目标检测算法FPN(Feature Pyramid Networks)简介
目标检测算法Feature Pyramid Networks(FPN)由Tsung-Yi Lin等人于2017年提出,论文名字为”Feature Pyramid Networks for Object Detection”,可以从https://arxiv.org/pdf/1612.03144.pdf 直接下载。
特征金字塔网络(Feature Pyramid Network)简称FPN,类似TDM(Top-Down Modulation)方法,FPN是一种自顶向下的特征融合方法,但是FPN是一种多尺度的目标检测算法,即不只有一个特征预测层。虽然有些算法也采用多尺度特征融合来进行目标检测,但是它们往往只利用融合后得到的一种尺度的特征,这种做法虽然可以将顶层特征的语义信息和底层特征细节信息,但是在特征反卷积等过程中会造成一些偏差,只利用融合后得到的特征进行预测会对检测精度造成不良影响。FPN方法从上述问题出发,可以在多个不同尺度的融合特征上进行预测,实现检测精度的最大化。
FPN的模型训练方式不同于传统的Faster R-CNN方法,因为FPN有多个预测层。类似于SSD方法,FPN中靠前的特征具有更高的分辨率,而我们希望用高分辨率特征来对小目标进行预测。FPN中的每个融合特征都会连接一个RPN(Region Proposal Network)网络,用以生成候选框,然后将所有生成的候选框集合在一起。因为我们希望更小的目标在更高分辨率的卷积特征图上预测,所以我们将这些候选框进行分配,分配原理如以下公式所示:
![]()
其中,k0为候选框被分配到的预测层,k0是一个常数,w和h代表候选框的宽和高,」代表取数值的下届。例如,预测层有2,3,4,5等4个,分别代表分辨率由大到小的4个融合特征层。k0=4,一个宽和高的乘积为112^2的候选框会被分配到预测层k=3(k大于5时取值5,k小于2时取值为2),进行之后的检测。由公式可以看出,候选框的面积越大,被分配到的预测层的号码越大,大的目标会被分配到分辨率较低的预测层进行预测。这些候选框在经过分配之后被送入对应的RoI pooling层,RoI pooling层输出的结果被级联在一起,再经过两个全连接层,进行目标分类和目标位置回归,如下图,FPN with Fast R-CNN or Faster R-CNN。
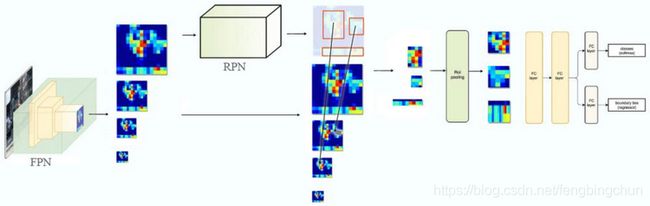
Faster R-CNN和FPN都属于基于候选区域的方法,但是Faster R-CNN只有一个预测结构,而FPN有多个预测结构,这就决定了它们有各自的多层特征融合方式。
FPN使用不同分辨率的特征图感知不同大小的物体,并通过连续上采样和跨层融合机制使输出特征兼具底层视觉信息和高层语义信息。低层次的特征图语义不够丰富,不能直接用于分类,而深层的特征更值得信赖。将侧向连接与自上而下的连接组合起来,就可以得到不同分辨率的特征图,而它们都包含了原来最深层特征图的语义信息。
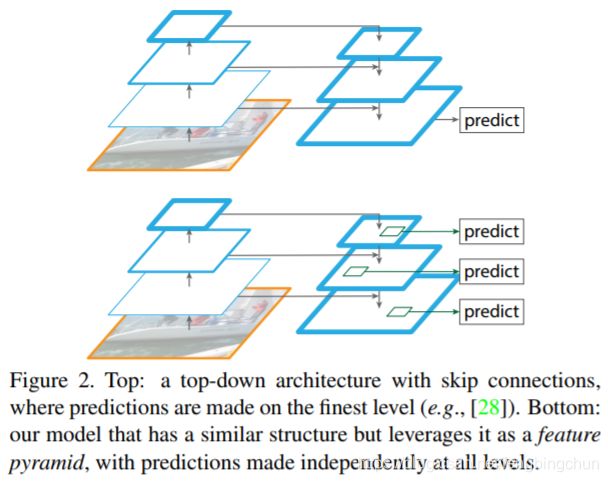
FPN特征金字塔的思想来源于传统算法中的多尺度识别,具体操作是将原始图像放缩到不同尺度大小的状态,缩小的图像应用于图像全局特征,放大的图像应用于细节特征。深度学习网络越深层次的特征图,拥有越多的全局和抽象特征。在图像分类任务中,这种深层次的特征保持了良好的平移不变性,不论分类物体图像在哪个位置,深层次的全局特征,依然可以获得信息。但是在图像识别领域中,图像分类中的平移不变性就不成立了,不光要识别出物体的分类还要识别出物体的位置,所以如何结合浅层和深层的信息是一个重要的问题。FPN通过横向连接段,纵向相加的方式,解决浅层和深层结合问题。总体结构采用自上而下的信息结构,如下图所示:在图中每一个正方形代表一个特征图,从小到大的正方形表示从深到浅的特征图。在新生成的特征图中,最浅层次拥有上面所有层次信息的特征。深层的特征语义信息比较少,但是目标位置准确;浅层的特征语义信息比较丰富,但是目标位置比较粗略。图中Top部分是一个带有skip connection的网络结构,在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。图中Bottom部分,是一个网络结构和上面的类似,区别在于预测是在每一层中独立进行的。
如下图所示为FPN连接结构,采用1*1的卷积层和2倍的上采样的结构。上采样(upsampling)是卷积的反向过程,又被称为
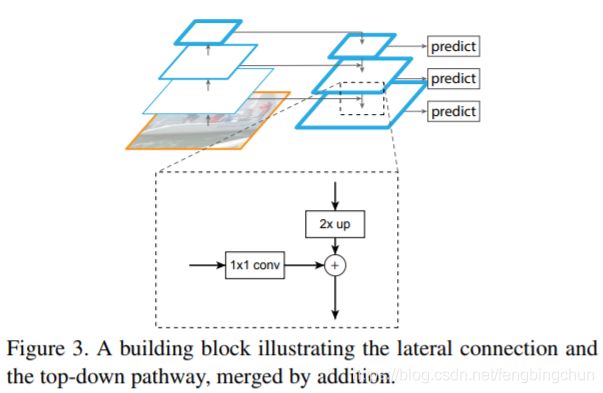
反卷积网络。卷积操作使得特征图尺寸不断缩小或者不变(1*1卷积),而反卷积操作会使得特征图尺寸不断增大。这里使用反卷积操作是为了深层次的特征图,通过放大到和浅层的特征图一样的尺寸后,可以进行元素级别(element-wise)的相加。设计1*1卷积的结构是为了对于原有的特征图,进行的尺寸的不变的空间变换,使得结构上更加鲁棒。FPN作者的主网络采用ResNet。如图,一个自底向上的线路(pathway),一个自顶向下的线路(pathway),横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数(降低channels数目),并不改变feature map的尺寸大小。自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其它一些层的时候不会改变,FPN作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。每个stage最后一层输出的是金字塔的特征图。自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect),并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。不用C1是因为太大,占用太多内存了,如下图所示,FPN with RPN。
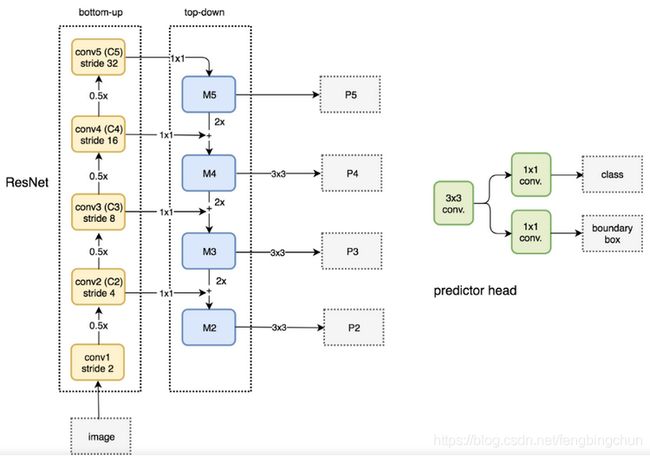
FPN作者一方面将FPN放在RPN网络中用于生成proposal,原来的RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为32^2, 64^2, 128^2, 256^2, 512^2,另外每个scale层都有3个长宽对比度:1:2, 1:1, 2:1。所以整个特征金字塔有15种anchor。
FPN中,正负样本的界定和Faster R-CNN差不多:如果某个anchor和一个给定的ground truth有最高的IoU(Intersection over Union)或者和任意一个ground truth的IoU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IoU都小于0.3,则为负样本。
下图中展示了FPN论文中提到的4种提取特征的形式:蓝色框代表feature maps,蓝色线越粗,代表其语义信息越强。
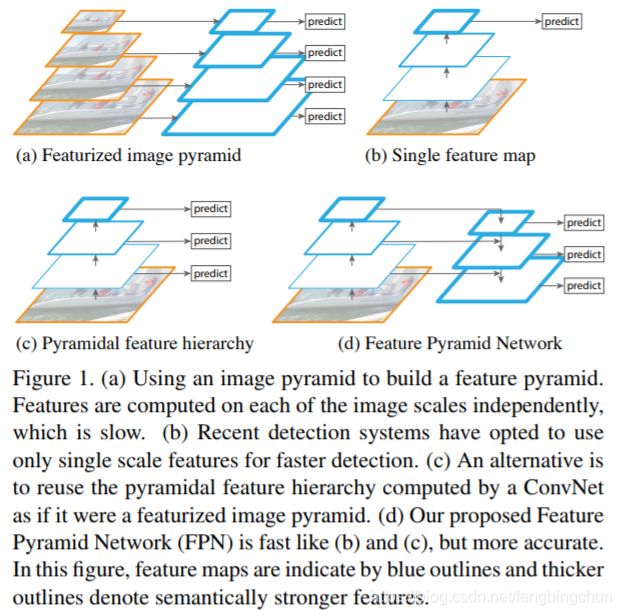
(a). 图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔;
(b). 像SPP net、Fast R-CNN、Faster R-CNN是采用这种方式,即仅采用网络最后一层的特征;
(c). 像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做检测,这种方式不会增加额外的计算量。FPN作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在FPN作者看来足够低层的特征对于检测小物体是很有帮助的;
(d). FPN作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
FPN is not an object detector by itself. It is a feature detector that works with object detectors. For example, we extract multiple feature map layers with FPN and feed them into an RPN (an object detector using convolutions and anchors) in detecting objects.
目前,目标检测框架主要有两种:一种是one-stage ,例如YOLO、SSD等,这一类方法速度很快,但识别精度没有two-stage的高,其中一个很重要的原因是,利用一个分类器很难既把负样本抑制掉,又把目标分类好。另外一种目标检测框架是two-stage,以Faster R-CNN为代表,这一类方法识别准确度和定位精度都很高,但存在着计算效率低,资源占用大的问题。也就是说,one-stage检测器更快更简单,但是准确度不高。two-stage检测器准确度高,但太费资源。
以上内容均来自网络,主要参考文献如下:
1. 《基于多尺度特征的目标检测算法研究》,哈尔滨工业大学,硕论,2018
2. 《基于深度学习的交通物体参与物实时识别研究》,北京交通大学,硕论,2018
3. https://medium.com/@jonathan_hui/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c
4. https://xmfbit.github.io/2018/04/02/paper-fpn/
5. https://blog.csdn.net/u014380165/article/details/72890275
6. https://zhuanlan.zhihu.com/p/41794688
7. http://noahsnail.com/2018/03/20/2018-03-20-Feature%20Pyramid%20Networks%20for%20Object%20Detection%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91%E2%80%94%E2%80%94%E4%B8%AD%E6%96%87%E7%89%88/
8. https://t.cj.sina.com.cn/articles/view/2118746300/7e4980bc02000dcsv
9. https://blog.csdn.net/xiamentingtao/article/details/78598027
GitHub:https://github.com/fengbingchun/NN_Test