模糊核和6D相机轨迹生成。该数据集中的图像涵盖了各种场景,例如,户外、人脸、文本和低光图像,因此可以用于评估各种设置下的去模糊方法。
GoPro dataset Nah等人。[84]创建了一个大规模的数据集,通过帧平均来模拟真实世界的模糊。通过在一个时间间隔内整合多个即时和尖锐的图像,可以生成一个运动模糊图像:

式中,g(·)为相机响应函数(CRF),T为相机曝光周期。代替建模卷积核,M个连续的尖锐帧被平均来生成一个模糊的图像:
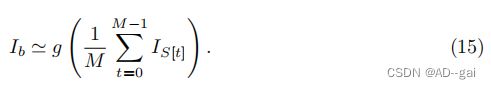
使用GoProHero4黑色相机以240帧每秒的速度拍摄的清晰图像,在不同时间的时间窗口内平均,以合成模糊图像。在时间窗中心的清晰图像被用作地面真实图像。GoPro数据集已被广泛用于训练和评估深度去模糊算法。该数据集包含3214对图像对,可分为训练集和测试集,分别包含2103对和1111对。
HIDE dataset Shen等人[114]主要关注行人和街道场景,创建了一个运动模糊数据集,其中包括摄像机抖动和物体运动。该数据集分别包括6397对和2025对用于训练和测试。与GoPro数据集[84]类似,HIDE数据集中的模糊图像是通过平均11个连续帧来合成的,其中中心帧被用作尖锐的图像。
RealBlur dataset 为了对真实模糊图像上的深度去模糊方法进行基准测试,Rim等人[103]创建了一个包含两个子集的RealBlur数据集。第一个是RealBlur-J,它是由相机JPEG输出组成的。第二个是RealBlur-R,它包含RAW图像。原始图像是通过使用白平衡、去噪和去噪操作生成的。该数据集共包含9476对图像。
Blur-DVS dataset 为了评估基于事件的去模糊方法[44,66]的性能,Jiang等人[44]使用DAVIS240C相机创建了一个Blur-DVS数据集。首先用缓慢的相机运动捕捉一个图像序列,并通过平均相邻的7个帧来合成2178对模糊和清晰的图像。训练集和测试集分别包含1,782对和396对。该数据集还提供了740张真实的模糊图像,而没有清晰的地面真实图像。
6.2 视频去模糊数据集
DVD dataset Su等人[120]用不同设备上的相机捕捉到模糊的视频序列,包括iPhone5s、Nexus4x和GoProHero4。为了模拟真实的运动模糊,他们以240帧/秒的速度捕捉清晰的视频,然后平均取相邻的8帧,以30帧/秒的速度创建相应的模糊视频。该数据集由一个定量子集和一个定性子集组成。定量子集包括来自71个视频(61个训练视频和10个测试视频)的6708个模糊视频和相应的尖锐图像。定性子集涵盖了22个视频,持续时间为3−5秒,用于视觉检查。
REDS dataset 为了捕捉快速移动物体的运动,Nah等人[83]使用GoProHero6黑色相机以120帧/秒和1080×1920的分辨率捕获了300个视频剪辑,并通过递归应用帧插值[88]将帧率提高到1920帧/秒。通过生成24帧的模糊视频从1920帧的视频,峰值和步长伪影出现在DVD数据集[120]被减少了。合成的模糊帧和尖锐帧都被缩小到720×1280,以抑制噪声和压缩伪影。该数据集也被用于评估单个图像去模糊方法[86]。
6.3 域特定数据集
Text deblurring datasets Hradiˇs等人,[38]从互联网上收集了文本文档。这些数据被降采样到120−150DPI分辨率,并分别分成大小为50K和2K的训练集和测试集。具有双边插值的小几何变换也应用于图像。最后,分别从50K和2K图像中裁剪出3M和35K斑块,用于训练和去模糊模型的测试。运动模糊和失焦模糊用于从清晰的图像中生成模糊的图像。Cho等人[15]还提供了一个文本去模糊数据集,只有有限数量的图像。
Face deblurring datasets 利用现有的人脸图像数据集[112,145]构建了模糊的人脸图像数据集。Shen等人从Helen[60]数据集、CMUPIE[117]数据集和CelebA[69]数据集收集图像。他们合成了2万个运动模糊核,生成1.3亿张模糊图像用于训练,并使用另外80个模糊核生成16000张图像用于测试。
Stereo blur dataset 立体声摄像头被广泛应用于空中飞行器和自动驾驶汽车等快速移动的设备中。为了研究立体图像去模糊,Zhou等人[163]使用ZED立体相机捕捉60fps的视频,通过帧插值[88]增加到480fps。取不同数量的连续清晰图像的平均值来合成模糊图像。该数据集包括20,637对图像,分别分为17,319对和3,318对图像,用于训练和测试。
7、性能评估
在本节中,我们将讨论具有代表性的深度去模糊方法的性能评估。
7.1单图像去模糊
我们总结了表5中的代表性方法,该方法比较了三个流行的单图像去模糊数据集,GoPro[84]数据集,以及来自K¨ohler等人[54]和Shen等人[114]的数据集的性能。请注意,所有的结果都来自于各自的论文。对于GoPro数据集上的单幅图像去模糊结果和DVD数据集上的视频去模糊结果,我们另外提供了柱状图,便于比较,如图13和图16所示。
Sun等人[123]、Gong等人[29]和Zhang等人[150]开发的方法是基于CNN和RNN的三个早期深度去模糊网络,表明基于深度学习的方法可以了竞争的结果。Nah等人[84]、Tao等人[129]和Gao等人[26]使用从粗到细的方案设计了多尺度网络,比单尺度去模糊网络取得了更好的性能,因为粗去模糊网络为更高的分辨率提供了更好的先验。除了多尺度策略外,GANs已经被用来产生更真实的去模糊图像[57,58,152]。然而,在GoPro数据集[84]上,基于gan的模型在PSNR和SSIM指标方面取得的结果较差,如表5所示。Purohit等人[96]将一种注意机制应用到去模糊网络中,并在GoPro数据集上取得了最先进的性能。在Shen等人的数据集[114]上得到的结果证明了其有效性。使用弹性块[84]和密度块[152,26]的网络也比以前直接叠加卷积层[29,123]的网络获得了更好的性能。对于非UHD运动去模糊,多补丁结构比多尺度和基于gan的结构具有恢复图像的优势。这可以归因于这个架构可以关注每个小补丁的细节。对于其他架构,如多尺度网络,小尺度版本的图像提供的细节更少,因此这些方法不能显著提高性能。
图12为来自GoPro数据集的单幅图像去模糊的样本结果。我们使用两种多尺度方法[84,129]和两种基于gan的方法[58,152]进行实验。尽管模型架构有所不同,但所有这些方法在这个数据集上的表现都很好。同时,使用相似架构的方法可以产生不同的结果,如基于多尺度架构的Tao等和Nah等[84]。Tao等人在不同尺度之间使用循环操作,并获得更清晰的去模糊结果。
我们还使用LPIPS度量分析了在GoPro数据集上的性能。有代表性的方法的结果如表6所示。在这个指标下,Tao等人[129]比Nah等人[84]和Kupyn等人[57]表现更差。由于使用了不同的指标,观察结果与表5不同。具体来说,Tao等人[129]在GoPro数据集上的PSNR和SSIM方面优于Nah等人[84]和Kupyn等人[57]。结果表明,当使用不同的指标时,我们可能会得出不同的结论。因此,在不同的定量指标中评价去模糊方法是至关重要的。由于评估指标优化了不同的标准,因此设计选择是依赖于任务的。
为了分析不同损失函数的有效性,我们设计了几个resBlocks的共同骨干(由DeburGAN-v2提供)。采用不同的损失函数,包括L1、L2、知觉损失、GAN损失和RaGAN损失[152],以及它们的各种组合用于训练。与DebulurGAN-v2[58]中的设置类似,我们在GoPro数据集上训练每个模型200个时代。学习速率调度程序在DeburGAN-v2中响应。实验结果见表7。一般来说,评价模型在结合重建和感知损失函数时表现更好。然而,使用基于GAN的损失函数并不一定能改善PSNR或SSIM,这与之前的综述[61]的研究结果一致。此外,使用GAN损失或RaGAN损失的相同模型也实现了类似的去模糊性能。
为了评估非盲和盲单图像去模糊方法的性能差异,我们在RWBI数据集上对具有代表性的非盲(FDN[56]和RGDN[30])和盲单图像去模糊方法[26,58,84,129,152]进行了比较。考虑到RWBI数据集不提供地面-真值模糊核,我们使用[143]来估计非盲图像去模糊的模糊核。使用NIQUE和BRIQUE指标得出的结果如表8所示。总的来说,盲去模糊方法优于非盲方法,因为非盲方法需要显式估计模糊内核。在实际应用中,估计模糊核是这仍然是一项具有挑战性的任务。如果一个内核没有得到很好的估计,它将对恢复图像的以下步骤产生负面影响。图14为来自RWBI数据集的样本结果。
为了分析盲去模糊方法和非盲去模糊方法之间的性能差距,我们合成了一个新的地面真模糊核数据集。具体来说,我们使用[153]提供的模糊核,基于GoPro数据集[84]中的清晰图像生成模糊图像。模糊核和模糊图像是非盲图像去模糊方法(DWDN[21]和USRNet[153])的输入,而盲图像去模糊方法(MSCNN[84]和SRN[129])的输入只是模糊图像。表9和图15分别为定量结果和定性结果。总的来说,如果提供地面真模糊核,非盲图像去模糊方法比盲图像去模糊方法具有更好的性能。
为了更好地理解不同训练数据集的作用,我们分别在三个不同的公共数据集(RealBlur-J[103]、GoPro[84]和BSD-B[74,103])上对SRN模型[129]进行了训练。此外,我们还根据“RealBlur-J+GoPro”、“RealBlur-J+BSD-B”和“RealBlur-J+BSD-B+GoPro”的组合来训练SRN模型。结果报告见表13。使用不同数据的模型比只使用一种训练数据的模型表现得更好。特别是,使用三个数据集组合的模型在RealBlur-J测试数据集上获得了最高的PSNR和SSIM值。
考虑到越来越现代的移动设备允许捕获超清晰度(UHD)图像,我们合成了一个新的数据集来研究不同架构在UHD图像去模糊上的性能。我们使用索尼RX10相机分别捕捉500张和100张清晰的图像作为训练集和测试集。接下来,我们使用三维摄像机轨迹生成模糊核,并通过将清晰的图像与大的模糊核(大小111×111,131×131,151×151,171×171,191×191)卷积来合成相应的模糊图像。我们使用两个多尺度网络(MSCNN,SRN),两个基于gan的网络(DeburGAN,DeburGAN-v2)和一个多补丁网络(DMPHN)进行实验。表14显示了这些具有代表性的去模糊方法的结果。结果表明,UHD图像去模糊是一项更具挑战性的任务,多尺度架构在PSNR和SSIM方面取得了更好的性能。对于UHD运动去模糊,多尺度架构获得了更好的性能。由于UHD图像具有更高的分辨率,其1/4的比例仍然包含了细节。多尺度架构以其1/4原始分辨率的UHD模糊图像作为输入,生成相应的清晰版本。在训练阶段,1/4分辨率的图像可以为训练提供更多的信息,从而提高去模糊网络的性能。
为了分析不同架构在离焦去模糊问题上的性能,我们创建了另一个数据集并进行了大量的实验。特别是,我们使用索尼RX10相机捕捉500对尖锐和模糊的图像用于训练,以及100对尖锐和模糊的图像用于测试。图像分辨率为900×600像素。类似地,在该数据集上评估了两个多尺度网络(MSCNN、SRN)、两个基于gan的网络(DeburGAN、DebulurGAN-v2)和一个多补丁网络(DMPHN)。表15显示了上述方法的结果。与基于平均的运动去模糊相比,基于gan的架构在离焦去模糊上具有更好的性能。多尺度和多补丁体系结构在PSNR和SSIM方面并没有明显的改进。对于离焦去模糊,实验结果表明,这两种网络(有和不使用GAN框架)在PSNR和SSIM方面没有显著差异。然而,对于运动去模糊,基于gan的架构产生较低的PSNR和SSIM值。这可以证明,基于gan的架构使用对抗性损失函数来关注整个图像。相比之下,没有GANs的方法考虑了像素级误差(L1、L2)或感知损失函数,从而忽略了整个图像。我们在表10中提供了一个代表性方法的运行时比较。
7.2 视频去模糊
在本节中,我们比较了两个广泛使用的视频去模糊数据集,DVD[120]和REDS[83]数据集,见表11。深度自动编码器[120]是深度视频去模糊方法中最常用的体系结构。与单图像去模糊方法类似,卷积层和res块[34]是最重要的组成部分。循环结构[53]是用于从相邻的模糊图像中提取时间信息,这是与单个图像去模糊网络的主要区别。
大多数视频去模糊方法都采用了像素级损失函数,但与单幅图像去模糊类似,感知损失[163]和对抗性损失[151]也被用于视频去模糊网络。
虽然单图像去模糊方法可以应用于视频,但它们优于利用时间信息的基于视频的方法。Su等人[120]开发了一个模糊视频数据集(DVD),并引入了一个基于cnn的视频去模糊网络,该网络优于基于非深度学习的视频去模糊方法。通过使用帧内迭代,Nah等人[83]的基于rnn的视频去模糊网络获得了比Su等人[120]的更好的性能。Zhou等人[162]提出了STFAN模块,该模块更好地将来自前一帧的信息整合到当前帧的去模糊过程中。此外,采用滤波器自适应卷积(FAC)层来对齐这些帧的去模糊特征。Pan等人的[90]通过使用级联网络和PWC-Net来估计光流来计算锐度先验[122],在DVD数据集上实现了最先进的性能。一个DAE网络使用先验的和模糊的图像来估计尖锐的图像。代表性方法的运行时间见表12。
8、域特定去模糊
虽然大多数基于深度学习的方法是为一般图像去模糊设计的,即常见的自然和人造场景,但一些方法研究了特定领域或设置的去模糊问题,如人脸和文本。
8.1 人脸图像去模糊
早期的人脸图像去模糊方法使用了人脸图像的关键结构[32,91]。近年来,深度学习解决方案通过利用特定的面部特征[45,101,112,145],主导了人脸去模糊技术的发展。Shen等人的[112]使用语义信息来指导人脸去模糊的过程。通过解析网络提取像素级的语义标签,并作为去模糊网络的先验,以恢复尖锐的人脸。Jin等人[45]开发了一个端到端网络,通过重采样卷积操作来扩大接受域。Chrysos等人[18]提出了一种双步结构,它首先恢复低频,然后恢复高频,以确保输出位于自然图像流形上。为了解决人脸视频去模糊的任务,Ren等人的[101]探索了3D面部先验。深度三维人脸重建网络生成一个纹理的三维人脸用于模糊输入,一个人脸去模糊分支在姿态对齐的人脸的引导下恢复清晰的人脸。图17显示了两种非深度方法[91,143]和两种基于深度学习的方法[84,112]的去模糊结果。
8.2 文本图像去模糊
模糊的文本图像会影响光学字符识别(OCR)的性能,例如,在阅读文档、显示器或街道标志时。一般的图像去模糊方法并不适用于文本图像。在早期的工作中,Panci等人[93]将文本图像建模为一个随机场,通过商业算法[25]消除模糊。Pan等人的[92]通过一个去模糊的文本图像基于强度和梯度的l0-正则化先验。最近,深度学习方法,如Hradiˇs等人的[38]的方法,已经证明可以有效地消除失焦和运动模糊。Xu等人[145]采用基于GAN的模型来学习任务中特定类别的先验,设计了人脸和文本图像的多类GAN模型和新的损失函数。图18显示了[38]中几种非深度方法[14,15,16,92,140,143,160]和基于深度学习的方法的去模糊结果,表明[38]在文本图像上获得了更好的去模糊结果。
8.3 立体图像去模糊
立体视觉已被广泛应用于实现深度感知[28]和3D场景理解[23]。当在移动平台上安装立体摄像机时,振动会导致模糊,对后续的立体计算[108]产生负面影响。为了缓解这一问题,Zhou等人[163]提出了一种深度立体去模糊的方法,利用深度信息,并在两个立体图像中改变相应像素的信息。
深度信息有助于估计空间变化的模糊,因为它提供了更接近的先验知识在平移运动的情况下,点比更远的点更模糊,这是一个常见的现实世界的场景。此外,在两个立体图像中对应的像素的模糊度是不同的,这允许在最终的去模糊图像中使用更清晰的像素度。除了上述任务外,其他特定领域的去模糊任务还包括从单个模糊图像[45,97]中提取视频序列,合成高帧率锐化帧[111],以及联合去模糊和超分辨率[158]。
9、挑战和机遇
尽管图像去模糊算法在基准数据集上取得了重大进展,但从真实世界的模糊输入中恢复清晰的图像仍然是[84,120]的挑战。在本节中,我们将总结关键的局限性,并讨论可能的方法和研究机会。
真实数据去模糊算法在现实世界的图像上表现不佳,主要有三个原因。
首先,大多数基于深度学习的方法都需要成对的模糊和清晰的图像来进行训练,其中模糊的输入是人工合成的。然而,这些合成图像和真实世界的模糊图像之间仍然存在着差距,因为模糊模型(例如,等式3和15)是过于简化的[8,12,152]。在合成模糊上训练的模型在合成测试样本上取得了优异的性能,但在真实世界的图像上往往表现更差。获得更好的训练样本的一个可行的方法是建立更好的成像系统[103],例如,通过使用不同的曝光时间来捕捉场景。另一种选择是开发更真实的模糊模型,可以合成更真实的训练数据。
其次,现实世界的图像不仅由于模糊伪影而被破坏,而且还由于量化、传感器噪声和其他因素,如低分辨率的[112,158]。解决这个问题的一种方法是开发一个统一的图像恢复模型,从被各种有害因素破坏的输入中恢复高质量的图像。
第三,在一般图像上训练的去模糊模型可能在来自具有不同特征的领域的图像上表现不佳。具体来说,对于一般的方法来说,在保持文本中特定的人或人物的身份的同时,恢复面孔或文本的清晰图像是具有挑战性的。
损失函数虽然在文献中已经发展了许多损失函数,但尚不清楚如何实现为特定的场景使用正确的公式。例如,如表7所示,在GoPro数据集上,使用L1损失训练的图像去模糊模型可能比使用L2损失训练的模型获得更好的性能。然而,用L1和知觉损失函数训练的相同网络比用L2和知觉损失函数训练的模型更差。
评价指标图像去模糊处理中最广泛使用的评价指标是PSNR和SSIM。然而,PSNR度量与MSE损失密切相关,这有利于过度平滑的预测。因此,这些指标不能准确地反映感知质量。PSNR和SSIM值较低的图像可以有更好的视觉质量[61]。平均意见得分(MOS)是一种衡量感知质量的有效方法。然而,这个度量并不是普遍的,也不容易复制,因为它需要用户的研究。因此,要获得与人类视觉反应相一致的评价指标仍然具有挑战性。
数据和模型数据和模型在获得良好的去模糊结果方面都发挥着重要的作用。在训练阶段,高质量的数据对于构建强图像去模糊模型非常重要。然而,很难收集具有地面真相的大规模高质量数据集。通常,它需要使用两个摄像机(具有适当的配置)来捕获真实的训练样本对,因此这些高质量数据的数量很小,多样性很小。虽然使用合成图像生成数据集更容易,但基于这些数据开发的去模糊模型通常比基于高质量真实世界样本的模型表现更差。因此,构建大量高质量的数据集是一项重要且具有挑战性的任务。此外,高质量的数据集应该包含不同的场景,包括对象类型、运动、场景和图像分辨率。去模糊网络模型的设计主要是基于经验知识的。最近的神经结构搜索方法,如AutoML[67,95,165],也可以应用于去模糊任务。此外,变压器[131]在各种计算机视觉任务中都取得了巨大的成功。如何设计更强大的骨干使用变压器可能是一个机会。
计算成本由于目前许多移动设备都支持捕获4KUHD图像和视频,我们测试了几种最先进的基于深度学习的去模糊方法。然而,我们发现大多数这些基于深度学习的去模糊方法不能高速处理4K分辨率的图像。例如,在一个NVIDIATeslaV100GPU上,Tao等[129]、Nah等[84]和Zhang等[152]分别需要大约26.76、28.41、31.62秒来生成4K去模糊的图像。因此,高效地恢复高质量的UHD图像仍然是一个开放的研究课题。请注意,大多数现有的去模糊网络都是在配备了高端gpu的桌面或服务器上进行评估的。然而,直接在移动设备上开发高效的去模糊算法还需要付出大量的努力。最近的一个例子是Kupyn等人[58]的工作,该工作提出了一个基于移动网络的模型,以实现更有效的去模糊。
非匹配学习目前的深度去模糊方法依赖于成对的清晰图像和模糊的图像。然而,综合模糊的图像并不能代表现实世界模糊的范围。为了利用未配对的例子图像,Lu等人[70]和Madam等人[73]最近提出了两种无监督的领域特定的去模糊模型。进一步改进半监督或无监督的方法来学习去模糊模型似乎是一个很有前途的研究方向。