[论文]基于强化学习的无模型水下机器人深度控制
基于强化学习的无模型水下机器人深度控制
- 摘要
- 介绍
- 问题公式
-
- A.水下机器人的坐标框架
- B.深度控制问题
- 马尔科夫模型
-
- A.马尔科夫决策
- B.恒定深度控制MDP
- C.弯曲深度控制MDP
- D.海底追踪的MDP
- 通过RL解决MDP的水深控制问题
-
- A.动态规划
- B.时间差分和价值函数逼近
- C.确定性策略梯度
- 改进策略
-
- A.神经网络逼近器
- B.优先经验回放
- 性能研究
-
- A.AUV的动力学仿真
- B.线性二次高斯积分控制
- C.非线性模型预测控制
- D.实验设置
- E.恒定深度控制的仿真结果
- F.弯曲深度控制的仿真结果
- G.真实海底跟踪的仿真结果
- 结论
摘要
本文研究了自主水下机器人跟踪期望深度轨迹的深度控制问题。由于水下机器人未知的动力学模型和横摇运动与横摇运动之间的耦合,大多数基于模型或比例积分微分的控制器不能有效地解决这些问题。为此,我们将水下机器人的深度控制问题表述为未知转移概率下的连续状态、连续动作马尔可夫决策过程。基于确定性策略梯度定理和神经网络逼近,提出了一种无模型强化学习算法,该算法从水下机器人的采样轨迹中学习状态反馈控制器。为了提高反向学习算法的性能,我们进一步提出了一种通过重放先前的优先轨迹的批量学习方案。我们通过仿真说明,我们的无模型方法甚至可以与基于模型的控制器相媲美。此外,在中国南海采集的海底数据集上验证了该算法的有效性。
索引术语——自主水下机器人(AUV)、深度控制、确定性策略梯度(DPG)、神经网络、优先经验重放、强化学习(RL)。
介绍
自治水下机器人(AUV)是一种自控潜艇,其灵活性、自主性和尺寸多样性使其在许多应用中具有优势,包括海底测绘[1]、化学示踪[2]、资源收集、污染源定位[3]、危险环境下的操作、海上救援等。因此,水下机器人的控制引起了控制界的极大关注。在水下机器人的诸多控制问题中,深度控制在许多应用中都至关重要。例如,在进行海底测绘时,要求水下机器人与海底保持恒定的距离。
水下机器人的深度控制问题存在许多困难。水下机器人的非线性动力学渲染许多线性控制器如线性二次高斯积分(LQI)和固定比例积分微分(PID)控制器性能不佳。实际应用中,即使采用非线性控制器,也很难获得水下机器人的精确动力学模型。此外,复杂的海底环境带来了各种干扰,例如海流、波浪和模型不确定性,所有这些都增加了深度控制的难度。
传统的控制方法主要集中在基于精确的动力学模型解决水下机器人的控制问题。针对海洋水面舰艇的动态定位系统,提出了一种包含加速度反馈的扩展PID控制器[4]。控制器通过引入测量的加速度反馈来补偿缓慢变化的力的干扰。采用Mamdani模糊规则整定的自适应PID控制器控制非线性AUV系统以稳定的速度跟踪航向和深度,优于经典整定的PID控制器[5]。
其他基于模型的水下机器人控制器包括反推[6]、[7]、滑模[8]、[9]、模型预测控制[10]、[11]、鲁棒控制[12]等。针对船舶和机械系统的跟踪问题,设计了一种自适应反推控制器,保证了闭环跟踪误差的一致全局渐近稳定性[13]。结合视线制导,两个滑模控制器分别被设计用于船舶的摇摆-偏航控制[8]。最大功率控制是一种控制策略,其中每个采样时间的控制输入是基于某个水平的预测来估计的[14]。在[15]中,通过解决特定的最大功率控制问题提出了一种控制器,并控制非线性约束潜艇跟踪海底。在[16]中,基于L2ROV水下航行器的设定点调节和轨迹跟踪的鲁棒控制,提出了非线性深度和偏航控制器。所提出的控制器在实际应用中易于调整,并通过李亚普诺夫参数证明了其稳定性。
然而,在不正确的动态模型下,基于模型的控制器的性能会严重下降。在实际应用中,由于复杂的海底环境,水下机器人的精确模型很难获得。对于这种情况,需要一个无模型控制器,本文通过强化学习来学习。
RL是一个基于动态规划的马尔可夫决策过程(MDP)的求解框架,没有转移模型。它已成功地应用于机器人控制问题,包括单个机器人,移动机器人[17]或多机器人[18],机器人足球[19],双足机器人[20],无人飞行器[21]等的路径规划。
本文基于确定性策略梯度(DPG)定理和神经网络逼近,提出了一种水下机器人深度控制问题的逆向学习框架。根据目标轨迹的不同形式和可观测信息,我们考虑了三个深度控制问题,包括恒定深度控制、弯曲深度跟踪和海底跟踪。
应用RL的关键是如何将深度控制问题建模为多维决策问题。MDP描述了这样一个过程,在这个过程中,处于某个状态的代理采取一个动作,然后以一步的代价转移到下一个状态。在我们的问题中,“状态”和“一步成本”的定义对RL的性能很重要。通常水下机器人的运动由六个坐标及其导数描述。直接将坐标视为MDPs的状态很简单。然而,这种情况对于排除目标深度轨迹的信息并不完美。此外,运动坐标中的角度变量是周期性的,因此不能直接用作状态的分量。因此,我们的工作之一是设计一个更好的状态来克服这些缺陷。
大多数RL算法通常分别逼近一个价值函数和一个策略函数,这两个函数分别用于评估和生成策略,而逼近器的形式取决于MDP的过渡模型。对于水下机器人的深度控制问题,非线性动力学和约束控制输入导致严重的逼近困难。本文选择神经网络逼近器是因为它们强大的表示能力。我们考虑如何为水下机器人的深度问题设计自适应网络结构。
网络设计完成后,我们根据水下机器人的采样轨迹对其进行训练,弥补了无模型的局限性。然而,远洋水下机器人的电池和存储容量限制了水下任务中的采样数据量,因此采样轨迹通常不足以满足训练需求。为了提高数据效率,我们提出了一种通过回放以往经验的批量学习方案。
本文的主要贡献概括如下。
- 我们将水下机器人的三个深度控制问题表述为具有设计良好的状态和成本函数的多学科设计优化问题。
- 设计了两个具有特定结构和校正线性单元激活函数的神经网络。
- 我们提出了一种被称为优先体验重放的批量梯度更新方案,并将其融入到我们的逆向学习框架中。
本文的其余部分组织如下。在第二节中,我们描述了水下机器人的运动和三个深度控制问题。在第三节中,深度控制问题被建模为在设计良好的状态和单步成本函数下的多学科设计优化问题。在第四节中,基于DPG的反向传播算法被应用于求解多目标规划问题。在第五节中,我们重点介绍了几种改进反向链路算法性能的创新技术。在第六节中,模拟是在一个经典的遥控潜水器上进行的将两种基于模型的控制器的性能与我们的算法进行了比较,以验证其有效性。此外,在真实海底数据集上进行了实验,验证了该框架的实用性。
问题公式
在这一节中,我们描述了水下机器人的坐标框架和深度控制问题。
A.水下机器人的坐标框架
水下机器人的运动有六个自由度,包括浪涌、摇摆和升沉,即纵向、横向和垂直位移,以及偏航、滚转和俯仰,后者描述了围绕垂直、纵向和横向轴线的旋转。图1示出了六个自由度的细节。
相应地,有六个独立的坐标来确定水下机器人的位置和方向。地球固定坐标系{I}由η = [x,y,z,φ,θ,ψ]T表示的沿x,y,z轴的位置和方向对应的六个坐标定义。通过忽略地球旋转的影响,假设地球固定坐标系为惯性坐标系。由ν = [u,v,w,p,q,r]表示的线速度和角速度在固定体坐标系{B}中描述,该坐标系是原点固定在水下机器人上的移动坐标系。图1显示了两个坐标框架和六个坐标。
B.深度控制问题
为了简单起见,本文只考虑了水下机器人在x-z平面上的深度控制问题,所有这些问题都可以很容易地扩展到三维情况。因此,我们只检查x-z平面上的运动,并把这些项从平面上去掉。此外,浪涌速度u假设为常数。剩下的坐标用矢量χ = [z,θ,w,q]T表示,包括升沉位置z,升沉速度w,俯仰方位θ,俯仰角速度q。
水下机器人的动力学方程定义如下:
![]()
其中u表示控制向量,ξ表示可能的扰动。.
深度控制的目的是控制水下机器人以最小的能量消耗跟踪期望的深度,其中期望的深度轨迹 z r z_r zr由下式给出
![]()
根据形状和关于 z r z_r zr的信息,我们关注三种情况下的深度控制。
- 恒定深度控制:恒定深度控制是控制水下机器人在恒定深度下运行。期望的深度是恒定的,即 z ˙ r = 0 \dot{z}_r= 0 z˙r=0。为防止AUV绕 z r z_r zr振荡,要求航向与x轴保持一致,即俯仰角θ= 0°。
- 弯曲深度跟踪:弯曲深度跟踪是控制水下机器人跟踪给定的弯曲深度轨迹。期望的深度轨迹是一条曲线,其描述曲线趋势的导数是已知的。除了最小化 ∣ z − z r ∣ | z-z_r | ∣z−zr∣,俯仰角还需要与曲线的倾斜角保持一致。
- 海底跟踪:海底跟踪是控制AUV跟踪海底,同时保持恒定的安全距离。在跟踪海底时,水下机器人只能使用类似声纳的装置测量从自身到海底的相对深度 ∣ z − z r ∣ | z-z_r | ∣z−zr∣,因此海底曲线的倾斜角是未知的。与其他两种情况相比,信息的缺失增加了控制问题的难度。
马尔科夫模型
在本节中,我们将上述三个深度控制问题建模为转移概率未知的多学科设计优化问题,这是由于水下机器人的动力学未知。
A.马尔科夫决策
MDP过程是一个满足马尔可夫性的随机过程。它由四部分组成:
1)一个状态空间 S S S;
2)一个n动作空间 A A A;
3)一步成本函数 c ( s , A ) : S × A → R c(s,A):S×A→R c(s,A):S×A→R;以及
4)平稳一步转移概率 p ( s t ∣ s 1 , a 1 , . . . S t − 1 , a t − 1 ) p(s_t|s_1,a_1,...S_{t-1},a_{t -1}) p(st∣s1,a1,...St−1,at−1)。马尔可夫属性意味着当前状态仅取决于最后的状态和动作,即
![]()
MDP描述了代理如何与环境交互:在某个时间步骤 t t t,处于状态 s t s_t st的代理采取一个动作,并根据转移概率转移到下一个状态 S t + 1 S_{t+1} St+1,观察到的一步成本 c t = c ( s t , a t ) c_t= c(s_t,a_t) ct=c(st,at)。图2说明了MDP的演变。
MDP问题是找到一个策略来最小化长期累积损失函数。策略是状态空间 S S S到动作空间 A A A的映射,可以定义为函数形式 π : S → A π : S → A π:S→A或分布 π : S × A → [ 0 , 1 ] π : S×A → [0,1] π:S×A→[0,1]。因此,优化问题被表述为
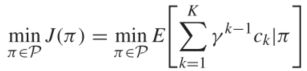
![[论文]基于强化学习的无模型水下机器人深度控制_第1张图片](http://img.e-com-net.com/image/info8/edb6ecb08ef947409544b4637c420482.jpg)
其中 P P P表示策略空间, γ γ γ是折扣因子, 0 < γ < 1 0 < γ < 1 0<γ<1。求和的上标 K K K代表问题的视界。
MDP的四个组成部分的定义对RL算法的性能至关重要。对于水下机器人的深度控制问题,未知的动力学模型意味着未知的转移概率,而动作对应于控制输入,即 a = u a = u a=u。因此,关键是如何设计控制问题的状态和一步代价函数。
B.恒定深度控制MDP
恒定深度控制问题的目的是控制AUV在恒定深度 z r z_r zr下运行。我们设计了表单的一步损失函数
![]()
其中, ρ 1 ( z − z r ) 2 ρ_1(z- z_r)^2 ρ1(z−zr)2表示最小化相对深度, ρ 2 θ 2 ρ_2θ^2 ρ2θ2表示保持沿x轴的俯仰角,最后三项表示最小化消耗的能量。损失函数通过系数 ρ 1 – ρ 4 ρ_1–ρ_4 ρ1–ρ4在不同的控制目标之间进行权衡。
选择描述水下机器人运动的 χ χ χ作为状态是直观的。然而,这种选择在实践中表现更差,原因有二。首先,俯仰角θ是一个角度变量,由于其周期性,不能直接添加到状态中。例如,θ = 0的状态和θ = 2π的状态看似不同,但实际上是等价的。因此,我们将俯仰角分成两个三角分量 [ c o s ( θ ) , s i n ( θ ) ] T [ cos(θ),sin(θ)]^T [cos(θ),sin(θ)]T,以消除周期性。
第二个缺点是状态下的绝对深度z。假设如果我们已经学习了一个控制器,使AUV保持在一个特定的深度 z r z_r zr,现在目标深度变为一个新的深度 z r ′ z_r' zr′水下机器人从未去过的地方。旧 z r z_r zr的控制器将不会在以前探索的状态空间没有覆盖的新深度上工作。比较好的选择是相对深度 Δ z = ˙ z − z r \Delta{z} \dot{=} z-z_r Δz=˙z−zr表示水下机器人离目标深度有多远。一种学习状态包含 Δ z \Delta{z} Δz的最优控制器当 Δ z \Delta{z} Δz为负或者正时,会控制AUV上升或下降。
为了克服上述缺点,我们将恒定深度控制的状态设计如下:
![]()
![[论文]基于强化学习的无模型水下机器人深度控制_第2张图片](http://img.e-com-net.com/image/info8/ff0f17268d894c1ca65fa5793a7fd519.jpg)
C.弯曲深度控制MDP
弯曲深度控制是控制AUV跟踪给定的弯曲深度轨迹 z r = g ( x ) z_r= g(x) zr=g(x)。状态(6)对于弯曲深度控制是不充分的,因为它不包括由曲线的倾斜角 θ c θ_c θc及其导数 θ ˙ c \dot{θ}_c θ˙c表示的目标深度的未来趋势。倾斜角 θ c θ_c θc用于预测AUV应该上升还是下降, θ ˙ c \dot{θ}_c θ˙c表示 θ c θ_c θc的变化率。
图3显示了(6)中定义的处于相同状态的水下机器人跟踪两条不同 θ ˙ c \dot{θ}_c θ˙c的曲线的两种情况。显然,在相同的策略下,它们不能被控制来跟踪两条曲线。失败的原因是水下机器人无法预测曲线的趋势。
为了将关于 θ ˙ c \dot{θ}_c θ˙c的信息添加到状态中,我们考虑它的形式
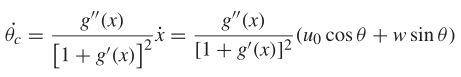
其中 u 0 u_0 u0表示水下机器人的恒定浪涌速度, g ′ ( x ) g'(x) g′(x)和 g ′ ′ ( x ) g''(x) g′′(x)表示g(x)相对于x的一阶和二阶导数。
然后我们考虑相对深度z的导数 z Δ = z − z r z_{\Delta}= z-z_r zΔ=z−zr如下:
![[论文]基于强化学习的无模型水下机器人深度控制_第3张图片](http://img.e-com-net.com/image/info8/772a1cde61714b90939a5eeb03477879.jpg)
其中 θ Δ = ˙ θ − θ c θ_{\Delta}\dot{=}θ-θ_c θΔ=˙θ−θc表示水下机器人和目标深度曲线之间的相对航向角。灵感来源于 z ˙ Δ \dot{z}_{\Delta} z˙Δ的形式?,我们设计了以下一步损失函数:
![]()
其中 ρ 1 z Δ 2 ρ_1z^2_{\Delta} ρ1zΔ2和 ρ 2 θ Δ 2 ρ_2θ^2_{\Delta} ρ2θΔ2分别最小化相对深度和相对航向。这意味着控制水下机器人同时跟踪深度曲线及其趋势。
弯曲深度控制的状态定义为
![]()
D.海底追踪的MDP
如图4所示,海底跟踪是为了控制水下机器人跟踪海底,同时在碰撞的情况下保持恒定的相对深度。在这种情况下,水下机器人只能通过类似声纳的装置从海底观察测量相对垂直距离 Δ z = z − z r \Delta{z} = z-z_r Δz=z−zr,但无法观察海底曲线的倾斜角 θ c θ_c θc及其导数 θ ˙ c \dot{θ}_c θ˙c。
![[论文]基于强化学习的无模型水下机器人深度控制_第4张图片](http://img.e-com-net.com/image/info8/8a8eb3879c084f0faf377331bb909df8.jpg)
因此,由于 θ c θ_c θc和 θ ˙ c \dot{θ}_c θ˙c的缺失,状态(10)不再可行。如果我们采用(6)中定义的状态,图3所示的问题仍然存在。实际上,这个问题也被称为“感知混叠”[22],这意味着环境的不同部分看起来类似于水下机器人的传感器系统。原因是状态(6)只对环境进行了部分观察。因此,我们考虑扩大状态以包含更多的信息。
虽然水下机器人无法测量,但海底曲线的趋势仍然可以通过最近观测到的相对垂直距离序列来估计,即 [ Δ z t − N + 1 , . . . , Δ z t − 1 , Δ z t , cos θ , sin θ , w , q ] T [\Delta{z}_{t-N+1},...,\Delta{z}_{t-1},\Delta{z}_{t},\cos\theta,\sin\theta,w,q]^T [Δzt−N+1,...,Δzt−1,Δzt,cosθ,sinθ,w,q]T其中,N表示序列的长度。因此,使用相同的一步成本函数(5),我们将海底跟踪问题的扩展状态定义为
![]()
最近测量的序列N的长度对于状态的性能很重要,所以我们将在模拟中讨论N的最佳设置。
通过RL解决MDP的水深控制问题
本节,我们采用RL算法去解决上一节中的MDP的深度控制问题
A.动态规划
在这里,我们介绍了一个称为动态规划的经典MDP求解例程,作为深度控制的RL算法的基础。为了方便起见,我们首先定义两种类型的函数来评估策略的性能。价值流函数是一个长期成本函数,定义如下
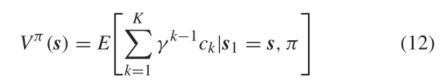
在特定策略π下具有起始状态S1。作用值函数(也称为Q值函数)是一个价值函数
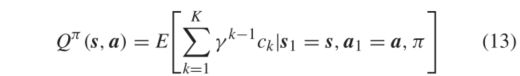
具有选定的开始动作 a 1 a_1 a1。
注意,长期成本函数(4)和价值函数 V π ( s ) V^π(s) Vπ(s)之间的关系如下

其中 p 1 ( s ) p_1(s) p1(s)表示初始状态分布。因此,对于每个状态,最小化(4)等价于贝尔曼最优性方程
![[论文]基于强化学习的无模型水下机器人深度控制_第5张图片](http://img.e-com-net.com/image/info8/5dcbdcd43cc34d799c986ea3168cffb2.jpg)
贝尔曼最优性方程决定了解决MDP问题的基本程序,包括策略评估和策略改进两个阶段[23]。策略评估通过迭代使用贝尔曼方程来估计策略π的价值函数

初始假设的价值函数为 V 0 π ( s ) V^{\pi}_0(s) V0π(s)。迭代可以进行到收敛(策略迭代)或固定步(广义策略迭代),甚至一步(值迭代)[23]。在策略评估之后,进行策略改进,以通过贪婪最小化获得基于估计值函数的改进策略

两个阶段交替迭代,直到策略收敛到最优。
B.时间差分和价值函数逼近
动态规划只适用于在已知转移概率下具有有限状态和有限作用空间的MDP规划。对于第三节中构造的mdp方案,转移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)是未知的,这是由于价值函数更新(16)所需的水下机器人的未知动态。因此,我们采用了一种新的规则,它使用采样过渡数据,称为时间差分(TD)来更新价值函数。
假设在时间k沿着水下机器人的轨迹观察到一个过渡对 ( s k , u k , s k + 1 ) (s_k,u_k,s_{k+1}) (sk,uk,sk+1),那么TD更新Q值函数为形式[23]

其中 α > 0 α > 0 α>0是学习率。
TD算法将状态-动作对的映射更新为它们的Q值,并将其存储为查找表。然而,对于深度控制问题,状态由水下机器人的运动矢量 χ χ χ和期望深度 z r z_r zr组成,而作用通常是螺旋桨的力和扭矩。所有这些连续变量导致连续的状态和动作空间,这些空间不能用查找表来表示。
我们用参数化函数 Q ( s , u ∣ ω ) Q(s,u|ω) Q(s,u∣ω)来表示映射,并更新参数ω如下:

其中 μ ( s k + 1 ∣ θ ) μ(s_{k+1}|θ) μ(sk+1∣θ)是下一节中定义的策略函数。
C.确定性策略梯度
水下机器人深度控制的连续控制输入导致连续动作,因此如果每次迭代执行,在连续动作空间上的最小化(17)是耗时的。
相反,我们通过DPG算法实现策略改进阶段。DPG算法假设一个确定的参数化策略函数 μ ( s ∣ θ ) μ(s|θ) μ(s∣θ),并沿着长期成本函数的负梯度更新参数 θ θ θ
![]()
其中 Δ θ J ( θ ) ^ \widehat{\Delta_{\theta} J(θ)} ΔθJ(θ) 是真实梯度的随机近似。DPG算法推导出 Δ θ J ( θ ) ^ \widehat{\Delta_{\theta} J(θ)} ΔθJ(θ) [24]如下:

其中 Q μ Q^μ Qμ 表示在策略 μ ( u ∣ s ) μ(u|s) μ(u∣s)下的 Q-值函数 。
在最后一节中,Q值函数由参数化逼近器 Q ( s , u ∣ ω ) Q(s,u|ω) Q(s,u∣ω)逼近,因此我们用 ∇ u i Q ( s i , u i ∣ ω ) ∇_{u_i}Q(s_i,u_i|ω) ∇uiQ(si,ui∣ω)代替了 ∇ u i Q μ ( s i , u i ) ∇_{u_i}Q^{\mu}(s_i,u_i) ∇uiQμ(si,ui),近似梯度由下式给出

注意(21)中的近似梯度是由过渡序列计算的,这似乎不适合深度控制问题的在线特性。如果设置M = 1,我们仍然可以得到一个在线更新规则,但是近似的偏差可能会被放大。实际上,批量更新方案可以通过沿着水下机器人的轨迹滑动序列来执行。
我们在TD和DPG算法中定义了两个函数逼近器 Q ( s , u ∣ ω ) Q(s,u|ω) Q(s,u∣ω)和 μ ( s ∣ θ ) μ(s|θ) μ(s∣θ),但没有给出逼近器的具体形式。由于水下机器人的非线性和复杂动力学特性,我们构造了两个神经网络逼近器,即以ω和θ为权值的评价网络 Q ( s , u ∣ ω ) Q(s,u|ω) Q(s,u∣ω)和策略网络 μ ( s ∣ θ ) μ(s|θ) μ(s∣θ)。
![[论文]基于强化学习的无模型水下机器人深度控制_第6张图片](http://img.e-com-net.com/image/info8/1f5243eda405405585293728f3200aae.jpg)
为了通过TD和DPG算法说明两个网络的更新,我们给出了图5所示的结构图。RL算法的最终目的是学习策略网络所代表的状态反馈控制器。在我们的算法中有两条反向传播路径。评估网络由当前Q值 Q ^ ( s k , u k ) \hat{Q}(s_k,u_k) Q^(sk,uk)和后续状态动作对 Q ^ ( s k + 1 , u k + 1 ) \hat{Q}(s_{k+1},u_{k+1}) Q^(sk+1,uk+1)之间的误差加上一步成本 去反向传播,即TD算法的概念。评估网络的输出被传递到“梯度模块”以生成梯度 ∇ u k Q ^ ( s k , u k ) ∇_{u_k}\hat{Q}(s_k,u_k) ∇ukQ^(sk,uk),然后通过DPG算法传播回更新策略网络。这两条反向传播路径分别对应于动态规划中的策略评估和策略改进阶段。请注意,“状态转换器”模块,即第三节中说明的状态设计过程,将水下机器人的坐标 χ χ χ和参考深度信号 z r e f z_{ref} zref转换为状态 s k s_k sk。
改进策略
在最后一节中,我们给出了一个水下机器人深度控制的RL框架,它通过迭代时域和DPG算法来更新两个神经网络逼近器。结合控制问题的特点,从两个方面进一步提出了改进策略。首先,根据水下机器人控制时的物理约束,设计了神经网络的自适应结构,采用了一种新型的激活函数。然后我们提出了一个批处理学习方案来提高数据效率。
A.神经网络逼近器
考虑到水下机器人的非线性动力学特性,我们构造了两个神经网络逼近器,以ω和θ为权值的评价网络 Q ( s , u ∣ ω ) Q(s,u|ω) Q(s,u∣ω)和策略网络μ(s|θ)。
评估网络有四层,以状态s和控制变量u作为输入,其中u不包括在内,直到第二层。输出层是产生标量Q值的线性单元。
策略网络设计为三层结构,在给定输入状态的情况下产生控制变量u。由于水下机器人螺旋桨的功率有限,输出u必须限制在给定的范围内。因此,我们采用 t a n h tanh tanh 单位作为输出层的激活函数。然后,将[-1,1]中tanh函数的输出缩放至给定的区间。
除了网络的结构之外,我们还采用了一种新的激活函数ReLu作为隐藏层。
在传统的神经网络控制器中,激活函数通常使用sigmoid或tanh函数,这些函数对接近零的输入敏感,但对大的输入不敏感。这种饱和特性带来了“梯度消失”问题,即在大的输入下单元的梯度减小到零,并且无助于网络的训练。然而,ReLu函数避免了这个问题,因为它只抑制一个方向上的变化,如图6所示。
![[论文]基于强化学习的无模型水下机器人深度控制_第7张图片](http://img.e-com-net.com/image/info8/25a34fb9a3724c238f228dfd3f26877f.jpg)
此外,ReLu的简单形式可以加快网络的计算速度,这正好符合水下机器人深度控制的在线特性。
![[论文]基于强化学习的无模型水下机器人深度控制_第8张图片](http://img.e-com-net.com/image/info8/a529d0fb57df494ea858e14232904d63.jpg)
最后,我们在图7中说明了两个网络的完整结构。
B.优先经验回放
在本节中,我们考虑如何提高水下机器人深度控制问题的数据效率。该算法不是基于精确模型设计控制器,而是从水下任务中沿水下机器人轨迹采样的转移记录中学习最优策略。然而,远洋水下机器人的电池和存储容量限制了每次水下任务的采样数据量。任务对水下机器人进行充电和部署既费时又有风险,因为复杂的海底环境。因此,对于我们的RL算法来说,从有限数量的采样数据中学习最优控制器是至关重要的。
我们提出了一种称为优先经验回放的批量学习方案,它是林[26]提出的经验重放的改进版本。想象一下用RL算法控制AUV的场景。水下机器人观察随后的状态 s ′ s' s′,状态 s s s下的单步成本 c c c,每次执行控制输入 u u u。我们称 ( s , u , s ′ , c ) (s,u,s',c) (s,u,s′,c)作为一种“经验”。而不是通过新采样的经验来更新评估网络和策略网络,它使用缓存来存储所有访问的经验,并从缓存中采样一批先前的经验来更新两个网络。重放机制重用以前的经验,就像它们是新访问的一样,这大大提高了数据效率。
然而,并不是所有的经验都应该得到同等的重视。如果一种体验给网络的权重带来了微小的差异,它就不值得重播,因为网络已经了解了它的隐含模式。而“错误”的经历应该经常重演。
受(18)的启发,优先化的经验重放采用TD算法的“错误”作为经验的优先级,该优先级由下式给出

优先级衡量从缓存中经验被采样的可能性。因此,优先级越高的体验,对评价网络的权重产生的差异越大,重放的概率也就越大。
综上所述,我们结合上述技术提出了一种基于神经网络的DPG算法。在算法1中给出了更详细的NNDPG过程。
在本节的最后,有必要讨论NNDPG的优势。首先,NNDPG不需要任何关于水下机器人模型的知识,但仍然可以学习一个控制器,其性能在精确的动力学下与控制器具有竞争力。此外,针对水下机器人的控制问题,首次在RL控制器中提出了优先经验回放,极大地提高了数据效率和性能。
性能研究
A.AUV的动力学仿真
在这一节中,我们给出了一组经典的六自由度水下机器人模型的显式动力学方程,用来验证我们的算法。然而,由于我们的算法是完全无模型的,实验可以很容易地扩展到其他水下机器人模型。
如上所述,我们只考虑水下机器人在x-z平面的运动,并假设恒定的浪涌速度 u 0 u_0 u0。简化的动力学方程由下式给出
![[论文]基于强化学习的无模型水下机器人深度控制_第9张图片](http://img.e-com-net.com/image/info8/fb925610bc64456b85322750194446f0.jpg)
![[论文]基于强化学习的无模型水下机器人深度控制_第10张图片](http://img.e-com-net.com/image/info8/db0ac6ca4e374a5fae1bb59e429cd9f1.jpg)
![[论文]基于强化学习的无模型水下机器人深度控制_第11张图片](http://img.e-com-net.com/image/info8/7ff221898fe8443f924c7b82d4be8438.jpg)
其中 [ x G , y G , z G ] [x_G,y_G,z_G] [xG,yG,zG]和 [ x B , y B , z B ] [x_B,y_B,z_B] [xB,yB,zB]分别为重心和浮力; Z q ˙ 、 Z w ˙ 、 M q ˙ 和 M w ˙ Z_{\dot{q}}、Z_{\dot{w}}、M_{\dot{q}}和M_{\dot{w}} Zq˙、Zw˙、Mq˙和Mw˙表示附加质量; Z u q 、 Z u w 、 M u q 和 M u w Z_{uq}、Z_{uw}、M_{uq}和M_{uw} Zuq、Zuw、Muq和Muw表示车身升力和力矩系数; Z w w 、 Z q q 、 M w w 和 Z q q Z_{ww}、Z_{qq}、M_{ww}和Z_{qq} Zww、Zqq、Mww和Zqq横流阻力系数; W W W和 B B B代表水下机器人的重量和浮力。有界控制输入 τ 1 \tau1 τ1和 τ 2 \tau2 τ2是螺旋桨推力和扭矩,它的扰动 Δ τ 1 \Delta\tau1 Δτ1和 Δ τ 2 \Delta\tau2 Δτ2由不稳定的水下环境引起。水动力系数值如表一所示。值得注意的是,方程中包含了水下机器人纵荡和横荡运动的耦合项。
![[论文]基于强化学习的无模型水下机器人深度控制_第12张图片](http://img.e-com-net.com/image/info8/7e8edf9d3237414a836e79526053acef.jpg)
B.线性二次高斯积分控制
我们比较了两种基于模型的控制器和NNDPG学习的状态反馈控制器。第一个是线性二次高斯积分(LQI)控制器[28],由线性化的水下机器人模型导出。
水下机器人(23a)–(23d)的非线性模型可以在稳态下通过SIMULINK线性化模式进行线性化[5]
![[论文]基于强化学习的无模型水下机器人深度控制_第13张图片](http://img.e-com-net.com/image/info8/85fdd7be4a18458eae176d92c991bb6b.jpg)
其中 [ w ′ , q ′ , z ′ , θ ′ ] T [w',q',z',θ']^T [w′,q′,z′,θ′]T指出微小的线性化误差,将稳态点设置为 [ 0 , 0 , 2.0 , 0 ] T [0,0,2.0,0]^T [0,0,2.0,0]T,直接导出线性化的水下机器人模型

其中系数矩阵A、B和C由下式给出
![[论文]基于强化学习的无模型水下机器人深度控制_第14张图片](http://img.e-com-net.com/image/info8/1607eb0c345a4d9097e9ead7f751d00a.jpg)
输出为 y = [ z , θ ] T y=[z,\theta]^T y=[z,θ]T。
由于状态和输出变量都是可测量的,所以设计了一个LQI控制器来解决图8所示的线性化水下机器人模型的深度控制问题。反馈控制器设计为
![]()
其中 ϵ \epsilon ϵ是积分器的输出

增益矩阵K通过求解代数黎卡提方程获得,该方程由以下损失函数的最小化导出:

![[论文]基于强化学习的无模型水下机器人深度控制_第15张图片](http://img.e-com-net.com/image/info8/aa5e418abe6b443a853aa16e36e2903c.jpg)
C.非线性模型预测控制
LQI控制器是基于线性化的水下机器人模型设计的,该模型是原始非线性模型的近似。在一个精确的非线性水下机器人动力学模型下,我们采用了一个由非线性最大功率控制(NMPC)导出的非线性控制器。NMPC设计了一个N步累积损失函数[15]

对于每个时间步长k,NMPC预测最优的N步控制序列 { u k , u k + 1 , . . . , u k + N − 1 } \{u_k,u_{k+1},...,u_{k+N-1} \} {uk,uk+1,...,uk+N−1}通过最小化优化函数
![[论文]基于强化学习的无模型水下机器人深度控制_第16张图片](http://img.e-com-net.com/image/info8/018a29dd16ca4c32b2a5c8ffdbbff270.jpg)
其中预测步长的计数N也称为预测范围。NMPC通过交替迭代两个过程来解决N步优化问题。正向过程使用候选控制序列执行系统方程,以找到预测状态序列 x k + i {x_{k+i}} xk+i。后向过程找到拉格朗日乘子,以消除 J k J_k Jk相对于状态序列的偏导数项,然后沿着梯度向量更新控制序列。重复这两个过程,直到达到所需的精度。
D.实验设置
在这一节中,我们介绍了模拟的实验设置。LQI和NMPC控制器是在MA TLAB R2017a平台上使用控制系统和MPC工具箱实现的。如上所述,水下机器人模型由水下机器人动力学(23a)–(23d)的S函数通过SIMULINK线性化。NNDPG由Python 2.7在Linux系统上使用Google的开源模块Tensorflow实现。
应该注意的是,所有的控制器和模型都是以离散时间形式实现的,采样时间 d t = 0.1 s d_t = 0.1 s dt=0.1s,尽管在前面的章节中,它们中的一些是在连续时间下描述的。例如,一般的水下机器人动力学(1)使用向前欧拉公式离散化
![]()
样本水平设置为T = 100秒。
扰动项ξ由Ornstein–Uhlenbeck过程产生[29]
![]()
其中, ε ε ε是符合标准正态分布的噪声项,其他参数设置为 μ = 0 , β = 0.15 , σ = 0.3 μ = 0,β = 0.15,σ = 0.3 μ=0,β=0.15,σ=0.3。请注意,这是一个时间相关的随机过程。
E.恒定深度控制的仿真结果
首先,我们将NNDPG与LQI和NMPC在恒定深度控制问题上的性能进行了比较。图9示出了三个控制器从初始深度 z 0 = 2.0 m z_0= 2.0 m z0=2.0m到目标深度 z r = 8.0 m z_r= 8.0 m zr=8.0m的跟踪行为。三个指标,稳态误差(SSE)、过冲(OS)和响应时间(RT),用于评估控制器的性能,其精确值在表2中给出。
![[论文]基于强化学习的无模型水下机器人深度控制_第17张图片](http://img.e-com-net.com/image/info8/389126fffc65474080025bf469eab18b.jpg)
![[论文]基于强化学习的无模型水下机器人深度控制_第18张图片](http://img.e-com-net.com/image/info8/dc385849e3004b6f8e6cf569c39246e0.jpg)
我们可以发现LQI在控制者中表现最差。这一结果表明,在不精确的模型下,基于模型的控制器的性能会恶化。
此外,仿真结果表明,基于理想的非线性水下机器人模型,神经网络动力定位系统的性能与NMPC相当,甚至以更快的收敛速度和更小的操作系统击败后者(表二中的粗体小数)。在未知水下机器人模型下,验证了该算法的有效性。
![[论文]基于强化学习的无模型水下机器人深度控制_第19张图片](http://img.e-com-net.com/image/info8/30faa7a665d84db682b65ae5e2114fdc.jpg)
图10示出了三个控制器的控制序列。NNDPG学习的控制策略比其他控制器变化更敏感。我们用神经网络的逼近误差来解释这一现象。LQI和NMPC可以获得更平滑的控制律函数,因为他们可以访问水下机器人的动力学方程。然而,神经网络(策略网络)用于生成NNDPG中的控制序列。因此,它可以看作是对未知动力学模型的一种补偿。
![[论文]基于强化学习的无模型水下机器人深度控制_第20张图片](http://img.e-com-net.com/image/info8/c0b18c6f707b4ff78ab3e59b81748179.jpg)
为了验证优先化经验回放的改进的数据效率,我们通过总回报的收敛过程将其性能与原始经验回放进行比较,如图11所示。我们发现具有优先经验回放的NNDPG比具有原始经验重放的NNDPG花费更少的收敛步骤,因为前者以更有效的方式重放先前的经验。
F.弯曲深度控制的仿真结果
在这一部分,水下机器人被控制以跟踪弯曲的深度轨迹。我们将跟踪轨迹设置为正弦函数 Z r = z r 0 s i n ( π / 50 x ) Z_r = z_{r0} sin(π/50 x) Zr=zr0sin(π/50x),其中 z r 0 = 10 {z_{r0}= 10 } zr0=10 m。首先,我们假设NNDPG具有轨迹的趋势信息,包括倾斜角及其导数,作为第三节中研究的弯曲深度控制的情况。然后在倾斜角不可测量的情况下对算法进行了验证。相反,测量的相对深度的先前历史序列 [ Δ z t − N , Δ z t − N + 1 , . . . , Δ z t − 1 , Δ z t ] [\Delta{z_{t-N}},\Delta{z_{t-N+1}},...,\Delta{z_{t-1}},\Delta{z_{t}}] [Δzt−N,Δzt−N+1,...,Δzt−1,Δzt]提供,其中序列的长度称为窗口大小。图12(a)和(b)示出了跟踪误差和轨迹,其中NNDPG-PI表示带有倾斜角信息的NNDGP算法,NNDPG-WIN-X表示与最近测量的X个相对深度有关的NNDPG。
![[论文]基于强化学习的无模型水下机器人深度控制_第21张图片](http://img.e-com-net.com/image/info8/d57e3be8e1c94c5f993bfd72ee8075b5.jpg)
首先,我们从图12中观察到,NNDPG-PI的性能与NMPC的性能相当,后者与恒定深度控制的情况相似。请注意,NMPC需要水下机器人的精确动力学,而我们的算法完全没有模型。另外,NNDPG-PI的性能是不同NNDPG版本中最好的,而NNDPG-WIN-1只包括当前相对深度的性能差很多。它验证了为恒定深度控制问题设计的状态对于弯曲深度设置变得部分可观察。然而,当我们将最近测量的相对深度添加到状态(NNDPG-WIN-3)时,跟踪误差大大减小。这种改善可以用包含在最新测量中的隐含趋势信息来解释。
为了确定窗口大小的最佳选择,我们列出并比较了不同窗口大小(从1到9)的NNDPG的性能。根据一个实验的长期成本来评估性能
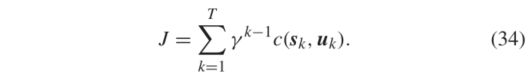
由于水下机器人动力学中存在干扰,我们对每个窗口大小进行了十次实验。结果在图13中显示为箱线图,以显示性能的分布。
![[论文]基于强化学习的无模型水下机器人深度控制_第22张图片](http://img.e-com-net.com/image/info8/f73687f621894424847cae56b8ba75bf.jpg)
可以清楚地看到,过去测量的相对深度的补充确实补偿了期望深度轨迹的缺失趋势信息。然而,这并不意味着越多越好。事实上,之前超过太多步骤的记录会降低性能,因为它们可能会干扰已学习的策略。从情节中我们发现窗口大小的最佳值是3,对应于最小均值和方差。
G.真实海底跟踪的仿真结果
最后,我们测试了所提出的用于跟踪真实海底的RL框架。数据集采样自南海海底 ( 23 ° 0 6 ′ N , 120 ° 0 7 ′ E ) (23\degree06'N,120\degree07'E) (23°06′N,120°07′E)由中国科学院沈阳自动化研究所提供。我们沿着预设路径对深度进行采样,获得图14所示的二维距离-深度海底曲线。
![[论文]基于强化学习的无模型水下机器人深度控制_第23张图片](http://img.e-com-net.com/image/info8/092cdc0cb7394132a869e5736429ce1d.jpg)
我们的目标是控制水下机器人跟踪海底曲线,同时保持恒定的安全距离。我们将NNDPG-WIN-3与NMPC的性能做比较,如图15所示。似乎两个控制器都可以很好地跟踪海底的快速变化趋势,但是我们的算法不需要水下机器人的动力学。
![[论文]基于强化学习的无模型水下机器人深度控制_第24张图片](http://img.e-com-net.com/image/info8/9d7e11d7670d4d80a0a80b4335cbfb6e.jpg)
结论
针对水下机器人在离散时间的深度控制问题,提出了一种无模型RL框架。研究了三个不同的深度控制问题,并将其建模为具有设计良好的状态和单步代价函数的多目标规划。提出了一种学习状态反馈控制器的反向学习算法NNDPG,该控制器由一个称为策略网络的神经网络表示。策略网络的权重由DPG定理计算的近似策略梯度更新,而另一个评估网络用于估计状态-动作值函数,并由时域算法更新。两个网络的交替更新由NNDPG的一个迭代步骤组成。为了提高收敛性,提出了优先经验回放来回放以前的经验以训练网络。
我们在一个经典的REMUS水下机器人模型上测试了所提出的无模型RL框架,并与两个基于模型的控制器进行了性能比较。结果表明,在水下机器人的精确动力学条件下,神经网络预测控制策略的性能可以与控制器的性能相媲美。此外,我们发现所选状态的可观测性影响性能,并且可以添加最近的历史来提高性能。
未来,我们将在一个真实的水下航行器上验证所提出的无模型RL框架,该水下航行器是一个在海平面下6000米处工作的深海可控视觉采样器。
原文链接