2018 DeeplabV3+笔记
文章目录
- *DeepLabV3+*
- *KeyPoint*
-
- ***overview***
- ***Keywords and concepts***
- 摘要
- 引言
- 相关工作
- ***Methods***
-
- ***Encoder-Decoder with Atrous Convolution***
- ***Modifified Aligned Xception***
- 实验评估
-
- ***Decoder Design Choices***
- ***ResNet-101 as Network Backbone***
- ***Xception as Network Backbone***
- ***Improvement along Object Boundaries***
- ***Experimental Results on Cityscapes***
- 结论
- 结论
DeepLabV3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
代码地址–>tensorflow
KeyPoint
overview
- 论文有效地将编码器-解码器架构和ASPP结合起来,同时使用以ImageNet、JFT数据集进行预训练的Xception(进行了一些细微的调整)和ResNet101作为主干网络在ImageNet、PASCAL VOC 2012、CityScape、MS-COCO等数据集上进行了实验评估。实验表明DeeplabV3 达到了先进水平,在某些数据集上甚至是第一名。
- 论文将深度可分离卷积应用于空洞卷积,并称之为***Atrous Separable Convolution***,即空洞可分离卷积,显著降低了模型的计算复杂度,同时近似保持了模型的性能。
Keywords and concepts
Encoder-Decoder:
Atrous Separable Convolution:*在深度可分离卷积的Tensorflow[72]实现中,空洞卷积被支持在深度卷积(即空间卷积)中,在这项工作中,我们将所得到的卷积称为空洞可分离卷积*
*fields-of-view:*视场
***depthwise separable convolution:***深度可分离卷积,将标准卷积分解成深度卷积(depthwise convolution),然后是逐点卷积(pointwise convolution)(即1×1卷积),大大降低了计算复杂度。
ASPP: atrous spatial pyramid pooling(空洞空间金字塔池化)
***atrous convolution:*空洞卷积允许我们显式地控制由深度卷积神经网络计算的特征的分辨率,并调整滤波器的视场(field-of-view),以捕获多尺度信息。标准卷积是空洞卷积率r=1的一种特殊情况。
output stride:本文中的输出步长为输入图像空间分辨率与最终输出分辨率(在全局池化或完全连接层之前)的比值*(ratio)*。
摘要
空间金字塔池模块或编码器-解码器结构用于深度神经网络进行语义分割任务。前一种网络能够通过滤波器(filter),或者是多个卷积扩展率和多个有效视场的池化操作,来探测输入特征来编码多尺度上下文信息,而后一种网络可以通过逐步恢复空间信息来捕获更清晰的对象边界。
在这项工作中,我们建议结合这两种方法的优点。具体来说,我们提出的模型**DeepLabv3+*通过添加了一个简单而有效的解码器模块,扩展了DeepLabv3来细化分割结果,特别是沿着对象边界。我们进一步探索了Xception模型,并将深度可分离卷积应用于ASPP和解码器模块,从而得到更快更强的编码-解码器网络。我们在pascal VOC 2012和城市景观上证明了该数据集的有效性,在没有任何后处理( post-processing)*的情况下,实现了89.0%和82.1%的测试集性能。
引言
语义分割的目标是为图像[1,2,3,4,5]中的每个像素分配语义标签,这是计算机视觉中的基本主题之一。基于全卷积神经网络[8,11]的深度卷积神经网络[6,7,8,9,10]比在基准任务上比依赖手工特性*(hand-crafted)*[12,13,14,15,16,17]的系统有显著的改进。
在这项工作中,我们考虑了两种使用空间金字塔池模块[18,19,20]或编码器-解码器结构[21,22]进行语义分割的神经网络,前者通过汇集不同分辨率的特征来捕获丰富的上下文信息,而后者能够获得清晰的对象边界。
为了在多个尺度上捕获上下文信息,DeepLabv3[23]应用了几种不同扩张率的并行空洞卷积(ASPP),
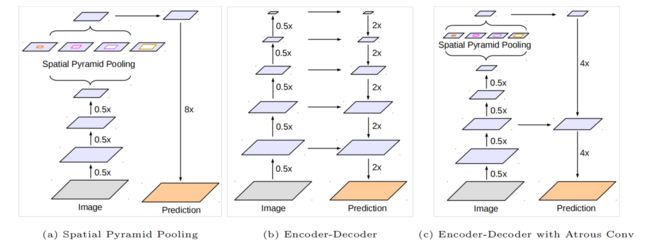
注:图 1.我们改进了DeepLabv3,它采用了空间金字塔池化模块(a),具有编码器-解码器结构(b)。所提出的模型DeepLabv3+包含了来自编码器模块的丰富语义信息,而详细的对象边界则由简单而有效的解码器模块恢复。编码器模块允许我们通过应用空洞卷积以任意分辨率提取特征。
而PSPNet[24]则在不同的网格尺度(grid scales)上执行池化操作。尽管在最后一个特征图中编码了丰富的语义信息,但由于网络主干内的跨步操作的池化或卷积,导致与对象边界相关的详细信息丢失。这可以通过应用空洞卷积来提取更密集的特征图来缓解。
然而,考虑到最先进的神经网络[7,9,10,25,26]的设计和有限的GPU内存,提取比输入分辨率小8倍甚至4倍的输出特征映射在计算上是禁止的。以ResNet-101[25]为例,当应用空洞卷积提取比输入分辨率小16倍的输出特征时,必须对最后3个残余块(9层)内的特征进行扩展。更糟糕的是,如果需要比输入值小8倍的输出特征,26个残余块(78层!)将会受到影响。因此,如果为这类模型提取更密集的输出特征,则是计算密集型的。另一方面,编码器-解码器模型[21,22]可以在编码器路径上进行更快的计算(因为没有特征被扩张),并在解码器路径上逐渐恢复尖锐的对象边界。为了结合这两种方法的优点,我们建议通过合并多尺度上下文信息来丰富编码器-解码器网络中的编码器模块。
特别是,我们提出的模型,称为DeepLabv3+,扩展自DeepLabv3[23]。通过添加一个简单而有效的解码器模块来恢复对象的边缘,如图所示1。 丰富的语义信息被编码在DeepLabv3的输出中,通过空洞卷积允许人们控制编码器特征的密度,这取决于计算资源的预算。此外,解码器模块允许详细的对象边界恢复。
在深度可分离卷积[27,28,26,29,30]最近成功的激励下,我们也探索了这一操作,并通过适应类似于[31]的Xception模型[26],显示了在处理语义分割任务时速度和精度方面的改进,并将空洞可分离卷积应用于ASPP和解码器模块。最后,我们证明了该模型在pascal VOC 2012和城市景观数据上的有效性,并在没有任何后处理的情况下获得了89.0%和82.1%的测试集性能,建立了一个新的最先进的水平
综上所述,我们的贡献包括:
- 我们提出了一种新的编码器-解码器结构,它采用DeepLabv3作为一个强大的编码器模块和一个简单而有效的解码器模块。
- 在我们的结构中,可以通过空洞卷积任意控制提取的编码器特征的分辨率,这对于现有的编码器-解码器模型是不可能的。
- 我们将Xception模型用于分割任务,并将深度可分离卷积应用于ASPP模块和解码器模块,从而产生更快更强的编码器-解码器网络。
- 我们提出的模型在 PASCAL VOC2012和城市景观数据集上获得了一种新的最先进的性能。我们还提供了对设计选择和模型变体的详细分析。
- 我们在https://github.com/tensorflow/models/tree/master/研究/平台上公开基于Tensorflow的模型实现。
相关工作
基于全卷积网络(FCNs)[8,11]的模型在几个分割基准[1,2,3,4,5]上有了显著的改进。有几个被提出的模型变体利用上下文信息用于分割任务[12,13,14,15,16,17,32,33],包括那些使用多尺度输入(即图像金字塔)[34,35,36,37,38,39]或那些采用概率图形模型(如使用有效推理算法[41]的DenseCRF[40])[42,43,44,37,45,46,47,48,49,50,51,39]。在本工作中,我们主要讨论了使用空间金字塔池化和编码器-解码器结构的模型。
空间金字塔池化:模型,如PSPNet[24]或DeepLab[39,23],在多个网格尺度上执行空间金字塔池[18,19](包括图像级别的池化[52]),或应用几种不同扩张率的并行卷积(称为空间空间金字塔池,或ASPP)。这些模型通过利用多尺度信息,在多个分割基准上显示出了良好的结果。
编码器-解码器:编码器-解码器网络已成功应用于许多计算机视觉任务,包括人体姿态估计[53]、目标检测[54,55,56]和语义分割[11,57,21,22,58,59,60,61,62,63,64]。通常,编码器-解码器网络包含
1)包含一个逐渐减少特征map并捕获更高语义信息的编码器模块
2)包含一个逐渐恢复空间信息的解码器模块。在此基础上,我们建议使用DeepLabv3[23]作为编码器模块,并添加一个简单而有效的解码器模块,以获得更清晰的分割。
深度可分离卷积:深度可分离卷积[27,28]或组卷积*(group convolution)*[7,65],这是一个强大的操作,可以降低计算成本和参数的数量,同时保持相似的(或稍好的)性能。这种操作已经被许多神经网络设计[66,67,26,29,30,31,68]所采用。特别是,我们探索了Xception模型[26],类似于[31]的COCO 2017检测挑战提交,并在语义分割任务的准确性和速度方面都有所提高。
Methods
在本节中,我们将简要介绍空洞卷积[69,70,8,71,42]和深度可分离卷积[27,28,67,26,29]。然后,我们回顾了用作编码器输出模块的DeepLabv3[23],然后讨论了附加到编码器输出上的建议的解码器模块。我们还提出了一个改进的Xception模型[26,31],它以更快的计算速度进一步提高了性能。
Encoder-Decoder with Atrous Convolution
**空洞卷积:**空洞卷积是一个强大的工具,允许我们显式地控制由深度卷积神经网络计算的特征的分辨率,并调整滤波器的视场,以捕获多尺度信息,是标准卷积操作的推广。在二维信号的情况下,对于输出特征映射y上的每个位置i和卷积核w,在输入特征图x上应用空洞卷积,如下所示:
y [ i ] = ∑ k x [ i + r ⋅ k ] w [ k ] \boldsymbol{y}[\boldsymbol{i}]=\sum_{\boldsymbol{k}} \boldsymbol{x}[\boldsymbol{i}+r \cdot \boldsymbol{k}] \boldsymbol{w}[\boldsymbol{k}] y[i]=k∑x[i+r⋅k]w[k]
其中空洞卷积率(atrous rate,也叫扩张率 dilation rate)r决定了我们对输入信号进行采样的步幅。有关更多细节,我们请参考感兴趣的读者至[39]。注意,标准卷积是空洞卷积率r=1的一种特殊情况。通过更改空洞卷积率值来自适应地修改卷积核的视场。
深度可分离卷积:深度可分离卷积,将标准卷积分解成深度卷积,然后是逐点卷积(即1×1卷积),大大降低了计算复杂度。具体来说,深度卷积对每个输入通道独立地执行空间卷积,而使用逐点卷积来结合深度卷积的输出。在深度可分离卷积的Tensorflow[72]实现中,空洞卷积被支持在深度卷积(即空间卷积)中,如图所示3。 在这项工作中,我们将所得到的卷积称为空洞可分离卷积,并发现空洞可分离卷积显著降低了所提模型的计算复杂度,同时保持了相似(或更好的)性能。
注: 图 3.3×3深度可分离卷积将标准卷积分解为(a)深度卷积(对每个输入通道应用一个卷积核)和(b)逐点卷积(组合跨通道深度卷积的输出)。在这项工作中,我们探索了空洞可分离卷积,其中空洞卷积采用深度卷积,如图©所示,速率=2。
DeepLabv3作为编码器:DeepLabv3[23]采用空洞卷积[69,70,8,71]提取深度卷积神经网络任意分辨率计算的特征。在这里,我们将输出步幅表示为输入图像空间分辨率与最终输出分辨率(在全局池化或完全连接层之前)的比值。对于图像分类任务,最终特征图的空间分辨率通常比输入图像分辨率小32倍,从而oustride=32。对于语义分割的任务,通过删除最后一个(或两个)块中的striding,可以采用stride=16(或8)进行更密集的特征提取。(例如,对于outstride=8分别应用rate=2和rate=4)来进行更密集的特征提取。此外,DeepLabv3增强了ASPP模块,该模块通过应用不同空洞卷积率和图像级别特征的空洞卷积来探测多个尺度的卷积特征。我们在原始 DeepLabv3 中使用 logits 之前的最后一个特征图作为我们提出的编码器-解码器结构中的编码器输出。注意,编码器输出特征图包含256个通道和丰富的语义信息。此外,根据计算预算,可以通过应用空洞卷积提取任意分辨率的特征。
提出的解码器:DeepLabv3的编码器特征通常用output stride=16计算。在[23]的工作中,特征被双线性上采样了 16 倍,这可以被认为是一个简单的解码器模块。然而,这个朴素的解码器模块可能无法成功地恢复对象分割的细节。因此,我们提出了一个简单而有效的解码器模块,如图2所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eI5KlV7h-1636274576530)(https://raw.githubusercontent.com/Quincy756/picutres/main/img/papers/Encoder-Decoder/image-20211107111715279.png)]
注: 图 2.我们提出的DeepLabv3+通过采用编码器-解码器结构扩展了DeepLabv3。编码器模块通过在多尺度上应用空洞卷积对多尺度上下文信息进行编码,而简单有效的解码器模块沿对象边界进行分割细化。
编码器特征首先提前上采样4倍,然后与网络主干中具有相同空间分辨率的相应低级特征[73]连接(例如,在ResNet-101[25]中跨越Conv2)。我们对低级特征应用另一个1×1卷积来减少通道的数量,因为相应的低级特征通常包含大量的通道(例如,256或512),这可能超过丰富的编码器特征的重要性(在我们的模型中只有256个通道),并使训练更加困难。在连接之后,我们应用一些3×3卷积来细化特征,然后是另一个简单的双线性上采样4倍。我们将在第二节中展示。从图 4 可以看出,对编码器模块使用输出步幅 = 16 可以在速度和精度之间取得最佳平衡。当对编码器模块使用output stride = 8 时,性能略有提高,但会增加计算复杂度。
Modifified Aligned Xception
Xception模型[26]在ImageNet[74]上快速计算显示出了很好的图像分类结果。最近,MSRA团队[31]修改了Xception模型(称为Aligned Xception),并进一步推动了对象检测任务中的性能。基于这些发现,我们朝着同样的方向将 Xception应用于语义图像分割任务。特别是,我们在MSRA的修改之上做了更多的改变,即
(1)与[31]中相同的更深的Xception,除了我们不修改入口流网络结构*( the entry flflow network structure)*以实现快速计算和内存效率
(2)所有最大池化操作被深度可分离卷积取代,这使我们能够应用空洞可分离卷积在任意分辨率下提取特征图(另一种选择是将空洞分离算法扩展到最大池操作)
(3)在3×3的深度卷积之后,添加额外的BN[75]和ReLU激活,类似于MobileNet的设计[29]。详见图4
注: 图 4.修改后的Xception
实验评估
我们使用ImageNet-1k[74]预训练的ResNet-101[25]或修改aligned Xception[26,31]通过空洞卷积提取密集的特征图。我们的实现是建立在Tensorflow[72]上,并公开提供。
该模型在pascal VOC 2012语义分割基准[1]上进行了评估,该基准[1]包含20个前景对象类和一个背景类。原始数据集包含1464(训练集)、1449(验证集)和1456(测试集)像素级的注释图像。我们通过[76]提供的额外注释来增加数据集,从而得到10,582张(图像增强)训练图像。性能是用21个类的mIOU来衡量的。
我们遵循与[23]相同的训练流程,感兴趣的读者请参考[23]。简而言之,我们采用相同的学习率方案(即“poly”策略[52]和相同的初始学习速率0.007),裁剪尺寸大小为513×513,输出步幅=16时微调***(fine-tuning)***BN参数[75],训练中随机规模数据增强。请注意,我们还在所提出的解码器模块中包含了批处理归一化参数。我们提出的模型是端到端训练的,而没有对每个组件进行分段预训练。
Decoder Design Choices
我们将“DeepLabv3特征图”定义为由DeepLabv3计算的最后一个特征图(即包含ASPP特征和图像级特征的特征),并将[k×k,f]定义为具有卷积核尺寸k×k和f个卷积核的卷积操作。当使用 输出步幅=16时,基于ResNet-101的Deeplabv1[23]在训练和评估过程中对 logits 进行上采样16倍。这种简单的双线性上采样可以被认为是一种简单的解码器设计,在pascal VOC 2012 验证集上获得了77.21%[23]的性能,比在训练期间不使用这个简单的解码器(即在训练期间降采样GT好1.2%)。为了改进这个简单的基线,我们提出的模型“DeepLabv3+”将解码器模块添加到编码器输出之上,如图2所示。 在解码器模块中,我们考虑三个不同的设计选择,即
(1)1×1卷积用于减少编码器模块的通道,(2)3×3卷积用于获得更清晰的分割结果(3)应该使用哪些编码器的低级特性。
为了评估解码器模块中1×1卷积的影响,我们使用了[3×3,256]和来自ResNet-101网络主干网的Conv2特征,即res2x残差块中的最后一个特征图(具体来说,我们在striding之前使用特征图)。如表1中所示。将低级特征图的通道从编码器模块减少到48或32,可以获得更好的性能。因此,我们采用[1×1,48]来减少通道。
注:表1。PASCAL VOC 2012 验证集。解码器1×1卷积用于减少来自编码器模块的低级特征图通道的效果。我们使用[3×3,256]和Conv2来修复了解码器结构中的其他组件。
然后,我们为解码器模块设计了3×3的卷积结构,并在表2中报告了这些发现。
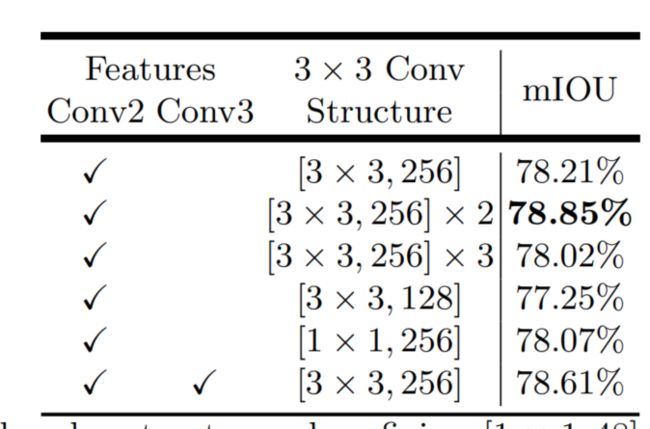
注:表2 解码器结构固定为[1×1,48],以减少编码器特征通道时的影响。我们发现使用Conv2(striding之前)特征图和两个额外的[3×3,256]操作是最有效的。在 VOC 2012 val集上的性能。
我们发现,在将Conv2特征图(striding 之前)与DeepLabv3特征图连接后,使用256个卷积核的两个3×3卷积比简单使用一个或3个的卷积更有效。**将卷积核的数量从256更改为128,或将核大小从3×3更改为1×1会降低性能。**我们还实验了在解码器模块中同时利用Conv2和Conv3特征图的情况。在这种情况下,解码器特征图逐渐被2上采样,首先与Conv3连接,然后与Conv2连接,每个操作都将通过[3×3, 256]操作进行细化。那么整个解码过程就类似于U-Net/SegNet设计的[21,22]。然而,我们还没有观察到显著的改善。因此,最后,我们采用了非常简单而有效的解码器模块:DeepLabv3特征图的和通道减少的Conv2特征图的连接通过两个[3×3,256]操作进行细化。请注意,我们提出的DeepLabv3+模型具有output stride=4。考虑到有限的GPU,我们不进一步追求更密集的输出特征图(output stride<4)
ResNet-101 as Network Backbone
为了比较模型变体的准确性和速度,我们在表3中报告了mIOU和Multiply-Adds。在提出的DeepLabv3+模型中使用ResNet-101[25]作为网络骨干。
注: 表3。使用ResNet-101对Pascal VOC 2012 验证集的推理策略。train OS:训练期间使用的输出步幅。eval OS:在评估期间使用的输出步幅。Decoder:采用建议的解码器结构。MS:评估过程中的多尺度输入。Flip:添加左右翻转的输入。
由于空洞卷积,在训练和评估期间,我们能够使用一个单一模型来获得不同分辨率下的特征。
**Baseline:**表3中的第一部分包含了[23]的结果,表明在评估过程中提取更密集的特征图(即eval output stride =8),并采用多尺度输入可以提高性能。此外,添加左翻转输入使计算复杂度增加一倍,性能略有提高。
Adding decoder: 表3中的第二部分包含了在采用所提出的解码器结构时的结果。当使用eval输出步幅=16或8时,性能分别从77.21%提高到78.85%或78.51%提高到79.35%,代价是大约20B个额外的计算开销。当使用多尺度和左右翻转输入时,性能进一步提高。
Coarser feature maps:我们也尝试了使用训练输出步幅=32(即在训练期间完全没有任何空洞卷积)的情况进行快速计算。如表3中的第三部分所示。添加解码器可以提高约2%,而只需要74.20B的乘法添加。然而,如果我们使用训练输出步幅=16和不同的eval输出步幅值,其性能总是要低约1%到1.5%。因此,根据复杂性预算,我们更喜欢在训练或评估期间使用输出步幅=16或8。
Xception as Network Backbone
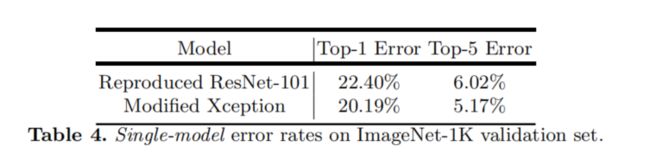
我们进一步使用更强大的Xception[26]作为网络主干。在[31]之后,我们将做一些更多的更改,如3.2节中所述。**ImageNet预训练:**所提出的Xception在ImageNet-1k数据集[74]上进行预训练,在[26]中使用类似的训练流程。
| 训练参数(Nesterov momentum ) | ImageNet |
|---|---|
| momentum | 0.9 |
| initial lr | 5 × 1 0 − 2 5\times 10^{-2} 5×10−2 |
| rate decay | 0.94 per 2 epoches |
| weight decay | 4 × 1 0 − 5 4\times10^{-5} 4×10−5 |
| batch size | 32 |
| image size | 299×299 |
| train method | asynchronous training(异步训练) |
| GPUs | 50 |
- 我们并没有非常严格地调整超参数,因为其目标是在ImageNet上对模型进行预训练以进行语义分割。
我们在表4中报告了验证集中的单模型错误率。基线在相同的训练方案下复制了ResNet-101[25]。我们观察到,在修改的Xception中,每次3×3深度卷积后,当不添加额外的批归一化和ReLU时,Top1和Top5的精度分别下降了0.75%和0.29%。
利用语义分割的网络主干作为语义分割的结果报告在表5
注: 表5。使用修改后的Xception时对 pascal VOC 2012 验证集时的推理策略。train OS:训练期间使用的输出步幅。eval OS:在评估期间使用的输出步幅。Decoder:采用建议的解码器结构。
MS:评估过程中的多尺度输入。Flip:添加左右翻转的输入。SC: 对ASPP模块和解码器模块都采用了深度可分离的卷积。COCO:经过MS-COCO预先训练的模型。JFT:在JFT上预先训练过的模型。
baseline:我们首先在表5第一部分报告没有使用提出的解码器。这表明,当训练输出步幅=评估的输出步幅=16时,使用Xception作为网络主干比使用ResNet-101的情况下,性能提高了约2%。**通过使用评估输出步幅=8、推理期间的多尺度输入和添加左右翻转输入,也可以获得进一步的改进。**请注意,我们没有使用多网格方法[77,78,23],我们发现它并没有提高性能。
Adding decoder:如表5第二部分所示。当对所有不同的推理策略使用评估输出步幅=16时,添加解码器可提高0.8%的性能提升。当使用评估输出步幅=8时,改进变小了。
Using depthwise separable convolution:基于深度可分离卷积的有效计算,我们进一步将其应用于ASPP和解码器模块中,如表5第三部分所示。Multiply-Adds 的计算复杂度显著降低了33%~41%,同时得到了相似的mIOU性能。
Pretraining on COCO:为了与其他最先进的模型相比,我们进一步在MS-COCO数据集[79]上对我们提出的DeepLabv3+模型进行了预训练,它对所有不同的推理策略产生了约2%的额外改进。
Pretraining on JFT: 与[23]类似,我们还使用了所提出的Xception模型,该模型已经在ImageNet-1k[74]和JFT-300M数据集[80,26,81]上进行了预训练,这带来了额外的0.8%到1%的改进。
测试集结果:由于在基准评估中没有考虑计算复杂度,因此我们选择了最佳的性能模型,并使用输出步幅=8,冻结的批归一化参数*(frozen batch normalization parameters)*对其进行训练。最后,我们的“DeepLabv3+”在没有和使用JFT数据集预训练的情况下分别达到了87.8%和89.0%的性能。
Qualitative results:我们在图中提供了我们的最佳模型的可视化结果。 如图6所示,我们的模型能够很好地分割对象,而不需要进行任何后处理。
Failure mode: 如图6最后一行所示。我们的模型在分割(a) 沙发和椅子、(b) 严重遮挡的物体 和 ©视野罕见的物体方面存在困难。
Improvement along Object Boundaries
在本小节中,我们使用trimap实验[14,40,39]来评估分割精度,以量化所提出的解码器模块在对象边界附近的精度**。具体来说,我们在验证集上的“void”标签注释上应用形态学扩展*(morphological dilation),这通常发生在对象边界周围。然后,我们计算那些在“void”标签的扩展带(the dilated band)*(称为trimap)内的像素的mIOU。**如图所示5(a),与朴素的双线性上采样相比,对 ResNet-101 [25] 和 Xception [26] 网络骨干采用提出的解码器提高了性能。 当扩张带较窄时,改善更为显着。我们观察到ResNet-101和Xception的mIOU分别提高了4.8%和5.4%,最小的Trimap宽度如图所示。我们还可视化了使用图中所提出的解码器的效果。5(b)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BNaqdAV8-1636274576534)(https://raw.githubusercontent.com/Quincy756/picutres/main/img/papers/Encoder-Decoder/image-20211107150214874.png)]
Experimental Results on Cityscapes
在本节中,我们在城市景观数据集[3]上实验DeepLabv3+,这是一个大规模数据集,包含5000张图像的高质量像素级注释(分别为2975 ,500和1525张用于训练、验证和测试集)和大约20000张粗糙注释的图像。如表7(a)所示,使用所提出的Xception模型作为网络主干(记为X-65),位于DeepLabv3[23]之上,其中包括ASPP模块和图像级特征[52],在验证集上达到了77.33%的性能。
注: 表7。(a)DeepLabv3+。(b)城市景观测试集中的DeepLabv3+。Coarse:同时使用train extra集(Coarse annotations)。此表中只列出了几个顶级模型。
添加所提出的解码器模块,性能显著提高到78.79%(提高1.46%)。我们注意到,去除增强图像级特征 ***(augmented image-level feature)***将性能提高到79.14%,表明在DeepLab模型中,图像级特征对PASCAL VOC 2012 数据集更有效。*我们还发现,在城市景观数据集上,在Xception[26]的入口流(entry flow)*中增加更多的层是有效的,就像[31]在对象检测任务中所做的一样。**所得到的模型构建在更深的网络主干之上(在表中表示为X-71),在验证集上获得了79.55%的最佳性能。在val集上找到最佳的模型变体后,我们进一步微调了粗注释上的模型,以便域其他最先进的模型竞争。如表7(b)所示,我们提出的DeepLabv3+在测试集上获得了82.1%的性能,在城市景观上创造了一个新的最先进的性能。
结论
我们提出的模型“DeepLabv3+”采用了编码器-解码器结构,其中使用DeepLabv3来编码丰富的上下文信息,并采用了一个简单而有效的解码器模块来恢复对象边界。还可以根据可用的计算资源,应用空洞卷积以任意分辨率提取编码器特征。我们还探索了Xception模型和深度可分离卷积,使提出的模型更快更强。最后,我们的实验结果表明,该模型在PASCAL VOC 2012和城市景观数据集上设置了一个新的最先进的性能。
造了一个新的最先进的性能。
结论
我们提出的模型“DeepLabv3+”采用了编码器-解码器结构,其中使用DeepLabv3来编码丰富的上下文信息,并采用了一个简单而有效的解码器模块来恢复对象边界。还可以根据可用的计算资源,应用空洞卷积以任意分辨率提取编码器特征。我们还探索了Xception模型和深度可分离卷积,使提出的模型更快更强。最后,我们的实验结果表明,该模型在PASCAL VOC 2012和城市景观数据集上设置了一个新的最先进的性能。