【含课程pdf & 测验答案】吴恩达-机器学习公开课 学习笔记 Week1-1 Introduction
吴恩达-机器学习公开课 学习笔记 Week1-1 Introduction
- 1-1 Introduction课程内容
-
- 1-1-1 Welcome
- 1-1-2 What is Machine Learning?
-
- 机器学习的定义
- 学习算法主要的两种类型
- 1-1-3 Supervised Learning
-
- 监督学习的定义
- 总结
- 简单测试
- 1-1-4 Unsupervised Learning
-
- 鸡尾酒会算法
- 简单测试
- 总结
- 1-1 Review
-
-
- Lecture1.pdf
- 测验
-
- 课程链接
1-1 Introduction课程内容
此文为Week1 中Introduction的部分。主要内容相当于绪论,大概的介绍了机器学习的基本概念和相关定义。
- 目的:对机器学习有大概的了解
1-1-1 Welcome
简单介绍,例举了一些生活中运用机器学习的例子(搜索引擎、垃圾邮件过滤器),以及时代背景——有用有钱快学吧
1-1-2 What is Machine Learning?
第一个知识点来啦——
机器学习的定义
一个程序被认为能从经验E中学习,解决任务 T,达到 性能度量值P,当且仅当,有了经验E后,经过P评判, 程序在处理 T 时的性能有所提升。
给一个例子帮助理解:
一个西洋棋菜鸟程序员通过编程,让西洋棋程序自己跟自己下了上万盘棋。通过观察 哪种布局(棋盘位置)会赢,哪种布局会输, 久而久之,这西洋棋程序明白了什么是好的布局, 什么样是坏的布局。然后就牛逼大发了,程序通过学习后, 玩西洋棋的水平超过了程序员。
=============
经验e: 程序上万次的自我练习的经验
任务 t :下棋
性能度量值 p:它在与一些新的对手比赛时,赢得比赛的概率。
学习算法主要的两种类型
目前的学习算法主要分为两种——监督学习和无监督学习。
1-1-3 Supervised Learning
监督学习的定义
eg1 【回归问题】房价的预测
通过收集的数据(红叉),依据直线(紫线)or平方函数(蓝线),对于一个新房子的房价(绿色)的预测?这其实是个回归问题。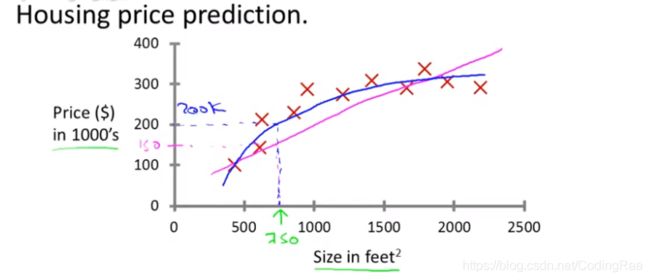
此处引入监督学习概念:
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output.
监督学习,指已给出一个已知正确输出的数据集,得出输出输入之间关系。
eg2 【分类问题】肿瘤性质预测(一个特征)
假设在数据集中,横轴是肿瘤的大小,在纵坐标轴上1或0,也就是或否。
由于只有一个特征——肿瘤大小。把数据集放在一条直线上面,把它映射到这条直线上,开始使用不同的符号——圆圈和十字表示恶性和良性的例子。

这里我们就讨论到了分类。
eg3 肿瘤性质预测(两个特征)
现在设想有两个特征——肿瘤大小&病人年龄。算法给出一条线来分类良性恶性,以此预测病人良性恶性概率。

实际上会用到更多特征,甚至是无穷多。当我们讨论一种叫做支持向量机的算法时,会有一个简洁的数学技巧 允许计算机处理无限多的特性。
总结
- 监督学习强调需要一个已知正确答案的数据集。
- 监督学习问题分为回归和分类的问题。
- 在一个回归的问题,我们试图预测结果在一个连续的输出,这意味着我们正试图将输入变量映射到一些连续函数。
- 在一个分类问题,我们不是试图预测结果在一个离散输出。换句话说,我们正试图将输入变量映射到离散的类别。
简单测试

1-1-4 Unsupervised Learning
上次的数据集, 每个样本都已经被标明为正样本或者负样本,即良性或恶性肿瘤。在无监督学习中没有属性或标签这一概念,也就是说所有的数据都是一样的 没有区别。 所以在无监督学习中,我们只有一个数据集,没人告诉我们该怎么做,我们也不知道,每个数据点究竟是什么意思。相反,它只告诉我们,现在有一个数据集,你能在其中找到某种结构吗?
无监督学习算法会把这些数据分成两个不同的聚类。这就是所谓的聚类算法。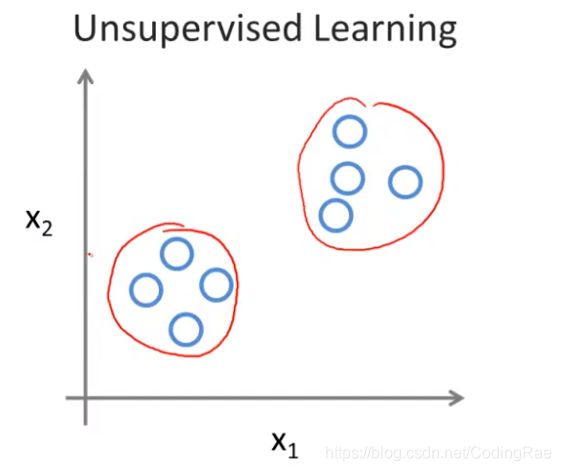
我们来举一个聚类算法的栗子——Google 新闻的例子。他们每天会去收集成千上万的网络上的新闻,然后将他们分组 组成一个个新闻专题。 因此,有关同一主题的新闻被显示在一起。
它还有各种不同的应用。
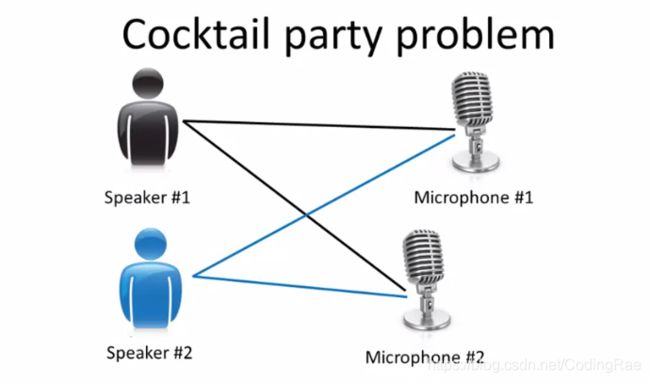
鸡尾酒会算法
有这样一个场景,宴会上只有两个人,两个人同时说话。我们准备好了两个麦克风,把它们放在房间里。然后,因为这两个麦克风距离这两个人的距离是不同的,每个麦克风都记录下了来自两个人的声音的不同组。也许A的声音在第一个麦克风里的声音会响一点,也许B的声音在第二个麦克风里会比较响一些 ,因为2个麦克风的位置相对于2个说话者的位置是不同的 ,但每个麦克风都会录到来自两个说话者的重叠部分的声音。
所以 我们能做的就是把 这两个录音输入一种无监督学习算法中——称为“鸡尾酒会算法”。让这个算法帮你找出其中蕴含的分类 ,然后这个算法就会去听这些 录音 。此外,这个算法还会分离出这两个被叠加到一起的音频源。在这里,这是个非聚类算法。
也许你想问,要实现这样的算法很复杂吧?实际上, 只需要一行代码就可以了。这里,老师就开始疯狂安利一个编程环境——Octave。Octave是一个免费的开放源码的软件 使用Octave或Matlab这类的工具,许多学习算法都可以用几行代码就可以实现。别问,用就对了。当然,你也可以去看视频,老师也讲了很多它的好处,此文就不赘述。
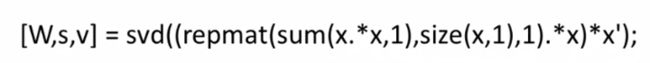
简单测试

总结
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
无监督学习允许在很少或不知道我们的结果应该是什么样子的情况下解决问题。我们可以在不一定知道变量的影响的情况下,从数据得出结构。
我们可以通过基于数据中变量的关系来聚类,以此推导结构。
无监督学习下,预测结果是没有反馈的。
聚类算法:一组1000000个不同的基因,这些基因,找到一个方法来自动组分组相似或相关的不同的变量,如寿命、位置、角色,等等。
非聚类算法:“鸡尾酒会”,让你可以找到结构在混乱的环境中。(即识别个人的声音和音乐网在鸡尾酒会上的声音)。
1-1 Review
Lecture1.pdf
此次课程幻灯片资源:
链接:https://pan.baidu.com/s/1M0PGPcDEM6lZ6ZK9NAnUEA
提取码:qt01
测验



【第4题为易错题注意!!!】


课程链接
https://www.coursera.org/learn/machine-learning/home/week/1