ccc-sklearn-17-XGBoost(3)
文章目录
-
-
-
- XGBoost的应用中的问题
-
- 1.过拟合:剪枝参数与回归模型调参
- 2.默认参数下交叉验证曲线
- 3.通过剪枝与对比来展示参数调节的结果
- 4.XGBoost模型的保存与调用
-
- pickle保存
- pickle调用
- Joblib保存
- Joblib调用
- 5.XGBoost中样本不均衡的问题
- 6.XGBoost类中其他功能以及参数
-
-
XGBoost的应用中的问题
1.过拟合:剪枝参数与回归模型调参
上一篇中的复杂度控制 γ \gamma γ,正则化参数 λ \lambda λ和 α \alpha α,控制迭代速度的参数 η \eta η,管理迭代前进的随机有放回参数subsample都可以用来减轻过拟合。除此之外还有几个专用剪枝的参数:
| 参数含义 | xgb.train() | xgb.XGBRegressor() |
|---|---|---|
| 树的最大深度 | max_depth,默认6 | max_depth,默认6 |
| 每次生成树时随机抽样特征的比例 | colsample_bytree,默认1 | colsample_bytree,默认1 |
| 每次生成树的一层时随机抽样特征的比例 | colsample_bylevel,默认1 | colsample_bylevel,默认1 |
| 每次生成一个叶子节点时随机抽样特征的比例 | colsample_bynode,默认1 | N.A. |
| 叶子节点上的二阶导数之-类似于样本权重 | min_child_weight,默认1 | min_child_weight,默认1 |
注意事项:
- XGBoost中最大深度与参数 γ \gamma γ类似,一般使用其中一个即可
- 三个随机抽样特征通常使用前两个。实践证明纵向抽样(抽取特征)比横向抽样(抽取样本)更加能防止过拟合
- 对于最后一个参数,本质上是在控制叶子上所需的最小样本量,因此对于样本量很大的数据效果会比较好,通常不会作为优先选择
- 对于一个数据集通常先使用网格搜索找出比较适合的n_estimator和eta组合,然后使用gamma或者max_depeh观察,最后决定剪枝
2.默认参数下交叉验证曲线
param1 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"max_depth":6
,"eta":0.3
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":1
,"nfold":5}
num_round = 200
time0 = time()
cvresult = xgb.cv(param1,dfull,num_round)
print(datetime.datetime.fromtimestamp(time()-time0,pytz.timezone('UTC')).strftime("%M:%S:%f"))
fig,ax = plt.subplots(1,figsize=(15,10))
ax.grid()
ax.plot(range(1,201),cvresult.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,201),cvresult.iloc[:,2],c="orange",label="test,original")
ax.legend(fontsize="xx-large")
plt.show()
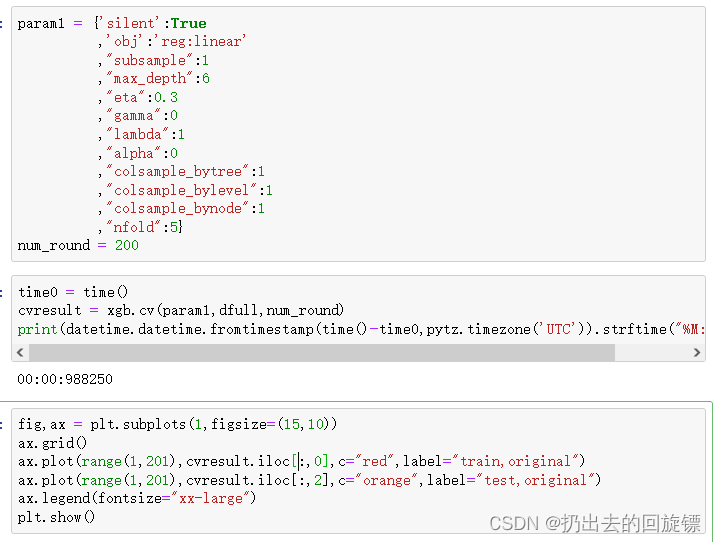
模型处于过拟合
3.通过剪枝与对比来展示参数调节的结果
param1 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"max_depth":6
,"eta":0.3
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":1
,"nfold":5}
num_round = 200
time0 = time()
cvresult1 = xgb.cv(param1, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0,pytz.timezone('UTC')).strftime("%M:%S:%f"))
fig,ax = plt.subplots(1,figsize=(15,8))
ax.set_ylim(top=5)
ax.grid()
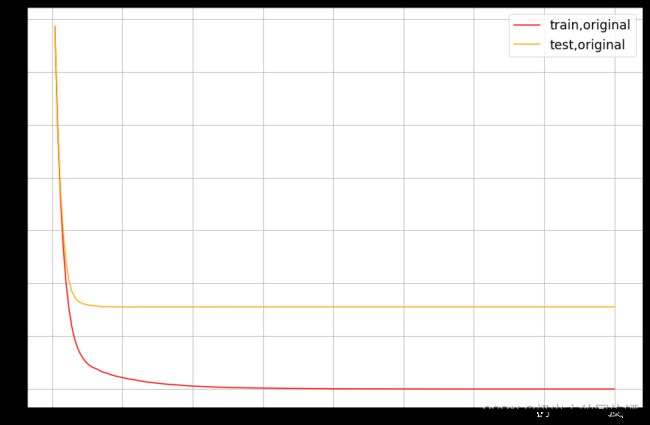
ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")
param2 = {'silent':True
,'obj':'reg:linear'
,"max_depth":2
,"eta":0.05
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":0.4
,"colsample_bynode":1
,"nfold":5}
param3 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"eta":0.05
,"gamma":20
,"lambda":3.5
,"alpha":0.2
,"max_depth":4
,"colsample_bytree":0.4
,"colsample_bylevel":0.6
,"colsample_bynode":1
,"nfold":5}
time0 = time()
cvresult2 = xgb.cv(param2, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0,pytz.timezone('UTC')).strftime("%M:%S:%f"))
time0 = time()
cvresult3 = xgb.cv(param3, dfull, num_round)
print(datetime.datetime.fromtimestamp(time()-time0,pytz.timezone('UTC')).strftime("%M:%S:%f"))
ax.plot(range(1,201),cvresult2.iloc[:,0],c="green",label="train,last")
ax.plot(range(1,201),cvresult2.iloc[:,2],c="blue",label="test,last")
ax.plot(range(1,201),cvresult3.iloc[:,0],c="gray",label="train,this")
ax.plot(range(1,201),cvresult3.iloc[:,2],c="pink",label="test,this")
ax.legend(fontsize="xx-large")
plt.show()
调参的几个注意事项:
- xgboost.cv可以用来确认参数范围,一般不要放入太多参数。相互影响的参数需要一起使用,比如eta和n_estimators
- 调参时候参数修改的顺序会对结果有影响,一般优先调整对模型影响大的参数
- 泛化能力的提升不代表新数据集上模型结果一定优秀。如果调参后交叉曲线显示测试集和训练集上的模型评估效果更加接近,推荐使用调参后的效果。
4.XGBoost模型的保存与调用
XGBoost参数繁多,调参复杂。训练好后的模型需要及时保存方便后续操作
pickle保存
python中标准的保存和调用模型的库,使用pickle和open函数将模型保存到本地
import pickle
dtrain = xgb.DMatrix(Xtrain,Ytrain)
param = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"eta":0.05
,"gamma":20
,"lambda":3.5
,"alpha":0.2
,"max_depth":4
,"colsample_bytree":0.4
,"colsample_bylevel":0.6
,"colsample_bynode":1}
num_round = 180
bst = xgb.train(param, dtrain, num_round)
pickle.dump(bst,open("xgboost130.dat","wb"))#wb表示二进制写入
import sys
sys.path#查看保存路径
pickle调用
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import mean_squared_error as MSE,r2_score
import pickle
import xgboost as xgb
data = load_boston()
X = data.data
y = data.target
Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)
dtest = xgb.DMatrix(Xtest,Ytest)
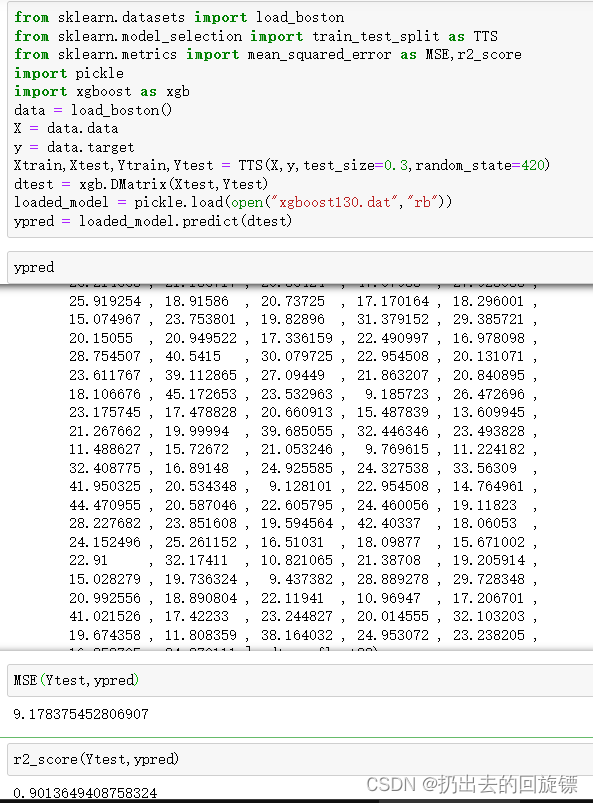
loaded_model = pickle.load(open("xgboost130.dat","rb"))
ypred = loaded_model.predict(dtest)
MSE(Ytest,ypred)
r2_score(Ytest,ypred)
Joblib保存
属于SciPy生态,为python提供保存和调用管道和对象的功能,处理Numpy结构的数据非常高校,用于巨大的数据集
import joblib
joblib.dump(bst,"xgboost-boston130.dat")
Joblib调用
import joblib
loaded_model = joblib.load("xgboost-boston130.dat")
ypreds = loaded_model.predict(dtest)
MSE(Ytest,ypreds)
r2_score(Ytest,ypreds)

2个文件导出如下
5.XGBoost中样本不均衡的问题
类似于随机森林和支持向量机中使用过的class_weight参数,通常参数中输入的是负样本量和正样本量之比 s u m ( n e g a t i v e i n s t a n c e s ) s u m ( p o s i t i v e i n s t a n c e s ) \frac{sum(negative\ instances)}{sum(positive\ instances)} sum(positive instances)sum(negative instances)
| 参数含义 | xgb.train() | xgb.XGBClassifier() |
|---|---|---|
| 控制正负样本比例,表示为负/正样本比例 样本不平衡问题中使用 |
scale_pos_weight,默认1 | scale_pos_weight,默认1 |
第一步:导库以及数据集的创建
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
from xgboost import XGBClassifier as XGBC
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import confusion_matrix as cm, recall_score as recall, roc_auc_score as auc
class_1 = 500
class_2 = 50
centers = [[0.0, 0.0], [2.0, 2.0]]
clusters_std = [1.5, 0.5]
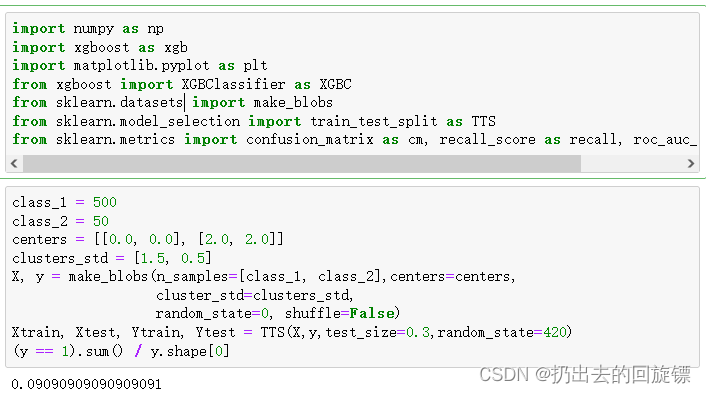
X, y = make_blobs(n_samples=[class_1, class_2],centers=centers,
cluster_std=clusters_std,
random_state=0, shuffle=False)
Xtrain, Xtest, Ytrain, Ytest = TTS(X,y,test_size=0.3,random_state=420)
(y == 1).sum() / y.shape[0]
第二步:sklearn中进行建模探索
#调整scale_pos_weight前
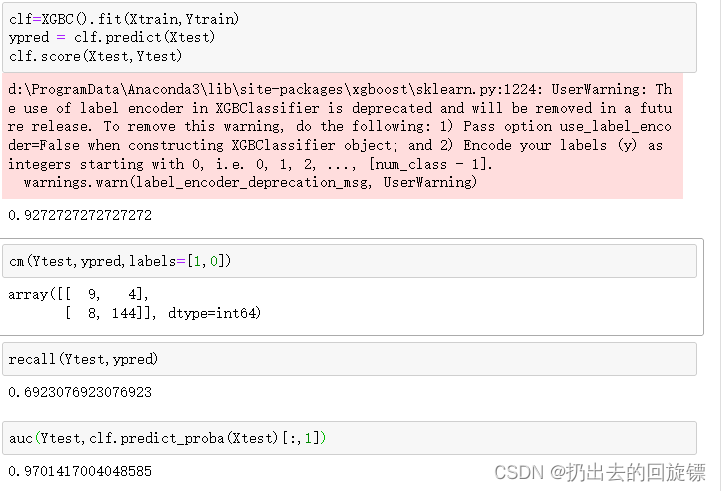
clf=XGBC().fit(Xtrain,Ytrain)
ypred = clf.predict(Xtest)
clf.score(Xtest,Ytest)
cm(Ytest,ypred,labels=[1,0])
recall(Ytest,ypred)
auc(Ytest,clf.predict_proba(Xtest)[:,1])
#调整scale_pos_weight后
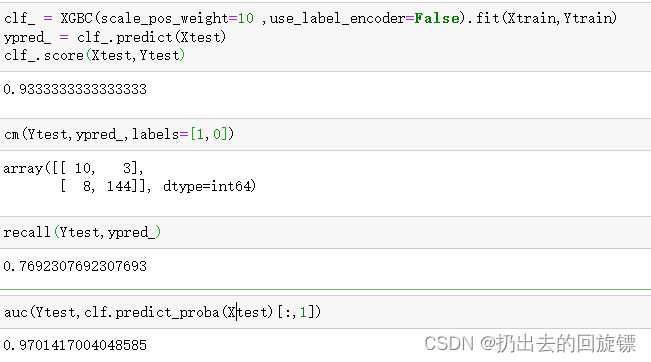
clf_ = XGBC(scale_pos_weight=10 ,use_label_encoder=False).fit(Xtrain,Ytrain)
ypred_ = clf_.predict(Xtest)
clf_.score(Xtest,Ytest)
cm(Ytest,ypred_,labels=[1,0])
recall(Ytest,ypred_)
auc(Ytest,clf.predict_proba(Xtest)[:,1])
#不同样本权重,模型状态变化
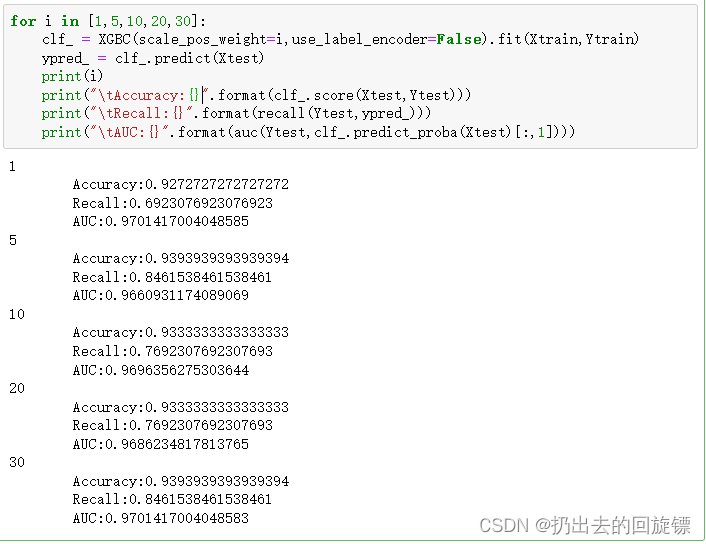
for i in [1,5,10,20,30]:
clf_ = XGBC(scale_pos_weight=i,use_label_encoder=False).fit(Xtrain,Ytrain)
ypred_ = clf_.predict(Xtest)
print(i)
print("\tAccuracy:{}".format(clf_.score(Xtest,Ytest)))
print("\tRecall:{}".format(recall(Ytest,ypred_)))
print("\tAUC:{}".format(auc(Ytest,clf_.predict_proba(Xtest)[:,1])))
第三步:xgboost中建模
#查看初始predict接口
dtrain = xgb.DMatrix(Xtrain,Ytrain)
dtest = xgb.DMatrix(Xtest,Ytest)
param= {'silent':True,'objective':'binary:logistic',"eta":0.1,"scale_pos_weight":1}
num_round = 100
bst = xgb.train(param, dtrain, num_round)
preds = bst.predict(dtest)
preds
#导入模型评估指标,设定阈值和参数
from sklearn.metrics import accuracy_score as accuracy, recall_score as recall, roc_auc_score as auc
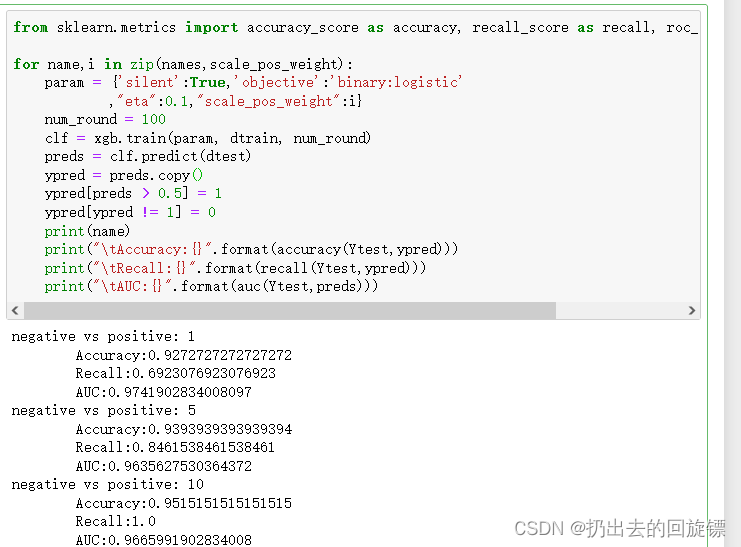
for name,i in zip(names,scale_pos_weight):
param = {'silent':True,'objective':'binary:logistic'
,"eta":0.1,"scale_pos_weight":i}
num_round = 100
clf = xgb.train(param, dtrain, num_round)
preds = clf.predict(dtest)
ypred = preds.copy()
ypred[preds > 0.5] = 1
ypred[ypred != 1] = 0
print(name)
print("\tAccuracy:{}".format(accuracy(Ytest,ypred)))
print("\tRecall:{}".format(recall(Ytest,ypred)))
print("\tAUC:{}".format(auc(Ytest,preds)))
#不同阈值下模型状态
for name,i in zip(names,scale_pos_weight):
for thres in [0.3,0.5,0.7,0.9]:
param= {'silent':True,'objective':'binary:logistic'
,"eta":0.1,"scale_pos_weight":i}
clf = xgb.train(param, dtrain, num_round)
preds = clf.predict(dtest)
ypred = preds.copy()
ypred[preds > thres] = 1
ypred[ypred != 1] = 0
print("{},thresholds:{}".format(name,thres))
print("\tAccuracy:{}".format(accuracy(Ytest,ypred)))
print("\tRecall:{}".format(recall(Ytest,ypred)))
print("\tAUC:{}".format(auc(Ytest,preds)))
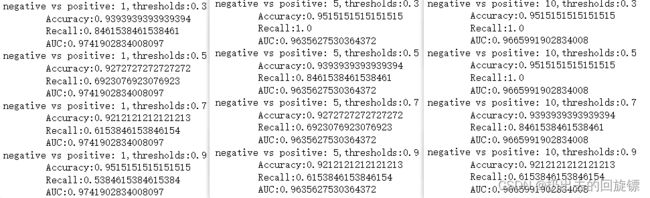
可以看到,不管是xgboost还是sklearnAPI中,参数scale_pos_weight都比较有效。它本质是调节预测的概率值。如果只在意预测出正确的概率,则无法通过调节scale_pos_weight来减轻样本不平衡带来的影响。这时需要考虑另一个参数:max_delta_step(树的权重估计中允许的单次最大增量),xgboost官网解释如下:

6.XGBoost类中其他功能以及参数
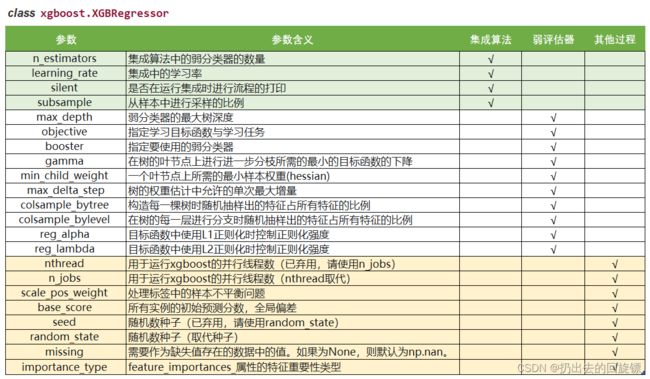
更多计算资源:n_jobs
nthread和n_jobs都是算法运行所使用的线程,与sklearn中规则一样,输入整数表示使用的线程,输入-1表示使用计算机全部的计算资源
降低学习难度:base_score
base_score是容易被混淆的参数,叫做全局偏差,分类问题中,它是关注的分类的先验概率。如1000个样本,其中300个正样本,700个负样本,base_score就是0.3。对于回归,默认0.5,其实base_score的默认应该是标签的均值,不过xgboost库尚未对此做出改进。这个参数是在告诉模型已经了解但模型不一定能够从数据中学习到的信息。对于严重的样本不均衡问题,设置一个正确的base_score取值是很有必要的
生成树的随机模式:random_state
xgb库和sklearn库中,在random_state参数中输入同一个整数未必表示同一个随机模式,不一定会得到相同的结果,因此导致模型的feature_importances也会不一致
自动处理缺失值:missing
XGBoost被设计成是能够自动处理缺失值的模型,这个设计的初衷其实是为了让XGBoost能够处理稀疏矩阵。可以在参数missing中输入一个对象,比如np.nan,或数据的任意取值,表示将所有含有这个对象的数据作为空值处理。XGBoost会将所有的空值当作稀疏矩阵中的0来进行处理,也可以不处理缺失值。如果了解业务并且了解缺失值的来源,还是希望手动填补缺失值。