WSDM 2022 | 一种用于在线广告自动竞价的协作竞争多智能体框架
丨目录:
· 摘要
· 背景
· 基础概念
· IL的行为分析
· 我们的方法
· 实验
· 总结
· 参考文献
▐ 摘要
在在线广告中,自动竞价已经成为广告主优化自身广告性能的必需工具,自动竞价允许广告主通过简单地设置计划目标以及相应约束来优化其关心的广告性能指标。之前的工作大多从单智能体的角度考虑自动竞价问题,少有考虑建模智能体之间的相互影响。本文从分布式多智能体系统的角度研究自动竞价智能体的设计问题,并提出了一个通用的多智能体自动竞价框架,称为MAAB(Multi-Agent Auto-bidding),用以学习自动竞价策略。首先,我们研究自动竞价智能体之间的竞争与合作关系,并提出了一种基于温度调控的奖励分配机制来建立自动竞价智能体之间的混合协作竞争关系。通过调节竞价智能体之间的协作与竞争,从而达到了一种能够同时保证广告主自身效用和社会福利最大化的均衡状态。其次,我们观察到协作关系会引导智能体走向共谋出低价的行为模式,从而破坏平台生态。为了解决这个问题,我们引入了门槛智能体来为每一个自动竞价智能体设置一个个性化的竞价门槛。第三,为了将MAAB部署到拥有数百万广告主的大型广告系统中,我们提出了一种基于平均场方法,通过将目标相同的广告主分组为一个均值自动竞价智能体,广告主之间的复杂交互得以简化,从而使MAAB得以高效训练。在工业离线数据集以及阿里巴巴广告平台的实验表明,本文的方法在社会福利以及平台收入上能够超越基准算法。
论文下载:https://arxiv.org/pdf/2106.06224.pdf
▐ 背景
在线广告已经成为广告主提高其产品曝光机会的一种不可或缺的工具。在传统的广告拍卖中,广告主需要对每一次广告拍卖进行手动出价,然而这种细粒度的出价过程需要广告主对参竟环境有全面的了解。为减轻广告主的竞价优化负担,在线平台部署了各种类型的自动出价服务,例如谷歌的 AdWords 广告活动管理工具、百度的凤巢以及淘宝的超级推荐产品。这些服务使得广告主可以通过简单地表达其目标和约束,然后由自动出价智能体优化其广告效果。在线广告的自动出价的过程如下图所示:
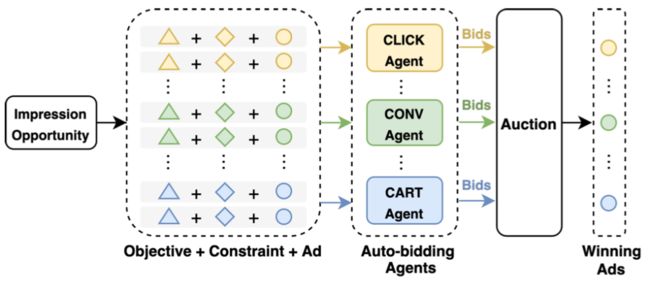
其中自动出价智能体由广告平台负责设计,该智能体目标是在广告主设置的约束下,根据广告主设置的目标来优化其出价策略。在阿里妈妈超级推荐&引力魔方上存在多种诉求,大体可以分为三类:优化点击、优化成交和优化收藏加购。这些自动出价智能体之间存在相互竞争关系。为了学习自动竞价智能体的竞价策略,最自然的方式就是去为每一个自动竞价智能体求解一个独立的优化问题,而将其他智能体出价的影响隐式地建模为环境的一部分。然而这种方式忽略了拍卖机制本质上是一个多智能体系统,即最终的拍卖结果取决于所有智能体的出价,且任一智能体的策略的改变会影响到其他所有智能体的策略。因此若不做任何的协调,则所有智能体会处于一个无约束状态,进而降低系统的整体效果。因此我们希望构建一个多智能体框架,通过精心设计协作机制来引导智能体走向一个具有较好系统性能的均衡状态。然而这面临以下几个挑战:
智能体间复杂的竞争与合作关系使得联合优化个体效果和系统整体性能变得困难。一方面,在完全竞争的环境下,每个广告主的效用可以被极度优化,但预算充足或可接受成本更高的广告主将会以更加激进的出价方式以获得更多的曝光,导致流量的按需分配无法实现,进而导致对社会福利的负面影响。另一方面,在完全协作的优化范式中,尽管能够让所有广告主以最优化整体社会福利为目标进行出价,但这可能会牺牲单个广告主的效果,同时广告主可能学得“共谋”出低价的行为,导致平台受损。因此,为了平衡个体效果和整体社会福利,一个可能的方案是构建一个混合合作-竞争框架(MCC, mixed cooperative-competitive),来使平台能够在社会福利和平台收入之间进行一个灵活的取舍。为实现混合合作-竞争,现有方案一般通过手动修改奖赏函数或改变与环境有关的参数来达到该目标,然而前者在拍卖场景下并没有一个确定的奖赏函数形式,而后者仅在模拟器中可行。
MCC中的合作关系可能会损害平台的收入,例如合作的出价智能体可能会共谋出低价。尽管保留价是一种保证平台收入的有效方法,但如何在MCC框架中优化保留价来减少对社会福利的影响仍是一个开放性问题。
MCC框架在工业界的实现也是一个巨大的挑战。理想情况下每个广告主对应一个智能体,但这个数量级过于巨大,且每个智能体得到的奖赏过于稀疏,导致难以学得一个较好的出价策略。
基于以上挑战,我们提出了合作-竞争多智能体自动出价框架(MAAB, Multi-Agent Auto-bidding),其主要思想如下:
为了平衡出价智能体间的竞争和合作关系,我们提出了一种基于温度调控的奖励分配机制。即将一次拍卖中的奖赏根据softmax函数产出的权重分配给各方智能体。此外,softmax函数中引入的温度参数可以有效调控智能体之间的竞争与合作关系。
为了减少智能体合作共谋出价导致平台收入受损的问题,我们引入了门槛智能体来为每一个自动出价智能体设置一个个性化的竞价门槛。直觉上,门槛智能体的目标是通过提高竞价门槛来获取较高的平台收入,然而自动竞价智能体则具有一个相反的目标,即降低出价门槛使得可以以较低的成本获取流量。门槛智能体和出价智能体是通过一种对抗的方式进行联合训练,直到彼此策略达到某种均衡点。
我们提出一种类似平均场的方法来解决来自工业场景大规模多智能体系统的挑战。通过将同目标的智能体聚合为一个平均自动出价智能体,百万级别广告主之间复杂的交互可以被简化,使得在大规模多智能体系统中部署自动竞价服务变为可能。
▐ 基础概念
1. 自动出价模型
广告主诉求和约束多种多样,预算约束是最常见的一种约束形式。为了简化说明,我们以BCB计划为例介绍我们的机制设计。
对BCB计划来说,假设一段时间内(如一天)有T个参竟机会,日预算为的计划i对机会t出价。如果他出价最高则竞得该流量,并按照GSP进行扣费,消耗记为,并获得价值。BCB计划目标则是在总消耗小于预算的约束下,最大化其获得的价值,即:
其中表示是否竞得流量。
2. 马尔科夫过程
一个部分观测的马尔科夫过程可以表示为
402 Payment Required
。其中s是环境的真实状态,o是能够观测到的状态,观测函数为: 。在任一时刻,任一智能体根据观测 做出的动作为: 。当所有智能体动作 执行后,每个智能体可以得到一个奖赏 ,且环境状态变为s',转移函数记为: 。 为折扣系数,每个智能体需要通过优化其策略最大化累计奖赏: 我们采用马尔科夫过程建模自动出价中的多智能体系统。每个自动出价智能体i的动作为出价 ,其观测状态由三部分构成: ,分别为剩余预算、流量价值和剩余竞价机会。出价受业务限制,一般存在上下界 。奖赏为 ,竞得后通过二价算得扣费 ,则下一时刻的观测变量为402 Payment Required
。每个智能体目标为优化竞得流量的价值总和:3. 独立学习 (IL, Independent Learner)
在多智能体强化学习领域,最常用的训练方式是同时学习非中心化的价值函数和策略,比如Independent -learning ,每个agent共享环境,并同时分别用DQN或者Q-learning训练独立Q函数。在后面我们将这种agent记为IL。
IL中每个agent的Q函数表示为:,其参数表示为。函数的训练细节DQN一致。replay buffer中的存储了。loss为:
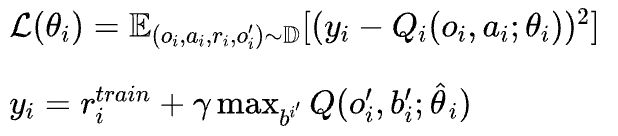
其中是target network的参数,是每个智能体用于训练的奖赏,有两种:
环境奖赏,即每个智能体从环境中获得的自己的奖赏。当时,各智能体之间是完全竞争的,称为CM-IL。
总奖赏,是所有智能体奖赏之和,也为此次分配结果的社会总福利(Social welfare)。当时,各智能体是合作关系,即为了总社会福利共同努力,此时他们为合作关系,称为CO-IL。
我们也定义了合作和竞争关系如下:假设一次拍卖中有两个智能体,这次展现对两个智能体的价值分别为:、,假设,当他们的出价满足时,这两个智能体间的关系是合作的,否则是竞争的。这种定义是基于直觉的,合作的目标是为了更大的社会总福利。
▐ IL的行为分析
在本节中,我们分析了CM-IL和CO-IL两种模式下的自动出价智能体的表现,并发现CM-IL会导致寡头现象的产生并不利于社会总福利,而CO-IL虽然具有较高的社会福利,但会损害平台收入。为了直观阐明以上结论,我们构建了一个由两个自动出价智能体构成的环境,这两个自动出价智能体的目标都是在固定预算内最大化他们的总价值。我们分别以CM-IL和CO-IL模式训练50k轮,并从以下三种指标观察其最终效果:
智能体1获得的总价值:智能体2获得的价值由社会福利以及智能体1获取的总价值反推出来,因此没有绘出。
社会福利:社会福利为所有智能体价值的总和。
平台收入:扣费使用GSP机制。
假设两个智能体预算总和为,预算分配比例参数为,则两个智能体的预算分别为:和,我们尝试了不同和的参数组合,在此环境下得到的实验结果如下图所示:

其中每张图中的每一个单元中的数值代表在不同参数组合下的实验结果。我们首先观察CM-IL下的智能体1获取的价值,如图(a)所示,当 ,即智能体1预算显著多于2时,智能体1获得的总价值为(39, 38, 41, 36),其显著多于智能体2所获得的价值(19, 19, 16, 21)。此时智能体1通过出更高的出价获取了大部分展现机会,形成了寡头现象。同时这种寡头现象也导致了较低社会福利,如图(c)和(d)所示,CM-IL达到了比CO-IL更低的社会福利,特别是在具有充足预算的设置下(例如当时,CO-IL的社会福利为(64,64,64),显著低于CM-IL的社会福利(57,56,58)。
适当的合作可以通过防止寡头现象的产生从而提高社会福利。这可以通过比较图(a)和图(b)得出:有较多预算时(),智能体1的价值从(39,38,41,36)降低为(35,38,33,33),而具有较少预算时(),智能体1的价值从(20,16,17,22)提高为(20,25,28,30)。这表明CO-IL更多是通过展现价值而非预算来进行展现机会的分配,并且就社会福利而言,CO-IL的这种方式显然达到了一种更好的均衡。
然而CO-IL也会导致部分广告主利益受损,尤其当存在其他广告主的value显著大于它时。同时,合作也会使各智能体“合谋”降低出价,导致平台收入受损(对比(f)和(d))。
总的来说,竞争和合作状态会导致两种极端情况:竞争会导致在预算差异过大时出现寡头现象,进而损害社会总福利;合作能达到更高的社会总福利,但会导致平台收入和部分广告主利益受损。
▐ 我们的方法
为了在大规模多智能体环境中兼顾社会总福利和平台收入,我们提出了MAAB框架。该框架示意图如下图所示:

框架主要包含三部分:
为平衡竞争与合作关系,提出基于温度调控的奖励分配机制(Temperature Regularized Credit Assignment, TRCA);
为了降低因合作导致的平台收入损失,引入门槛智能体;
用于大规模多智能体系统的平均场方法。
下面我们进行详细的介绍。
基于温度调控的奖励分配机制TRCA
受上文实验中IL在竞争和合作下分别产生的极端行为启发,我们提出了TRCA这种奖励分配机制,来建立多智能间的一种混合合作竞争关系。
TRCA的主要思路是给每个智能体的奖赏赋以一个权重参数。这个权重衡量了每个智能体对总奖赏的贡献,因此各智能体的奖赏为:。其中我们将定义为
402 Payment Required
。它是一个softmax式的权重,满足 和 。超参 ( )决定了竞争和合作的程度,为了分析 是如何影响智能体行为的,我们以一轮拍卖中的两个智能体的情况进行简要分析,并给出下面的定理证明在此处省略,有兴趣的同学可以查看原文。:
证明在此处省略,感兴趣的同学可以查看原文。
由上可知,当大于一定阈值时,智能体将会倾向于合作状态,反之则处于竞争状态。因此我们可以使用来很方便的调节混合竞争合作状态中竞争和合作的相对程度,进而达到平台收入与社会福利之间的适当取舍。
门槛智能体
在线广告的一个目标是实现平台和广告主的双赢。如上节仿真实验可知,尽管合作有助于提升社会总福利,但各智能体会倾向于共谋出低价,导致平台收入下降。在本节中,我们提出了几种提升平台收入的方法。
最简单的方法是设置一个固定的出价门槛。当自动出价智能体出价时,使用TRCA奖赏,反之奖赏为0:。但固定的门槛很难设置,过高会损失广告主收益,过低则对提升平台收入无益。
一种进阶方法,是对每次参竟设置自适应出价门槛。我们可以新增一个面向平台收入的智能体,并使用RL方法优化其设置出价门槛的策略。但该智能体的奖赏很难定义。如果简单地将其奖赏定义为平台收入,那么这个智能体会倾向于设置一个过高出价门槛。另一方面,同一拍卖中的不同自动出价智能体具有差异化的个体信息,因此共用一个出价门槛可能并非一个好选择。
基于以上分析,我们在MAAB中提出使用多门槛智能体,每一个门槛智能体为对应的自动出价智能体提供一个出价门槛。每次拍卖中,门槛智能体和出价智能体分别给出出价门槛和出价。参竟后我们得到客户收益并计算得到TRCA奖赏,同时门槛智能体获得平台收入,其定义为单次拍卖中的扣费。同时,为了防止门槛智能体出过高的竞价门槛,我们提出了一种称为门槛门控(bar gate)机制的方法。门槛门控机制为每对出价智能体和门槛智能体输出:
然后我们采用和分别作为两个智能体的奖赏。注意门槛智能体仅用作训练,在线执行阶段不发挥作用。
门槛智能体和出价智能体采用同时训练的方式。门槛智能体致力于提升平台收入,出价智能体致力于提升客户收益。门槛门控机制将这两种不同的奖赏建立了一种关系。一方面,当门槛过高,双方都获得0奖赏,此时门槛智能体会降低门槛,出价智能体则增加出价,直到两方达成一致,即,此时双方才能同时获得奖赏。另一方面,当门槛过低时,双方均会获得一定的收益,但下一轮门槛智能体会尝试提升出价,同时受TRCA中合作关系鼓励出价智能体会尝试降低出价,直到稳态形成。
总的来说,我们提出的这个多门槛智能体和对应的奖赏设计,能够通过将出价提升至合适水平来提升平台收入。值得一提的是,这个方案看起来和保留价很相似,但我们提出的门槛智能体仅在训练阶段生效,在执行阶段被移除,因此在线的GSP机制仍然得到保留。
用于大规模多智能体系统的平均场方法
在实践中,我们面临上百亿的参竟机会和数百万的参竟计划,理想情况下每个计划应当对应一个出价智能体,这些智能体同时进行训练,但这会导致计算资源紧张以及奖赏稀疏等问题。一个可行方案是把智能体按照更高视角、按照某种划分标准做聚类。聚类后的智能体会有更稠密的奖赏,同时训练的智能体个数也大大减少。我们的方法中提出使用计划间最本质的不同来做计划分组,即计划的诉求。当然也可以使用其他原则进行分组。按照待优化目标分组后,我们得到,其中每组包含了对应目标下的所有计划。但是,在对每组训练可以应用于组内所有计划的出价策略时,还面临以下困难:
Q-learning算法中需要下时刻状态下的最大Q值用于训练,但聚类后的下时刻状态未知
计划间通常有不同的预算约束,每条流量对应的流量价值也不同,共用策略存在困难
为了解决上述问题,我们的平均场方法如下:
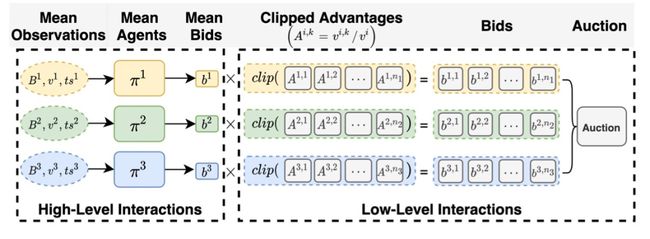
其主要思想是平均策略先基于平均预算等观测变量计算平均出价,组内各计划则在平均价值的基础上,考虑自身流量价值与平均价值的相对大小关系调整其出价。在详细介绍我们的方案前,我们首先介绍下我们使用的符号的含义。我们将一段时间(如15分钟)看做是一个时间戳,每段时间内会陆续出现展现机会。将时间戳t内的所有参竟机会集合记作,为其中一次展现机会。代表展现机会e对计划的价值。表示计划k是否赢得了展现机会e,即它的ecpm排序分=是否最高。上述方案的马尔科夫过程的具体定义如下:
观测状态:平均智能体i在时刻t的观测值被定义为:。其中是在时刻t的剩余预算,其初始值为。为流量的平均价值。是剩余出价机会。
动作空间:平均智能体的动作为平均出价。计划在展现机会e上的出价为,其中。clip(.)用于保证最终出价不会出现极端值。
奖赏函数:奖赏也定义在一个聚合粒度:
402 Payment Required
转移函数:展现机会e上获胜计划的期望扣费为,其中j为ecpm排序中下一位广告的下标。因此平均智能体的消耗为:,则下一时刻观测状态为,当剩余预算为0是,智能体的出价只能为0.
在线阶段,组内计划共享一个出价策略。如对于计划,出价策略的输入为计划k自身观测状态(而非组内平均状态),策略输出即为其出价。
配合以上平均智能体模型,我们的门槛智能体和TRCA奖赏也需要进行一些适配:TRCA中的替换为平均出价;门槛智能体也采用平均场方法,每个平均出价智能体对应一个门槛智能体。如此我们的方法就可在大规模广告系统中进行训练了。
▐ 实验
离线数据集仿真
离线数据集
离线数据集来自阿里巴巴广告系统在2020年某天中某6小时的参竟日志。包含了约70w次展现机会,每次参竟约有400个广告参竟。日志中包含了广告主id、时间、广告主目标、流量价值预估值、原始手动出价等信息。日志中的计划按照其目标大体可以分为三类:优化点击的、优化购买的、优化收藏加购的,后文我们将这三组计划分别记为CLICK, CONV, CART 。
评估指标
我们主要关注两个指标:(1) 社会总福利(Social welfare);(2)平台收入,拍卖机制使用GSP机制。
预算约束
对于离线实验,我们首先令所有平均智能体出最高价,然后计算按最高进行出价的总扣费,记为 。然后计划 的预算设置为 。
我们考虑两种设置:1),,这种设置下所有自动竞价智能体的预算一致(记为setting 1);2),,这种为预算不均衡的设定(记为setting 2)。
对比方法
(1)MSB(Manually set bids):人工设定的出价,即广告主的原始出价。
(2)DQN-S:单智能体版本的IL,每一类需求对应一个智能体,假设其他广告使用原始出价进行训练。
(3)CM-IL
(4)CO-IL
(5)MAAB,即我们的方法。
实验结果
离线实验结果如下图:
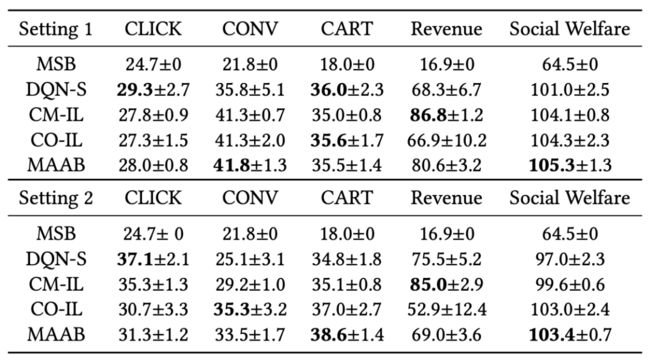
我们发现,传统的手动竞价(MSB)方式并没有取得很好的效果,其社会福利为64.5,平台的收入为16.9,且是所有方法中最差的。相比之下,DQN-S在三个组的价值(29.3, 35.8, 36.0),社会福利(101.0)和平台收入(68.3)上均更优,这是得益于RL可以较好地控制预算的使用。
然而,DQN-S的性能仍然受到其他智能体出价固定这一不切实际的假设的限制。采用多智能体学习范式可以进一步消除这种假设,例如CM-IL无论从社会福利(例如,setting 1中104.1 > 101.0)还是平台的收入上(例如,setting 1中86.8 > 68.3)均优于DQN-S。
然而,这种竞争关系可能并不能帮助实现更好的社会福利,这一点可以从CM-IL与CO-IL的比较中看出。CO-IL建模智能体之间的合作关系,因此其在社会福利上略优于CM-IL(Setting 1中104.3 > 104.1,Setting 2中103.0 > 99.6),然而,这种提升是以牺牲平台收入为代价的(Setting 1 中 66.9 < 86.8,Setting 2中52.9 < 85.0)。
在这两个极端之间,MAAB采用了TRCA并以混合合作竞争的方式建立智能体之间的关系,从而实现了社会福利与收入之间更好的均衡。如表所示,MAAB的社会福利优于CM-IL(在Setting 1中为105.3 > 104.1,在Setting 2中103.4 > 99.6),同时在收入方面显著优于CO-IL(在Setting 1中为80.6 > 66.9,在Setting 2中为69.0 > 52.9)。
在线实验
我们也进行了线上AB实验,效果如下表(各指标数值均进行了归一化),能够看出我们的方法能够在有限的平台收入损失下,有效的提升社会总福利。

消融实验
TRCA有效性
为了评估TRCA在建模合作和竞争关系上的有效性,我们去除MAAB中门槛智能体,并将该方法成为MIX-IL,然后通过调整MIX-IL中的参数进行离线实验分析。越大关系越倾向于合作,越小关系越倾向于竞争。当时,MIX-IL等价于CM-IL;当时,MIX-IL等价于CO-IL。
我们使用和进行实验,我们尝试了= 0, 2, 4, ,结果如下:

可以看到合作和竞争程度可以很方便的通过调节来平衡。
门槛智能体的影响
为了验证门槛智能体在提升平台收入上的必要性以及自适应门槛智能体的效果,我们用这两种方法和MAAB进行了比较:(1)MIX-IL:无门槛智能体;(2)MAAB-fix:使用固定的门槛智能体动作:。预算设定为:和。离线实验结果如下:

对比MIX-IL和MAAB-fix,可以看到出价门槛对平台收入的明显提升,门槛越高提升越大(99.6->114.3->164.9)。但同时过高的门槛也会降低社会福利(104->99.3),过低的门槛平台收入提升有限。采用自适应门槛的MAAB则能兼顾两者,在社会福利损失有限情况(104->103.9)下大幅度提升平台收入。
▐ 总结
自动出价已经成为在线广告中优化广告主投放效果的基础工具。我们提出的MAAB是一个能用于大规模广告系统自动出价的多智能体强化学习框架,它主要有三个贡献:
(1)提出了TRCA,建立了自动出价智能体间的混合竞争-合作关系。
(2)提出了在训练时使用门槛智能体提升平台收入。
(3)使用了平均场方法,将MAAB用于大规模广告平台。
未来我们将会持续探索TRCA中的温度参数实时动态调整,和升级门槛智能体的奖赏方案设计以加快其收敛。
参考文献
[1] Gagan Aggarwal, Ashwinkumar Badanidiyuru, and Aranyak Mehta. 2019. Autobidding with constraints. In WINE. Springer, 17–30.
[2] Han Cai, Kan Ren, Weinan Zhang, Kleanthis Malialis, Jun Wang, Yong Yu, and Defeng Guo. 2017. Real-time bidding by reinforcement learning in display advertising. In WSDM. 661–670.
[3] Google Ads Help Center. 2021. About automated bidding. https://support.google. com/google-ads/answer/2979071. Accessed: January 24, 2021.
[4] Carl Davidson and Raymond Deneckere. 1986. Long-run competition in capacity, short-run competition in price, and the Cournot model. The Rand Journal of Economics (1986), 404–415.
[5] Paul Dütting, Zhe Feng, Harikrishna Narasimhan, David Parkes, and Sai Srivatsa Ravindranath. 2019. Optimal auctions through deep learning. In ICML. PMLR, 1706–1715.
[6] Benjamin Edelman, Michael Ostrovsky, and Michael Schwarz. 2007. Internet advertising and the generalized second-price auction: Selling billions of dollars worth of keywords. American economic review 97, 1 (2007), 242–259.
[7] eMarketer. 2015. Worldwide retail ecommerce sales: eMarketer’s updated estimates and forecast through 2019. (2015).
[8] Facebook. 2021. Facebook. https://www.facebook.com/business/m/one-sheeters/ facebook-bid-strategy-guide. Accessed: January 24, 2021.
[9] Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. 2018. Counterfactual multi-agent policy gradients. In AAAI, Vol. 32.
[10] Google. 2021. Google AdWords API. https://developers.google.com/adwords/ api/docs/guides/start. Accessed: January 24, 2021.
[11] Ziyu Guan, Hongchang Wu, Qingyu Cao, Hao Liu, Wei Zhao, Sheng Li, Cai Xu, Guang Qiu, Jian Xu, and Bo Zheng. 2021. Multi-Agent Cooperative Bidding Games for Multi-Objective Optimization in e-Commercial Sponsored Search. arXiv preprint arXiv:2106.04075 (2021).
[12] Garrett Hardin. 2009. The tragedy of the commons. Journal of Natural Resources Policy Research 1, 3 (2009), 243–253.
[13] Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor. 2019. A survey and critique of multiagent deep reinforcement learning. AAMAS 33, 6 (2019), 750–797.
[14] Junqi Jin, Chengru Song, Han Li, Kun Gai, Jun Wang, and Weinan Zhang. 2018. Real-time bidding with multi-agent reinforcement learning in display advertising. In CIKM. 2193–2201.
[15] Jean-Michel Lasry and Pierre-Louis Lions. 2007. Mean field games. Japanese journal of mathematics 2, 1 (2007), 229–260.
[16] Joel Z Leibo and Marc Lanctot. 2017. Multi-agent Reinforcement Learning in Sequential Social Dilemmas. (2017). arXiv:arXiv:1702.03037v1
[17] Michael L Littman. 1994. Markov games as a framework for multi-agent reinforcement learning. In Machine learning proceedings 1994. Elsevier, 157–163.
[18] Xiangyu Liu, Chuan Yu, Zhilin Zhang, Zhenzhe Zheng, Yu Rong, Hongtao Lv, Da Huo, Yiqing Wang, Dagui Chen, Jian Xu, Fan Wu, Guihai Chen, and Xiaoqiang Zhu. 2021. Neural Auction: End-to-End Learning of Auction Mechanisms for E-Commerce Advertising. In SIGKDD. 3354–3364.
[19] Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. 2017. Multi-agent actor-critic for mixed cooperative-competitive environments. In NIPS. 6379–6390.
[20] Robert C Marshall and Leslie M Marx. 2007. Bidder collusion. Journal of Economic Theory 133, 1 (2007), 374–402.
[21] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. nature 518, 7540 (2015), 529–533.
[22] Mehryar Mohri and Andres Munoz Medina. 2014. Learning theory and algorithms for revenue optimization in second price auctions with reserve. In ICML. PMLR, 262–270.
[23] Roger B Myerson. 1981. Optimal auction design. Mathematics of operations research 6, 1 (1981), 58–73.
[24] Michael Ostrovsky and Michael Schwarz. 2011. Reserve prices in internet advertising auctions: A field experiment. In EC. 59–60.
[25] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. 2018. QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. In ICML. 4295–4304.
[26] Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinícius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. 2018. Value-Decomposition Networks For Cooperative Multi-Agent Learning Based On Team Reward.. In AAMAS. 2085–2087.
[27] Ardi Tampuu, Tambet Matiisen, Dorian Kodelja, Ilya Kuzovkin, Kristjan Korjus, Juhan Aru, Jaan Aru, and Raul Vicente. 2017. Multiagent cooperation and competition with deep reinforcement learning. PloS one 12, 4 (2017), e0172395.
[28] Ming Tan. 1993. Multi-agent reinforcement learning: Independent vs. cooperative agents. In ICML. 330–337.
[29] David RM Thompson and Kevin Leyton-Brown. 2013. Revenue optimization in the generalized second-price auction. In EC. 837–852.
[30] Chao Wen, Xinghu Yao, Yuhui Wang, and Xiaoyang Tan. 2020. SMIX (): Enhancing Centralized Value Functions for Cooperative Multi-Agent Reinforcement Learning.. In AAAI. 7301–7308.
[31] Di Wu, Xiujun Chen, Xun Yang, Hao Wang, Qing Tan, Xiaoxun Zhang, Jian Xu, and Kun Gai. 2018. Budget constrained bidding by model-free reinforcement learning in display advertising. In CIKM. 1443–1451.
[32] Xiao Yang, Daren Sun, Ruiwei Zhu, Tao Deng, Zhi Guo, Zongyao Ding, Shouke Qin, and Yanfeng Zhu. 2019. Aiads: Automated and intelligent advertising system for sponsored search. In SIGKDD. 1881–1890.
[33] Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. 2018. Mean field multi-agent reinforcement learning. In ICML. PMLR, 5571–5580.
[34] Shuai Yuan, Jun Wang, Bowei Chen, Peter Mason, and Sam Seljan. 2014. An empirical study of reserve price optimisation in real-time bidding. In SIGKDD. 1897–1906.
END

也许你还想看
丨阿里妈妈技术团队4篇论文入选WSDM 2022
丨WSDM 2022 | 合约广告自适应统一分配框架
丨WSDM 2022 | 基于元学习的多场景多任务商家建模
丨WSDM 2022 | 点击率模型特征交叉方向的发展及CAN模型介绍
欢迎关注「阿里妈妈技术」,了解更多~
疯狂暗示↓↓↓↓↓↓↓