matlab amd负优化,AMD 篇三:AMD真的翻身了?—— AMD&INTEL CPU 计算性能测试
AMD 篇三:AMD真的翻身了?—— AMD&INTEL CPU 计算性能测试
2020-02-25 15:13:05
12点赞
18收藏
14评论
前言
这次主要讲一下AMD和INTEL CPU的mkl库测试,以及10980XE不降价原因的猜测。
2019年,AMD发布ZEN2以后,很多人 大呼AMD翻身了!!!每款CPU发布时,都会有专业的媒体进行测评,测评的方面无非是常见的几种:游戏帧数、Cinebench R20、Blender等渲染软件。再多一些就是生命科学方面计算和金融计算。然而,还有一类人群购买需求是科学计算,最常用的软件是MATLAB,而且通常有较强的购买能力,这类人就是高校科研人员
 。为了提高计算效率,通常会调用一些科学计算库,而最常见的是INTEL的MKL库,虽然也有其他类似的库,比如Openblas,但是尚未集成到MATLAB中。
。为了提高计算效率,通常会调用一些科学计算库,而最常见的是INTEL的MKL库,虽然也有其他类似的库,比如Openblas,但是尚未集成到MATLAB中。
所以本文对AMD和INTEL的CPU进行MKL性能测试,看一下AMD的CPU是否适合科研工作者。
放上同类测试文章作为参考,这里面是10980XE、3960X和3970X的MKL测试: 如何绕过Matlab的“弱化AMDCPU”功能-电脑讨论-Chiphell-分享与交流用户体验如何绕过 Matlab 的“弱化 AMD CPU” 功能,电脑讨论,讨论区-技术与经验的讨论 ,Chiphell - 分享与交流用户体验www.chiphell.com去看看HowtoBypassMatlab's'CrippleAMDCPU'Function-ExtremeTechIf you run Matlab on an AMD processor, you aren't getting all the performance you're entitled to. Matlab refuses to ...www.extremetech.com去看看
如何绕过Matlab的“弱化AMDCPU”功能-电脑讨论-Chiphell-分享与交流用户体验如何绕过 Matlab 的“弱化 AMD CPU” 功能,电脑讨论,讨论区-技术与经验的讨论 ,Chiphell - 分享与交流用户体验www.chiphell.com去看看HowtoBypassMatlab's'CrippleAMDCPU'Function-ExtremeTechIf you run Matlab on an AMD processor, you aren't getting all the performance you're entitled to. Matlab refuses to ...www.extremetech.com去看看
已经将测试结果放到网盘中:
MKL库介绍
MKL全称是Math Kernel Library,官方网址:Intel®MathKernelLibrary(Intel®MKL)|Intel®SoftwareIncrease performance and reduce development time with optimized math functions from Intel® Math Kernel Library.software.intel.com去看看
MKL是一种适用于多种环境的解决方案。英特尔数学内核库(英特尔MKL)以最小的努力优化代码,以供下一代英特尔处理器使用。它与您选择的编译器,语言,操作系统以及链接和线程模型兼容。特点是:
1.具有高度优化,线程化和向量化的数学函数,可最大化每个处理器系列的性能
2.使用行业标准的C和Fortran API,以与流行的BLAS,LAPACK和FFTW功能兼容-无需更改代码
3.自动为每个处理器分配优化的代码,而无需分支代码
4.提供优先支持,可将您直接连接到英特尔工程师,以获取技术问题的机密答案
5.MATLAB、Paython等一些软件可以调用INTEL开发的MKL库来提高计算效率。
支持以下几种数学运算:(参考)
1)BLAS 和 LAPACK
在英特尔处理器中部署经过高度优化的基本线性代数例程BLAS(Basic Linear Algebra Subroutines)和 线性代数包LAPACK(Linear Algebra Package) 例程,它们提供的性能改善十分显著。
2)ScaLAPACK
ScaLAPACK是一个并行计算软件包,适用于分布存储的MIMD并行机。ScaLAPACK提供若干线性代数求解功能,具有高效、可移植、可伸缩、高可靠性的特点,利用它的求解库可以开发出基于线性代数运算的并行应用程序。
ScaLAPACK 的英特尔? MKL 实施可提供显著的性能改进,远远超出标准 NETLIB 实施所能达到的程度。
3)PARDISO稀疏矩阵解算器
利用 PARDISO 直接稀疏矩阵解算器解算大型的稀疏线性方程组,该解算器获得了巴塞尔大学的授 权,是一款易于使用、具备线程安全性、高性能的内存高效型软件库。英特尔? MKL 还包含共轭梯度解算器和 FGMRES 迭代稀疏矩阵解算器。
4)快速傅立叶变换 (FFT)
充分利用带有易于使用的新型 C/Fortran 接口的多维 FFT 子程序(从 1 维至 7 维)。英特尔? MKL 支持采用相同 API 的分布式内存集群,支持将工作负载轻松地分布到大量处理器上,从而实现大幅的性能提升。此外,英特尔? MKL 还提供了一系列 C 语言例程(“wrapper”),这些例程可模拟 FFTW 2.x 和 3.0 接口,从而支持当前的 FFTW 用户将英特尔? MKL 集成到现有应用中。
5)矢量数学库(VML)
矢量数学库(Vector Math Library)借助计算密集型核心数学函数(幂函数、三角函数、指数函数、双曲函数、对数函数等)的矢量实施显著提升应用速度。
6)矢量统计库—随机数生成器(VSL)
利用矢量统计库(Vector Statistical Library)随机数生成器加速模拟,从而实现远远高于标量随机数生成器的系统性能提升。
如何开启MKL库
方法一:打开此电脑(右键)-属性-高级系统设置-环境变量-系统变量中新建。
MKL_DEBUG_CPU_TYPE = 5

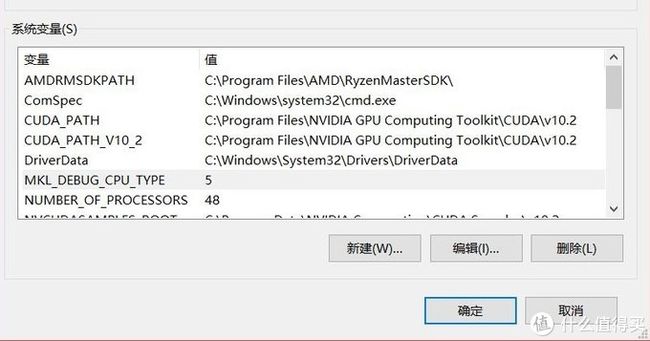
方法二:这种方法可以选择是否使用MKL。参考这篇文章,里面包含Windows和Linux开启MKL的方法。
Windows开启MKL:
1.新建记事本,并将下面代码粘贴进去,并保存关闭。
@echo offset
MKL_DEBUG_CPU_TYPE=5
matlab.exe
2.将记事本后缀.txt改为.bat。记事本的位置不会有影响。
Linux开启MKL:
打开终端,输入:
export MKL_DEBUG_CPU_TYPE=5
然后在同一终端开启MATLAB即可。
Linux永久解决方案:
echo 'export MKL_DEBUG_CPU_TYPE=5' >> ~/.profile
测试系统
测试的系统包括INTEL 8代、INTEL9代、ZEN1 TR4、ZEN2、ZEN2 TRX40:
1950X 全核心3.8GHz 内存3000
8700K 全核心4.8GHz 内存 2400
9700KF 默认频率 内存 2400
3700X全核心4.2GHz 内存2400
3900X 数据来源于网络,推测没有开启mtl
3960X 动态加速4.1GHz 内存3200
MATLAB基准测试
首先进行MATLAB基准测试。参考链接:MATLAB基准-MATLABbench-MathWorks中国ww2.mathworks.cn去看看
测试内容包括:

进行100次测试,并取最小值进行对比。结果如下:


MKL测试
测试程序和部分结果参考了这个链接
里面还有一些其他CPU的测试结果,这里就没有加入对比,有兴趣可以看一下。
直达测试程序的链接
程序生成维度分别为10, 100, 1000, 2500, 5000, 7500, 10000的随机矩阵,本次仅展示维度为10000的测试结果。
测试内容为:
N维矩阵的奇异值分解(Singular value decomposition,SVD)
N维矩阵的Cholesky分解(Cholesky factorization,Cholesky)
N维矩阵的QR分解(QR factorization,QR)
10次N维矩阵乘法(10 matrix products)
N维矩阵逆运算(Matrix inverse,Inverse)
N维矩阵的摩尔-彭若斯广义逆(Moore-Penrose pseudoinverse,Pseudo-inverse)
整体测试结果:

可以看出,开启MKL以后,AMD的CPU或多或少会有提升。提升最明显的是矩阵逆运算,提升最不明显的是奇异值分解。
各项测试结果(单位:秒)
SVD

从图中可以看出,开启MKL仅仅使AMD的CPU计算性能有一点点提高。对比3700X和8700K,以及1950X和7960X,在相同的价位上,Intel的CPU在SVD计算方面有着非常显著的优势。有趣的是,8700K超频到全核心4.8G以后,性能竟然远好于默认频率下的9700KF。同价位下,3900X的SVD性能已经略强于9900K了,虽然对3900X进行了超频。
Cholesky

对于Cholesky测试,AMD CPU开启MKL后性能分别是未开启状态时的3.69倍(3960X)、2.37倍(1950X)、2.93倍(3700X)。可以看出,ZEN2的提升效果明显高于ZEN1。但是,即使开启MKL,AMD的CPU也很难超过同级别的Intel的CPU,仅3960X的性能高于7960X。
QR

对于QR分解测试,开启MKL以后AMD的CPU性能有着显著的提升,而且能接近或者略微超过同级别Intel的CPU。
10 matrix products
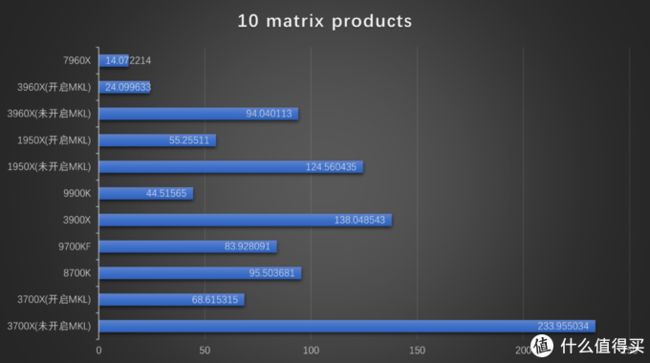
10次矩阵乘法测试结果非常有趣。3700X开启MKL后性能是未开启状态的3.4倍,而且强于8700K和9700KF。9700KF默频强于8700K 4.8G,说明在乘法计算方面9700KF进行了优化。
除了3700X强于8700K和9700KF,1950X和3960X开启MKL后虽然提升巨大,3960X开启MKL后性能是未开启时的3.94倍,1950X是2.26倍,但这两个CPU的表现依然不好。3960X和7960X相比,运算时间几乎长了1倍。在所有测试项目中,这一项是日常使用频率最高的,也是AMD和INTEL性能差异最大的。也许这就是10980XE不降价的原因。按照核心数算,7980XE的矩阵乘法性能刚好是3960X的2倍。
假设3900X开启MKL后是未开启状态的3.6倍,那么开启MKL后耗时将变成38.3秒,略强于默认频率的9900K。不仅如此,3900X还强于1950X的55秒,与3960X的24秒差距也不大!!!而3900X的价格不到3960X的二分之一。
Inverse
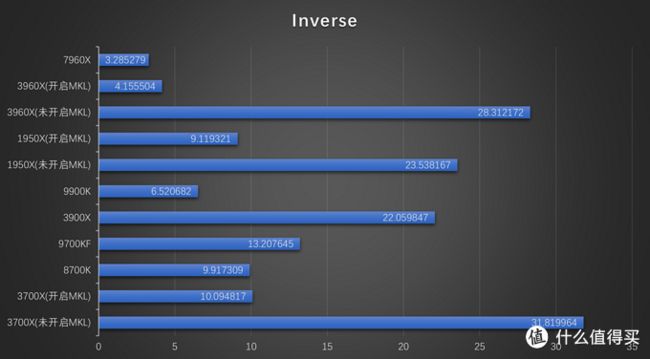
对于逆运算测试,开启MKL后AMD CPU性能有着巨大的提升,尤其是3960X,耗时只有未开启MKL时的七分之一。即使开启MKL,AMD的CPU性能仍然全面处于下风。跟矩阵乘法性能的差距相比,这个差距还可以接受。另外,在不开启MKL的情况下,3900X的性能竟然优于3960X。
Pseudo-inverse

对于Pseudo逆运算测试,AMD CPU开启MKL后有一定的提升。对比3700X和1950X以及3960X,Pseudo逆运算性能与核心数量成正比关系,所以3960X在这方面的性能是最好的,未开启MKL前就跟7960X基本相同,开启MKL后7960X的耗时是3960X的1.3倍。
总结
可以得到结论是:
1.在科学计算方面,Intel凭借MKL库仍然有着巨大的优势,并且借着这个优势保持价格不下降,甚至还上涨??
![]() 这个优势仅限于X系列CPU。而对于8700K、9700K这类常用的CPU,AMD和Intel之间的差距并不大。
这个优势仅限于X系列CPU。而对于8700K、9700K这类常用的CPU,AMD和Intel之间的差距并不大。
2.开启MKL后,AMD CPU或多或少会有提升。
3.推荐购买AMD ZEN2的CPU。ZEN1对MKL库的支持并不好,开启后性能虽然有提升,但是跟Intel CPU相比仍然有差距。到了ZEN2,开启MKL以后,性能基本能追上或者超过同价位的CPU,所以非常值得购买。对于使用MKL库的科学计算,3900X可能是目前性价比最高的CPU。
除了MKL库,Openblas库也是非常好的选择,尤其是对AMD的CPU,不存在负优化的问题。
随着AMD的市场份额增加,MATLAB应该会注重AMD CPU的优化,比如使用Openblas库代替MKL库。而在Paython的numpy中,已经集成了Openblas库。相信以后越来越多的软件会对AMD的CPU进行优化。
如果有时间后续会调试MATLAB调用Openblas库,到时候会再写一篇文章进行分享。
