(CV论文)User-Guided Deep Anime Line Art Colorization with Conditional Adversarial Networks 用户引导动漫图像生成
论文链接:https://arxiv.org/pdf/1808.03240.pdf
摘要:
使用条件框架,WGAN-GP策略,使用彩色插图和线稿图的数据集,实现用户交互式引导图像生成。
cGAN based colorization model:
X为线稿图,H为用户提示信息,线稿图X由真实图像Y通过XDOG算法生成。

局部特征网络:F1,F2。
局部特征网络F1(训练到标记插图),从线条到生成器直接提取包含语义信息和空间信息的语义特征图。还将局部特征作为判别器的条件输入,有效缓解了过拟合问题。
F1提取到线稿图X的信息,然后将线稿图X,提示信息H,特征信息F1(X)一起喂给生成器G,得到生成图片G(X,H,F1(X)).
将原图像Y和生成图像G(X,H,F1(X))经过局部特征网络F2,计算二者的内容损失content loss。
将将原图像Y和生成图像G(X,H,F1(X))以及线稿图的局部信息F1(X)喂给判别器D,计算wasserstein distance.

用户交互:
使用最大池化将笔画图像降采样到四分之一分辨率,并通过将笔画图像Ydown和二进制掩码B设置为0,间隔为1来去除一半的输入像素。这样既去除了笔画的冗余,又保留了空间信息,模拟了稀疏的训练输入。这样就能够充分覆盖输入空间并训练出有效的模型。
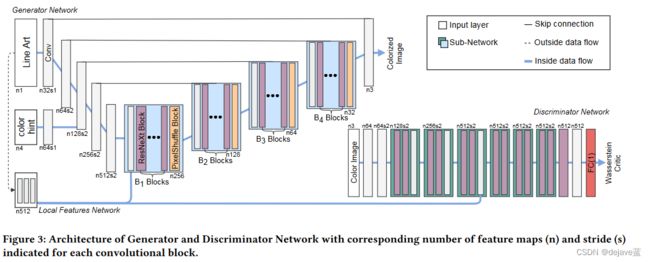
网络结构:生成器和判别器
生成器G:使用U-net结构,左边部分两个卷积块,一个局部特征网络(将图像提示输入信息转换为feature map特征图),进行下采样。右边部分是4个子模块,每个子模块包含一个卷积块,用于融合跳连的特征,然后堆叠Bn ResNeXt blocks, 作为子模块的核心。这里我们使用ResNeXt块代替Resnet块,因为ResNeXt块在增加网络容量方面更有效。另外在B2,B3,B4的ResNeXt块中添加膨胀,在不增加计算成本的情况下,进一步增加感受野。最后利用sub-pixel convolution layers来提高图像分辨率。
在整个网络中没有使用normalization layer,以保证精确着色的灵活性,并减少了内存使用和计算成本,并使更深的结构具有足够大的感受野。
除了最后一个卷积层使用tanh激活,其余层使用slope为0.2的LeakyReLU激活。
判别器D: 对SRGAN进行了修改。
将来自F1的局部特征作为条件输入,形成一个cGAN,并运用与生成器G相同的basic block,并额外堆叠更多层,使其可以处理512*512的输入。
损失函数:
生成器的损失函数:由内容损失content loss 和对抗损失 adversarial loss组成。参数![]()

判别器的损失函数:
对抗损失 adversarial loss:包括局部特征F1(X),和WGAN-GP作为损失,去区分真假图像对,生成的假图像G(X,H,F1(X)),输入的线稿图像局部特征F1(X)。
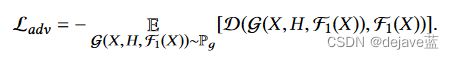
内容损失content los:采用感知损失perceptual loss作为内容损失,根据生成的CNN特征图和目标图像的差异进行简单的L2损失。c, h, w 表示 the number of channels, height and width。F2的输出表示在ImageNet上预训练的VGG16网络中第4个卷积层(激活后)得到的特征图。

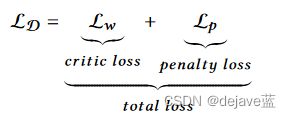
判别器D损失:由critic loss 和 penalty loss 组成。
critic loss:带有条件输入的WGAN。
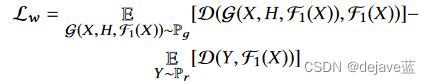
penalty loss:结合梯度惩罚gradient penalty和额外的约束项。

参数λ2 = 10, εdrift = 1e − 3
防止输出值漂移过远而偏离零,使得我们可以在更新生成器和判别器之间交替进行,以per -minibatch 数据为基准,相比于传统的生成器更新1次而判别器更新5次的设置来说,减少了训练时间。
用于惩罚梯度的插值点Pi的分布隐式定义如下:
用来惩罚ilustration分布Pr和生成分布Pg之间的直线梯度。
![]()
生成结果:
