论文阅读”Ada-nets: Face clustering via adaptive neighbour discovery in the structure space“
论文标题
Ada-nets: Face clustering via adaptive neighbour discovery in the structure space
论文作者、链接
作者:Wang, Yaohua and Zhang, Yaobin and Zhang, Fangyi and Wang, Senzhang and Lin, Ming and Zhang, YuQi and Sun, Xiuyu
链接:https://arxiv.org/abs/2202.03800
代码:GitHub - damo-cv/Ada-NETS: This is an official implementation for "Ada-NETS: Face Clustering via Adaptive Neighbour Discovery in the Structure Space" accepted at ICLR 2022.
Introduction逻辑(论文动机&现有工作存在的问题)
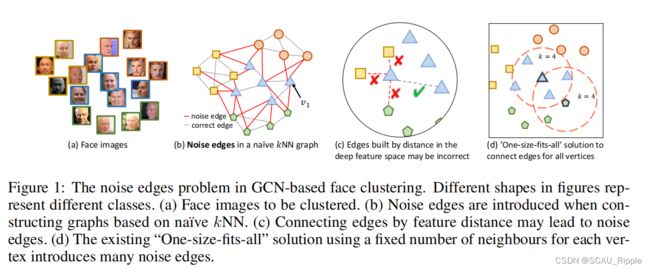
现在网络上充斥大量的图像数据,如何从中无监督的选出人脸数据——通过GCN来对人脸数据进行聚类——但是,限制GCN的脸聚类算法的主要问题在于:图谱中存在有噪声的边,这导致两连的两个点可能分属于不同的两个类,传递了错误的信息——与通用的图数据集(Citeseer,Cora,Pubmed)不同,人脸数据并没有很精确的结构信息,只有从CNN中提取的特征——将人脸图像作为顶点,然后人脸图像之间的边缘通常基于kNN构造人脸图谱,每个人脸作为一个探针,通过深度特征检索k个最近的邻居——但是,KNN的连接关系不一定靠谱,因为学到的特征并不是很准确——移除有噪音边的两个主要问题:(1)深度特征的表示能力收到真实世界的数据的限制,仅凭两个顶点的深度特征很难判断它们是否属于同一类(2)在构建图时很难确定每个顶点连接多少条边,连接边太少会导致图中信息不足,边连接太多会带来大量的噪音边。——考虑到附近的其他顶点,每个顶点的特征表示都可以得到改进——解决方法:(1)将每个顶点的特征都纳入考虑,以考虑更全面的信息(2)一个顶点和其他顶点之间的边的数量可以通过它周围的特征来学习,而不是手动为所有顶点设计参数
论文核心创新点
解决GCN图谱构建中的噪声边的问题
相关工作
脸聚类:往往使用KNN构建图谱,导致有含噪的边出现,然后在根据特征计算结点相似性的时候便不是那么准确,并且每个结点的所连的数量是固定的。
图卷积网络:在含噪声的边的图谱上,GCN的表现不佳。
论文方法
给定一组从脸图像数据中提取出的特征向量的集合![]() ,聚类任务的目标是对每一个向量
,聚类任务的目标是对每一个向量 分配一个组标签,
分配一个组标签, 是样本总数,
是样本总数, 是特征维度。Ada-NETS首先将特征转换到本文提出的结构空间,用来找邻居结点,根据找邻居
是特征维度。Ada-NETS首先将特征转换到本文提出的结构空间,用来找邻居结点,根据找邻居
结构空间structure space
噪音边的问题会污染结点特征,并且很难通过结点特征去决定该点属于哪个类,因为在含噪的情况下,两个非同类的结点也会有高相关性的特征。其实可以通过邻居结点带来的结构化信息去优化相似性尺度。
在结构空间中,特征可以通过感知数据的分布,从而编码更多的语义信息。一个将特征![]() 转换到结构空的
转换到结构空的![]() ,转换函数
,转换函数 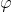 定义如下:
定义如下:
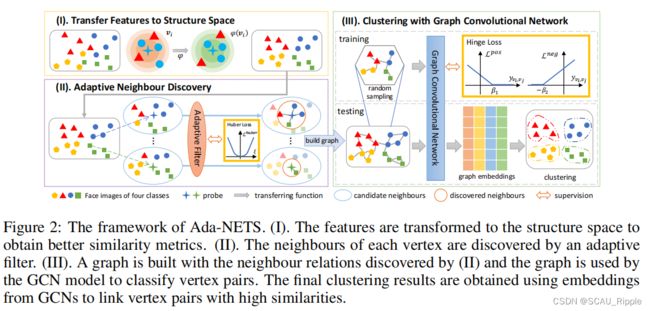
如图2(I)所示,在结构空间的帮助下,对于![]() 与其他顶点的相似性计算由以下四步构成:
与其他顶点的相似性计算由以下四步构成:
(1)通过基于余弦相似性的近似最近邻算法(Approximate Nearest-neighbour ,ANN)对![]() 计算KNN,记作
计算KNN,记作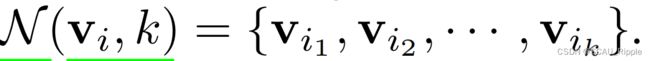
(2)由核方法(kernel method)启发,相比起直接解决的结构问题,本文对![]() 在结构空间的候选集中的样本的相似性定义如下:
在结构空间的候选集中的样本的相似性定义如下:
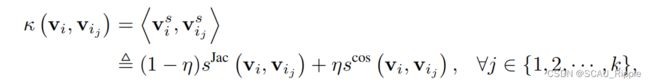
其中, 是参数,
是参数,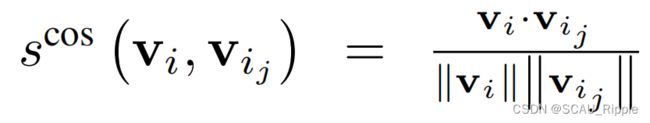 以及由基于共同邻居的尺度(common-neighbour-based metric)启发的Jaccard相似性(Jaccard similarity)
以及由基于共同邻居的尺度(common-neighbour-based metric)启发的Jaccard相似性(Jaccard similarity)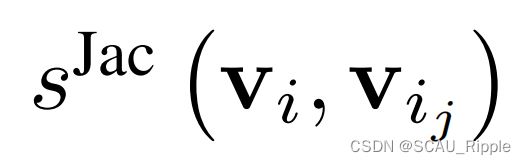 。该公式衡量了两个结点在结构空间的相似性。
。该公式衡量了两个结点在结构空间的相似性。
自适应邻居探索
现有方法往往根据深度特征或者使用固定的相似性阈值,来构建KNN关系。这些方法受超参影响很大。本文设计了自适应邻居探索模块,来从顶点周围的特征模式来寻找邻居,如图2(II)所示。对于顶点![]() ,其基于特征相似性选择的
,其基于特征相似性选择的 个最近邻居点构成大小为的候选邻居(candidate neighbors),其中
个最近邻居点构成大小为的候选邻居(candidate neighbors),其中![]() ,候选邻居由一个特别的尺度来衡量
,候选邻居由一个特别的尺度来衡量
候选邻居质量标准
由顶点置信度评估方法(vertex confidence estimation method)启发,一种启发式的衡量标准被设计出来用于评估候每个顶点的选邻居的质量。好的邻居应该是”干净的“,即大多数邻居应该有相同的类别,这样噪音边的影响会比较小。邻居点也应该尽可能多,这样可以带来更多的信息。为了满足这两个原则,一个基于![]() 的判别标准被设计出来,所有的邻居根据相似性按顺序排列。给出顶点
的判别标准被设计出来,所有的邻居根据相似性按顺序排列。给出顶点![]() 探测到的个候选邻居,那么其质量判别标准
探测到的个候选邻居,那么其质量判别标准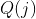 如下
如下
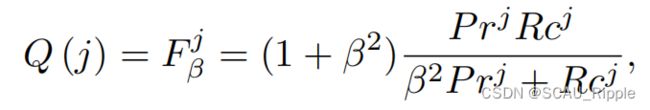
其中![]() 和
和![]() 是顶点
是顶点![]() 的前个候选邻居的准确和召回,
的前个候选邻居的准确和召回, 是用来平衡准确和召回的权重的参数。
是用来平衡准确和召回的权重的参数。 得分越高说明候选邻居质量越好。
得分越高说明候选邻居质量越好。
自适应滤波器
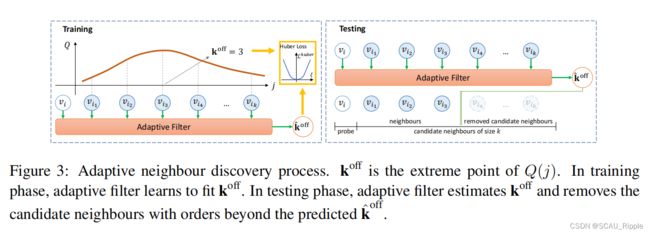
有了上面的标准后,对于邻居的选择如下:![]()

如图3所示,自适应滤波器通过在的曲线上找到取值最高的值来评估。自适应的滤波器的输入为特征向量![]() 。在训练过程中,给定一个mini-batch的
。在训练过程中,给定一个mini-batch的 序列,自适应滤波器通过Huber loss进行训练:
序列,自适应滤波器通过Huber loss进行训练:
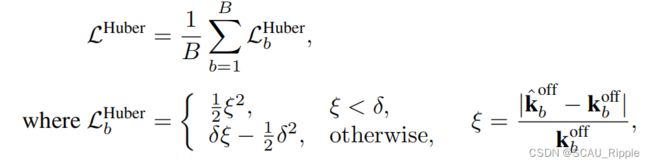
其中![]() 是
是![]() 的预测结果,
的预测结果,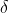 是离群值阈值(outlier threshold)。对于每一个
是离群值阈值(outlier threshold)。对于每一个![]() ,其排序过后的候选邻居点(在删除了
,其排序过后的候选邻居点(在删除了![]() 之后),会视为其探知到的邻居点。这个自适应滤波器是由一个双向LSTM和两个全连接层构成。
之后),会视为其探知到的邻居点。这个自适应滤波器是由一个双向LSTM和两个全连接层构成。
针对脸聚类的Ada-NETS
为了有效定位脸聚类中的噪声边的问题,Ada-NETS首先利用提出的结构空间和自适应邻居探索,来构建带有干净而又丰富的边的图谱。最后使用GCN来完成聚类任务如图2(III)所示。与结构空间和自适应邻居探索的尺度相似,将![]() 的邻居记作
的邻居记作![]() :
:

其中![]() 代表根据相似性
代表根据相似性![]() 降序排列的
降序排列的![]() 编号。基于这些邻居关系,构建一个无向图
编号。基于这些邻居关系,构建一个无向图![]() 。
。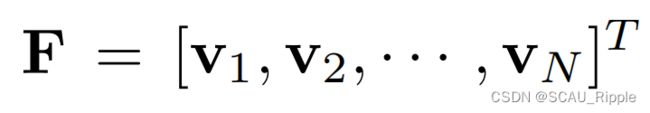 是顶点特征矩阵,然后
是顶点特征矩阵,然后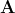 是邻接矩阵:
是邻接矩阵:
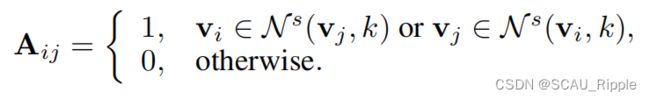
根据构建的图谱![]() ,用一个GCN模型来学习是否两个结点同属于一个类。GCN的一层定义如下:
,用一个GCN模型来学习是否两个结点同属于一个类。GCN的一层定义如下:
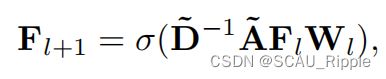
其中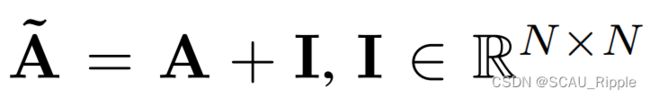 是一个单位矩阵
是一个单位矩阵![]() 是对角度矩阵,有
是对角度矩阵,有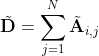 。
。![]() 和
和![]() 分别是属于的特征矩阵和第
分别是属于的特征矩阵和第 层的权重矩阵,
层的权重矩阵, 是一个激活函数。本文使用了一个两层的GCN层,后接一个FC层带PReLU激活函数和一个正则化层。对于随机采样的一个batch,训练损失是根据Hinge loss修改出来的版本:
是一个激活函数。本文使用了一个两层的GCN层,后接一个FC层带PReLU激活函数和一个正则化层。对于随机采样的一个batch,训练损失是根据Hinge loss修改出来的版本:

其中![]() 代表GCN输出的顶点
代表GCN输出的顶点![]() 和
和![]() 对应的特征
对应的特征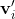 和
和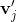 的余弦相似性。
的余弦相似性。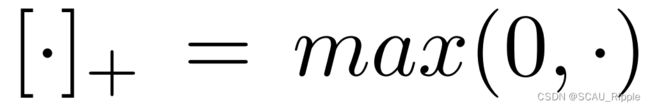 ,
, 是正样本的数量,
是正样本的数量, 和
和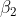 是正/负损失的边缘,
是正/负损失的边缘, 是平衡正负损失的参数。
是平衡正负损失的参数。
推理过程中,整个图谱都都被输入到GCN去获得所有样本的增强特征![]() ,其中
,其中![]() 是新特征的维度。当两个顶点的相似性分数超过阈值,那么两个点就会被链接起来。
是新特征的维度。当两个顶点的相似性分数超过阈值,那么两个点就会被链接起来。
消融实验设计
结构空间和自适应邻居探索的研究
提出的邻居质量判别标准
自适应滤波器
超参敏感度
对图嵌入的研究
一句话总结
核心是构建一个邻居点的候选集,然后对候选集进行排序,对排名靠前的与顶点进行相似性计算,其实感觉本身和人脸没什么关系。
论文好句摘抄(个人向)
(1)Understanding and managing these photos with little human involvement are demanding, such as associating together photos from a certain person.
(2)thus resulting in inferior performance
(3)Face clustering aims to divide a set of face samples into groups so that samples in a group belong to one identity, and any two samples in different groups belong to different identities
(4)The noise edges problem will lead to the pollution of vertices features, degrading the performance of GCN-based clustering.