不同回归算法精度比对
回归即预测与对象关联的连续值属性
- 1.库导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVR #支持向量机
from sklearn.ensemble import GradientBoostingRegressor # 梯度树提升
from sklearn.neural_network import MLPRegressor #BP神经算法
from sklearn.ensemble import RandomForestRegressor #随机森林
from sklearn.ensemble import ExtraTreesRegressor #极端随机树
from sklearn.metrics import r2_score #R2评价
from sklearn.linear_model import LinearRegression #线性回归
from sklearn import preprocessing
plt.rcParams['font.sans-serif'] = ['KaiTi'] #全局字体替换_中文显示
plt.rcParams['axes.unicode_minus'] = False #坐标轴负数的负号显示问题
import warnings
warnings.filterwarnings("ignore")
- 2 数据准备
#数据准备
import sklearn.datasets
Dataset = sklearn.datasets.load_boston() #加载波士顿房价数据,字典格式,内部为数组
X = Dataset['data'] #属性数据
Y = Dataset['target'] #标签数据
- 3数据预处理
#数据预处理--标准化(通过删除每个特征的平均值来实现特征数据中心化,然后除以非常数特征的标准差来缩放数据)
#对属性数据标准化
scaler = preprocessing.StandardScaler().fit(X)
X_scaled = scaler.transform(X)
#对标签数据标准化
scaler1 = preprocessing.StandardScaler().fit(Y.reshape(-1,1)) #转换Y的shape
Y_scaled = scaler1.transform(Y.reshape(-1,1))
- 4 模型建立
#线性回归
LR_model = LinearRegression()
#BP神经网络
MLP_model = MLPRegressor()
#支持向量机
SVR_model=SVR()
# 随机森林回归模型
RF_model = RandomForestRegressor()
#极端随机树
ET_model = ExtraTreesRegressor()
#梯度树提升
GB_model = GradientBoostingRegressor()
- 5模型训练
model_list = [LR_model,MLP_model,SVR_model,RF_model,ET_model,GB_model]
model_name = ['线性回归','BP神经网络','支持向量机','随机森林','极端随机树','梯度树提升']
def train_test_data_generate(Data,num):
Original = range(len(Data))
test_list=list(range(num,len(Data),5))
train_list = [i for i in Original if i not in test_list ]
return test_list,train_list
R2_list = []
pre_list = []
#模型训练与R2计算
for model in model_list:
Result_tem = []
pre_tem = []
for i in range(5):
test_id,train_id = train_test_data_generate(X_scaled,i)
x_train = X_scaled[train_id,:]
x_test = X_scaled[test_id,:]
y_train = Y_scaled[train_id,:]
y_test = Y_scaled[test_id,:]
model.fit(x_train,y_train)
diabetes_y_pred = model.predict(x_test)
Result_tem.append(r2_score(diabetes_y_pred,y_test, sample_weight=None))
pre_tem.append(diabetes_y_pred)
R2_list.append(Result_tem)
pre_list.append(pre_tem)
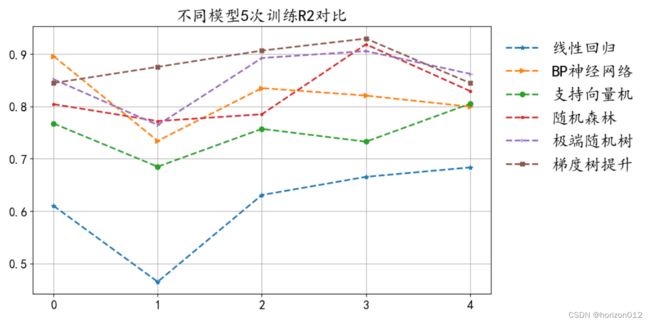
- 6结果展示–画图
marker_list = ['*','>','o','.','4','X']
plt.figure(figsize=(10,6),dpi=100)
plt.grid()
for i,R2 in enumerate(R2_list):
plt.plot(np.arange(len(R2_list[0])),R2,label=model_name[i],linestyle = '--',marker =marker_list[i],linewidth = '2')
plt.tick_params(labelsize=15)
plt.gca().xaxis.set_major_locator(plt.MultipleLocator(1))
plt.gca().yaxis.set_major_locator(plt.MultipleLocator(0.1))
plt.legend(frameon=False,fontsize=20,bbox_to_anchor=(1,1))
plt.title('不同模型5次训练R2对比',fontsize=20)
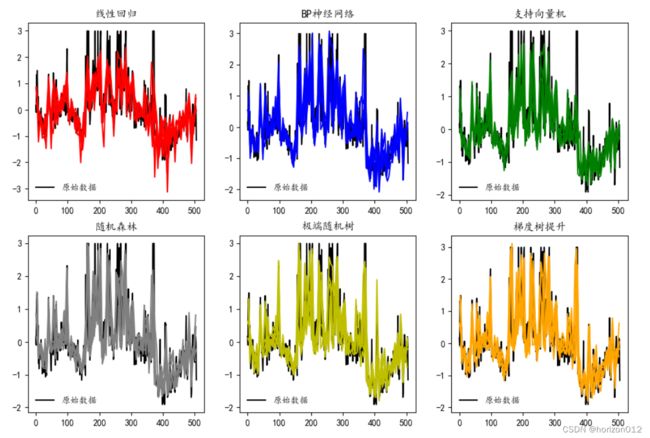
color_list = ['r','b','g','grey','y','orange']
plt.figure(figsize=(12,8),dpi=100)
for i,pre in enumerate(pre_list):
plt.subplot(2, 3, i+1)
plt.plot(np.arange(len(Y_scaled)),Y_scaled,color='k',label='原始数据')
plt.title(model_name[i])
plt.legend(frameon=False)
for j in range(5):
test_id,train_id = train_test_data_generate(X_scaled,j)
plt.plot(test_id,pre_list[i][j],color=color_list[i])
待更新
1.数据预测与还原
2.各模型参数选择
3.其它回归算法
4.不同标准化
参考:
https://fanfanzhisu.blog.csdn.net/article/details/84591954