目标检测之FPN Feature Pyramid Networks for Object Detection
目标检测之FPN特征金字塔网络
- 前言
- FPN简介
- Faster RCNN中的FPN
- FPN与RPN
- FPN与Fast R-CNN
- 实验效果
欢迎交流,禁止转载!
前言
论文:《Feature Pyramid Networks for Object Detection》
论文地址:https://arxiv.org/pdf/1612.03144.pdf
识别不同大小的物体是计算机视觉中的一个基本挑战,我们常用的解决方案是构造多尺度金字塔。本论文是2017年所出的,没啥多说的,直接进入主题。
FPN简介
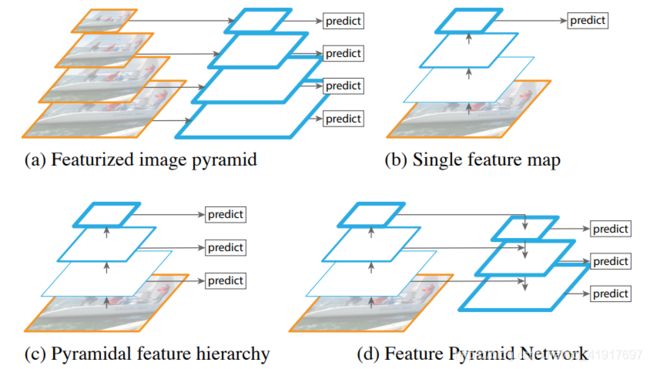
1)图a所示,整个过程是先对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测。这种方法的缺点是计算量大,需要大量的内存;优点是可以获得较好的检测精度。它通常会成为整个算法的性能瓶颈,由于这些原因,当前很少使用这种算法。
2)图b所示,利用卷积网络本身的特性,即对原始图像进行卷积和池化操作,通过这种操作我们可以获得不同尺寸的feature map。实验表明,浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助准确的检测出目标,因此可以利用最后一个卷积层上的feature map来进行预测。这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类。这种方法的优点是速度快、需要内存少。它的缺点是我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。
3)图c所示,它的设计思想就是同时利用低层特征和高层特征,分别在不同的层同时进行预测,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。它的优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。它的缺点是获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。
4)FPN架构如图d所示,首先在输入的图像上进行深度卷积,然后将深层的特征图上采样再加入浅层的特征图之中。因为越深层的特征语义信息更强,图中深蓝色的框就是有强语义信息的。除此之外,低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,融合了多层特征信息,并在不同的特征进行输出。
Faster RCNN中的FPN
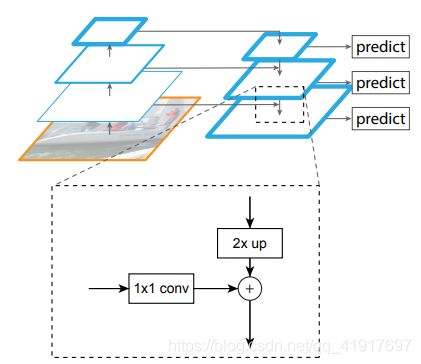
整个过程分为从下到上和从上到下:
Bottom-up pathway:
首先说几个定义,backbone ConvNet就是提取特征的主干网络,特征图尺寸通常以2为步进缩小。将输出的特征图尺寸不变的一系列卷积层称作一个stage,FPN利用的就是每个stage最后的输出。此处,参照ResNet。
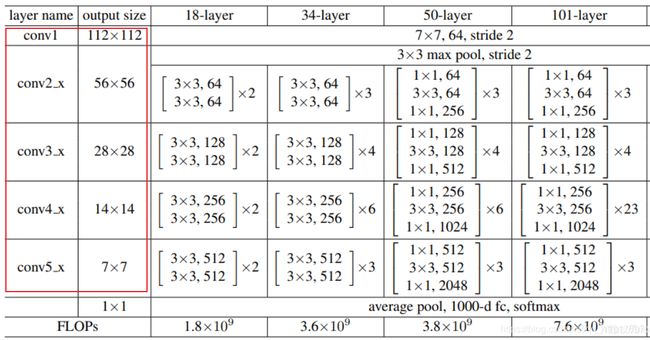
这里选用了{C2, C3, C4, C5},分别下采样了{4, 8, 16, 32}倍。
Top-down pathway and lateral connections:
高层特征图上采样采用的是最近邻值插值法(实际等同于反平均池化操作),横向连接用的1x1卷积减少通道数,最后两个特征图对应位置相加,再用3x3卷积降低混叠失真,得到{P2, P3, P4, P5}。此外,P6是在P5基础上,stride=2下采样得到的。P6只用于RPN,不在FasterRCNN部分使用。下图给个例子:
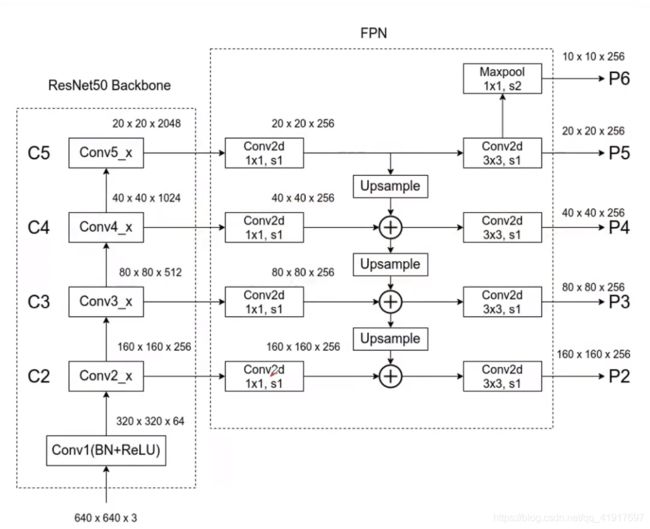
这里每个特征图的输出维度都固定为256维,也不加其他额外的非线性操作。简单作者设计的核心,模型对于许多设计选择都是健壮的。我们已经试验了更复杂的块(例如,使用多层剩余块作为连接),并观察到稍微更好的结果。设计更好的连接模块并不是本文的重点,所以我们选择了上面描述的简单设计。

{P2, P3, P4, P5, P6}对应着f {322,642,1282,2562,5122}尺度的anchor,比例仍然为三种{1:2, 1:1, 2:1},所以说特征金字塔一共有15种anchor。注意:并没有将gt_box明确地分配到金字塔的某个层次;相反,gt_box与锚相关联,锚被分配到金字塔各个层次。
至此,可以说FPN的结构已经介绍完成,大家可以把FPN看作是一个产生多层特征图的主干网络来看待。如图所示:

FPN与RPN
RPN网络结构如下:和原本的Faster RCNN一样。都是用的一样的3x3的卷积和1x1的子卷积,因为在金字塔的所有层次上,头部都密集地滑动,不用特意的去设计多尺度的sliding window。
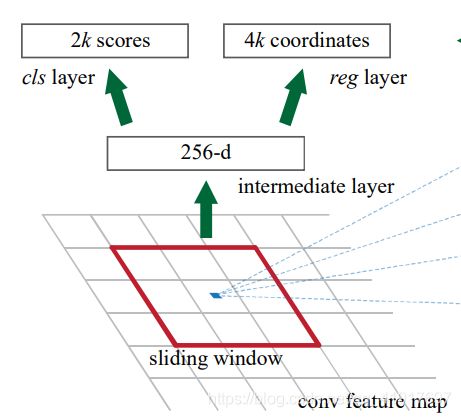
值得说明的一点是,是否需要为每一个Pk都加一个这样的网络?作者做实验发现,只用一个RPN网络就可以了,准确度基本一样。
FPN与Fast R-CNN
对RPN选择出来的ROI区域,送入到Fast R-CNN中,这里的预测头predictor heads作用于所有层级选出来的ROI。
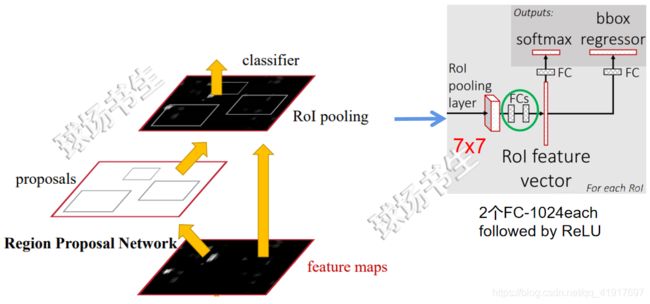
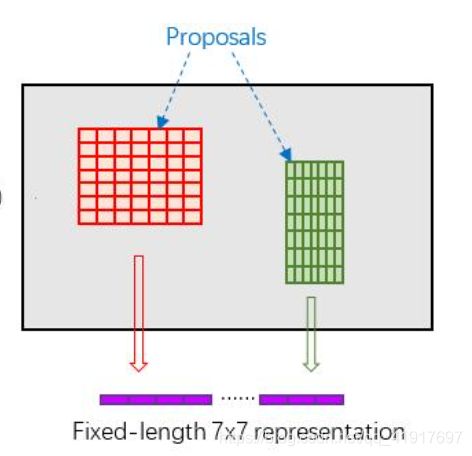
ROI切分的大小还是选择的7x7的:
值得注意的是,这里只用了一个Fast R-CNN:
{P2, P3, P4, P5, P6}都经过RPN后,在每级都得到了一些ROI,而ROI的xywh千奇百怪。RPN给了ROI的xywh,那么我们要在哪级的特征图上切取xywh区域,切取后送到后面第二阶段的fast rcnn网络呢?
按理说应该是哪一级的特征图,经过RPN产生ROI的xywh就应该去哪一层的特征图上切。但是作者给出说明,Fast R-CNN通常只是在单一尺寸的特征图上进行的,要将其与我们的FPN一起使用,我们需要为金字塔级别分配不同规模的roi。不同尺度的ROI,使用不同特征层作为ROI pooling层的输入。大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。(大尺度的ROI在低分辨率的特征图上切有利于大目标,小尺度的ROI从高分辨率特征图上切,有利于检测小目标。)计算公式如下:
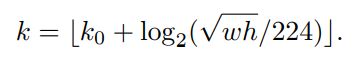
参数说明:
1)224是ImageNet预训练图的大小;
2)w和h是ROI区域的长和宽,k0是基准值(面积为224×224的roi所在的层级),设置为5,代表P5层的输出;
3)假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层;k值向下取整处理,这意味着如果RoI的尺度变小(比如224的1/2),那么它应该被映射到一个精细的分辨率水平;
4)k的计算结果只会是2345(P2–P5),即不要第6级特征图进行第二阶段的训练和测试了。
实验效果
FPN对RPN带来的影响:关心的是召回率AR
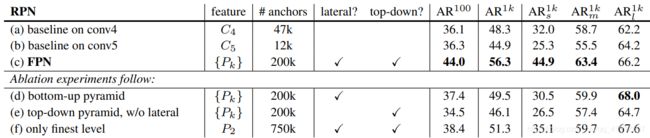
FPN对Fast R-CNN的影响:关心的是准确率AP
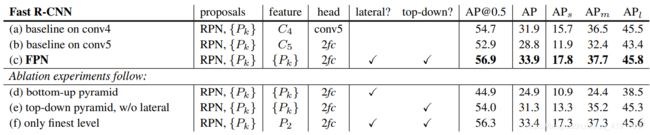
FPN对整个Faster R-CNN的影响:

上一篇:目标检测之YOLO V3